1.引导
1.Robots协议
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。该协议是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守这项协议。
2.爬虫的流程
流程图

(1)获取网页
获取网页就是给一个网址发送请求,该网址会返回整个网页的数据
常用技术
获取网页的基础技术:requests、urllib和selenium
获取网页的进阶技术:多进程多线程抓取(8)、登录抓取、突破IP封禁和使用服务器抓取
(2)解析网页(提取数据)
解析网页就是从获取的整个网页的数据中提取想要的数据
常用技术
解析网页的基础技术:re正则表达式、BeautifulSoup和lxml
解析网页的进阶技术:解决中文乱码
(3)存储数据
存储数据也很容易理解,就是把数据存储下来。我们可以存储在csv中,也可以存储在数据库中
常用技术
存储数据的基础技术:存入txt文件和存入csv文件
存储数据的进阶技术:存入MySQL数据库和MongoDB数据库
2.环境安装
(1)Anaconda
(2)pycharm
3.入门级案例
[学习HTML的网站]http://www.w3school.com.cn/html/index.asp
如此在浏览器上面查找我们想要的元素
第一步:打开浏览器,跳转到指定的网页,然后点击鼠标右键
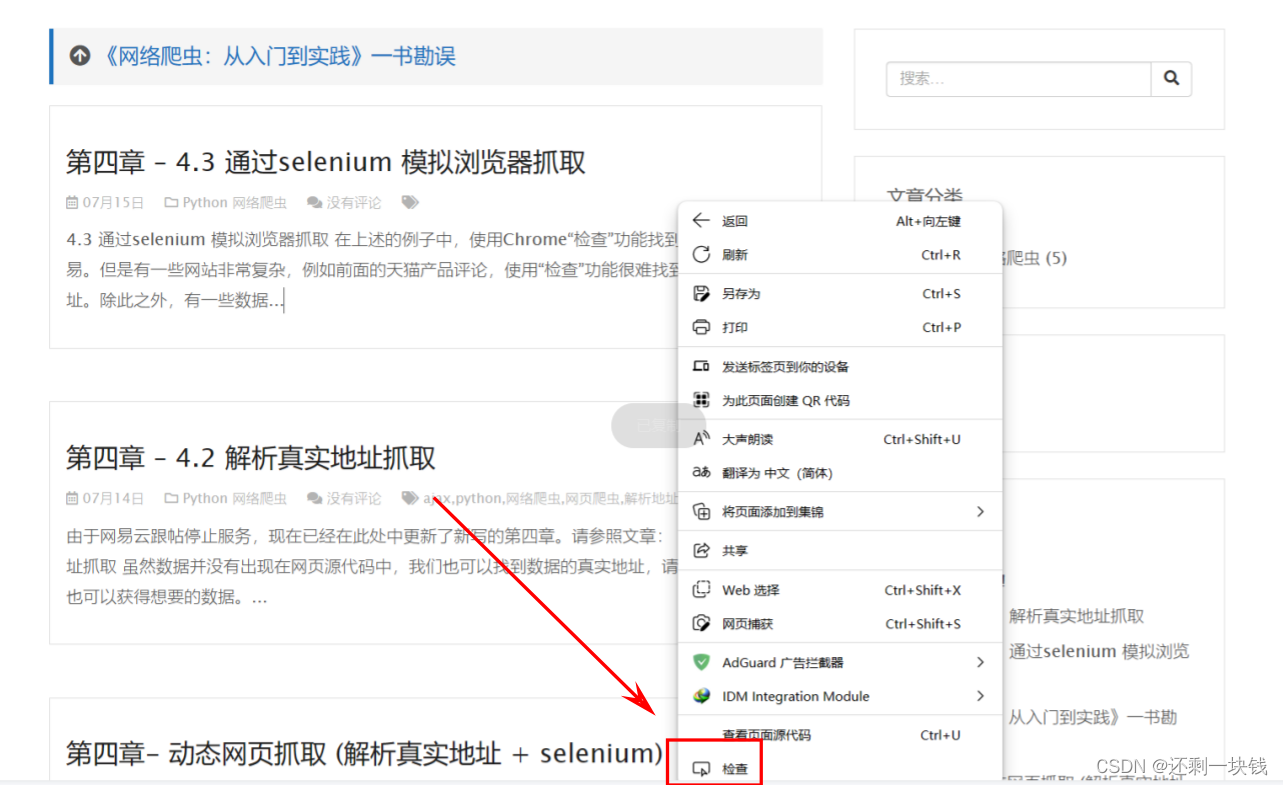
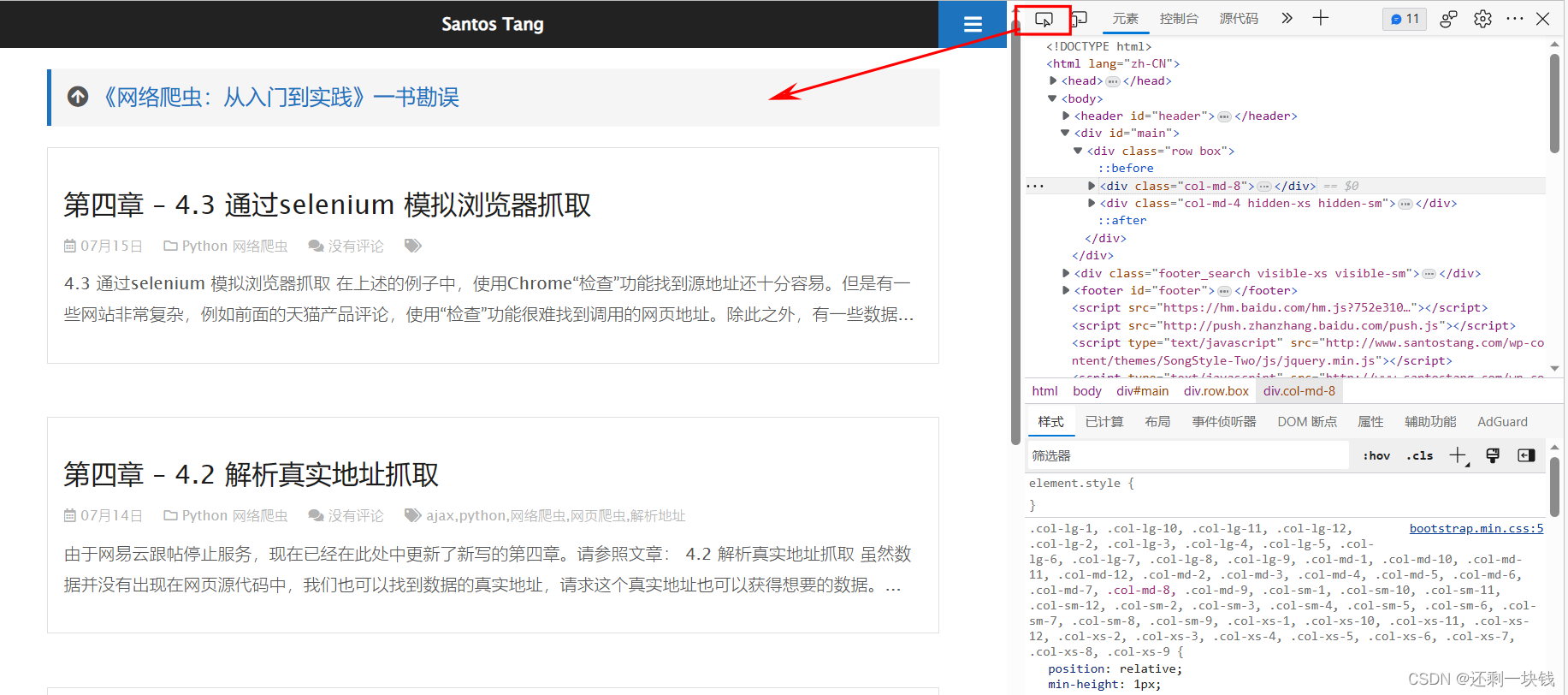
点击小箭头后,会自动跳转到我们想要的内容上,并且显示标签
#*******************************************************#
# 导包:从bs4中导入BeautifulSoup
#*******************************************************#
import requests
from bs4 import BeautifulSoup
#*******************************************************#
# link是我们想要获取的网页链接
# 这个链接可换成我们想要获取的网页链接
#*******************************************************#
link = "http://www.santostang.com/"
#*******************************************************#
# headers是定义的浏览器的请求头,伪装成浏览器
# 一般是固定的,不要去改变它
#*******************************************************#
headers = {
"User-Agent": "Mozilla/5.0 (WIindows; U; Windows NT 6.1;en-US; rv:1.9.1.6)Gecko/20100101 Firefox/3.5.6"}
#*******************************************************#
##### 第一步:请求网页
#*******************************************************#
r = requests.get(link, headers=headers)
print(f"获取网页的html网页内容如下:\n{
r.text}")
#*******************************************************#
##### 第二步:解析网页
# BeautifulSoup会将获取的html文档代码转换成soup对象
# 然后利用soup对象查找我们想要的指定元素
#*******************************************************#
soup = BeautifulSoup(r.text, 'html.parser')
#*******************************************************#
# 利用soup对象查找指定的元素
# soup.find("h1", class_="post-title").a.text.strip()的意思是,找到第一篇文章标题
# 定位到class是"post-title"的h1元素,提取a元素,提取a元素里面的字符串,strip()去除左右空格
#*******************************************************#
title = soup.find("h1",class_="post-title").a.text.strip()
#*******************************************************#
# 输出一下自己提取的结果,看是否提取到
#*******************************************************#
print(title)
#*******************************************************#
##### 第三步:保存数据,为txt
#*******************************************************#
with open("results.txt", "a+") as f:
f.write(title + "\n")