#大数据之电商推荐系统#
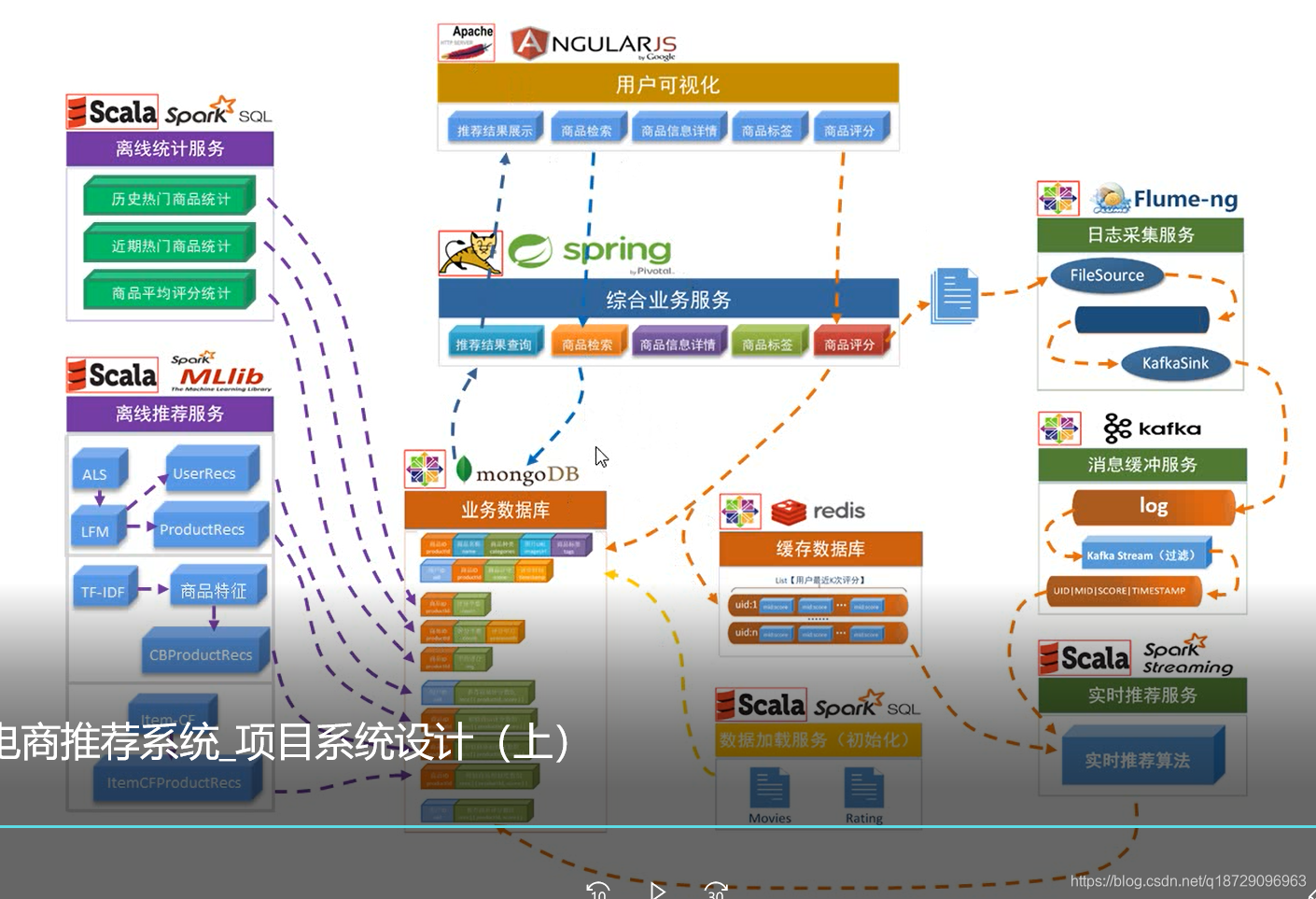
项目系统架构

数据整理
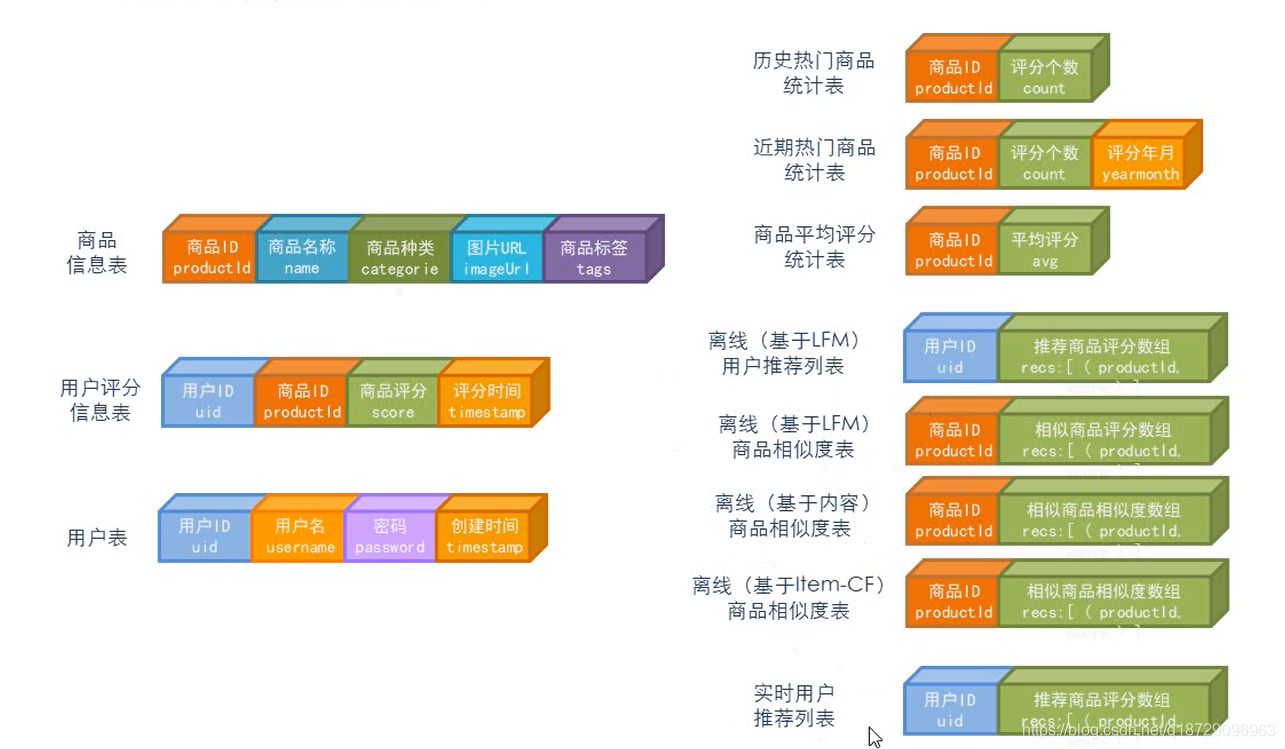
- 商品数据
| 商品ID | 商品名称 | 商品种类 | 商品图片URL | 商品标签 |
|---|---|---|---|---|
| productId | name | categories | imageUrl | tags |
- 评分数据
| 用户ID | 商品ID | 商品评分 | 评分时间 |
|---|---|---|---|
| uid | productId | score | timestamp |
表结构设计
离线统计分析
-
历史热门商品推荐 — 历史评分次数最多的商品
SQL: select product_id, count(product_id) as count from ratings group by product_id order by count desc 存储表:rate_more_product 字段:product_id rate_count -
近期热门商品 — 统计近一个月内 用户评分次数较多的商品
原则: 先创建一个UDF 将评分时间转换为yyyyMM形式的 SimpleDateFormat 时间格式化 然后对时间进行分组统计 存储表:rate_more_recently_product 字段:product_id rate_count yearmonth -
商品平均评分统计
select product_id,avg(score) as avg_score from ratings group by product_idorder by avg_score desc 存储表:rate_avg_product 字段: product_id avg_score
离线个性化推荐ALS
1. 使用ALS模型对评分数据进行训练
val model = ALS.train(data, rank, iterations, lambda)
搞出最优模型
2. 用户userRDD 与 商品productRDD 做笛卡尔积 求出 userId,productId的RDD
3. model.predict() 预测出一个评分矩阵
4. 以userId groupByKey 以 score 排序后 取TopN
注: 此处附加求出 商品的相似度矩阵
1. model.productFeatures 求出商品的特征向量矩阵
2. 笛卡儿积求出II矩阵 求余玄相似度
3. 过滤出相似度大于0.6的 进行groupByKey
实时推荐
特点:
1. 计算速度快
2. 预测结果可以不是特别精确
3. 预先算出商品相似度,有预先准备好的预测模型
原理:
1. 用户最近一段时间的口味应该是相似的
误区:
1. 评分了一个物品 即做相似推荐 --- 单个物品不能反映该用户的喜好
2. 做了差评 --- 推荐毫无意义
正确姿势:
拿出最近一段时间的用户评分数据 综合考虑评分分值和相似度
算法设计:
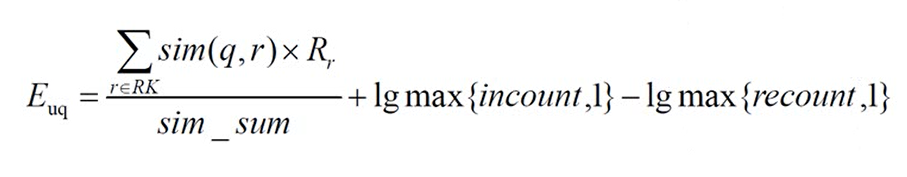
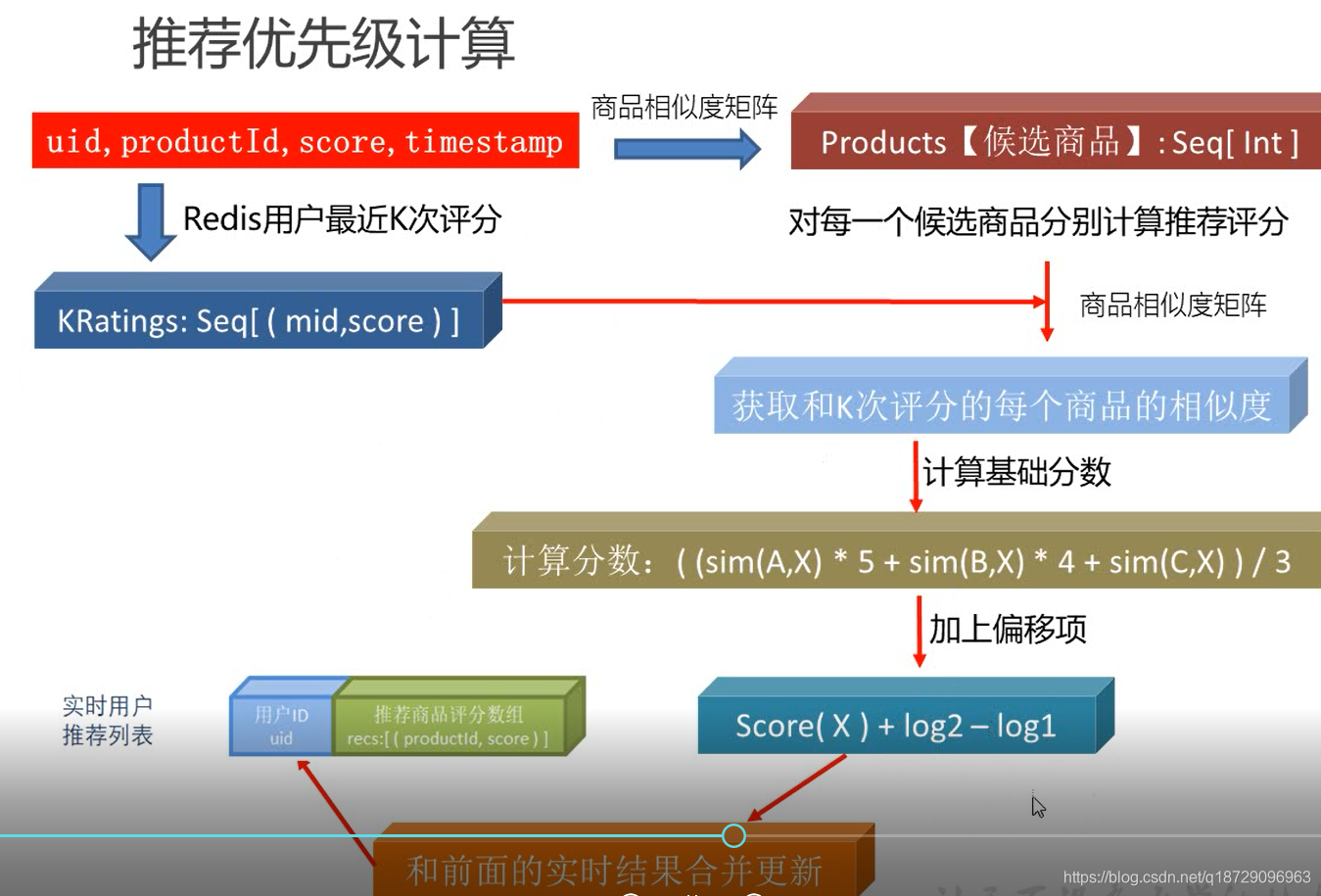
举例:用户最近的K次评分数据为
| 用户ID | 商品ID | 评分 |
|---|---|---|
| u1 | A | 5 |
| u1 | B | 4 |
| u1 | C | 4 |
| u1 | D | 2 |
对于商品X的推荐优先级得分公式:
最终得分 = (sim(X,A) * 5 + sim(X,B) * 4 + sim(X,C) * 4 + sim(X,D) * 2) / 4 + lgmax{incount,1} - lgmax{recount,1}
其中,incount为K次评分中大于3分的次数
recount为K次评分中小于3分的次数
注:此处即为 高分多 加奖励 低分多 做惩罚
其它形式的离线推荐
1. 内容推荐 TF-IDF
商品Tags 分词得到特征向量 进行相似度 求解
注: 喜欢了该物品的用户 应该也喜欢 下面这些
您有可能也喜欢下面这些物品
注: 一般在 商品详情页 商品购买页 做推荐
2. 被相似的人喜欢的物品推荐
即 喜欢的人重合度越高 相似度越高
“同现相似度”
同时购买了 两个物品的 的人 的个数
除以
购买两个物品的总人数的
