ChatGLM服务器部署微调(二)
修改train.sh
修改train_file
比如我的结构为原本ptuning下面建一个bz_tq文件夹,放了训练数据和测试数据。
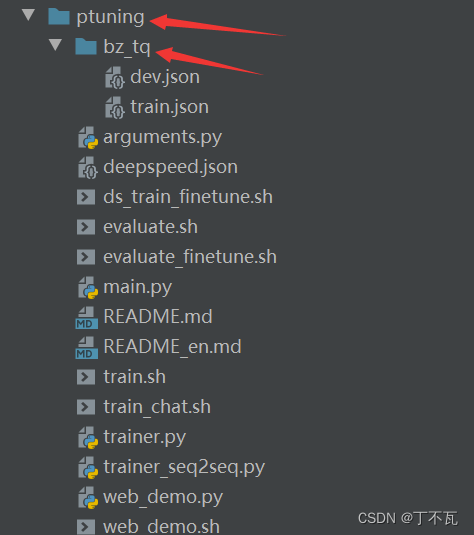
那么我的训练文件那一行就改成
–train_file bz_tq/train.json
同理可得
–validation_file bz_tq/dev.json
模型地址(之前部署中提到我的模型下载到了chatglm-6b这个文件夹下,不清楚的可以看上一篇)
–model_name_or_path …/chatglm-6b
除此之外根据你的训练和测试数据修改prompt_column和response_column
例如我的格式为
{
“text”: “xxxxxxxxxxxxxxxxxxxxxxxxxxx”,
“answer”: “xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n”
}
那么相应的我这两行需要改为
–prompt_column text
–response_column answer
然后还要根据你的数据情况更改
PRE_SEQ_LEN、max_source_length、max_target_length
如果不想运行太久可以改max_steps
比如把3000改成1000
max_steps 1000
修改evaluate.sh
与第一步保持数据一致
训练
根据readme.md文件中写的,需要bash train.sh
首先如下图点击,选择你服务器所在的文件地址
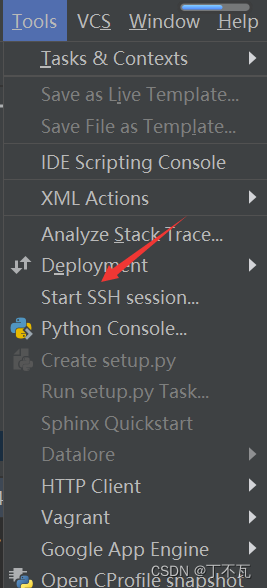
然后在terminal内输入bash train.sh
这样有一个易错点,如下所示
当我到train.sh所在的ptuning这个文件夹下进行这个操作的时候
 会出现ModuleNotFoundError: No module named 'datasets’这个错误
会出现ModuleNotFoundError: No module named 'datasets’这个错误
但是datasets已经pip了 这是因为没有激活环境hhhhh,最左边显示的是bash
这是因为没有激活环境hhhhh,最左边显示的是bash
如下图所示 激活了环境就好了
 训练结束后会显示训练的情况
训练结束后会显示训练的情况
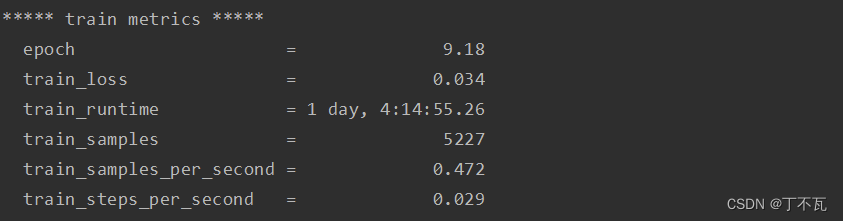 训练之后的文件会在output中
训练之后的文件会在output中
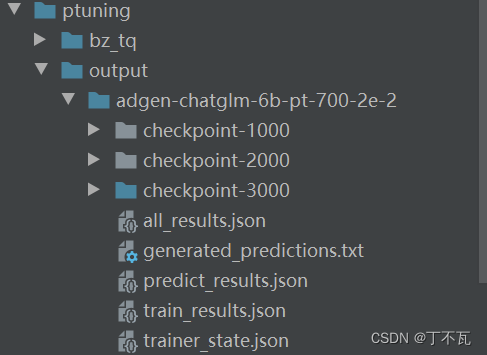
评估
更改evaluate.sh中的(改成训练后生成的文件夹的名称)
CHECKPOINT=adgen-chatglm-6b-pt-700-2e-2(如果一样就不用改了)
注意不要写CHECKPOINT=.output/adgen-chatglm-6b-pt-700-2e-2
不然的话会出现No such file or directory: ’ ./ output/output/ adgen-chatg1m- 6b-pt- 700- 2e -2/checkpoint- 3000/pytorch model.bin ’

因为
–ptuning_checkpoint ./output/$ CHECKPOINT/checkpoint-$ STEP
这一行已经加上了
最后与上面同样的方式,运行evaluate.sh
 同样评估结束后,会显示评估信息
同样评估结束后,会显示评估信息
***** predict metrics *****
predict_bleu-4 = 97.0725
predict_rouge-1 = 98.7145
predict_rouge-2 = 97.6405
predict_rouge-l = 98.2789
predict_runtime = 1:52:04.46
predict_samples = 2123
predict_samples_per_second = 0.316
predict_steps_per_second = 0.316
测试数据的预测结果在generated_predictions中,其他训练和测试相关信息在json文件中
结果对比
用初始模型,运行原来的run.py
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response,history= model.chat(tokenizer, "请提出文本中xxxxxxxxxxx,文本:xxxxxxxxxxx",history=[])
print(response)
用微调模型,运行new.py
import os
import torch
from transformers import AutoConfig, AutoModel, AutoTokenizer
MODEL_PATH = "chatglm-6b"
CHECKPOINT_PATH = "ptuning/output/adgen-chatglm-6b-pt-700-2e-2/checkpoint-3000"
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
config = AutoConfig.from_pretrained(MODEL_PATH, trust_remote_code=True, pre_seq_len=700)
model = AutoModel.from_pretrained(MODEL_PATH, config=config, trust_remote_code=True).cuda()
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {
}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
response, history = model.chat(tokenizer, "请提出文本中xxxxxxxxxxx,文本:xxxxxxxxxxx", history=[])
print(response)
问题待解决
教程都说只需要将原来的model模型改成CHECKPOINT的地址就行了,但是不知道为什么我将run.py改成这样之后,运行会输出空白
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("ptuning/output/adgen-chatglm-6b-pt-700-2e-2/checkpoint-3000", trust_remote_code=True).half().cuda()
model = model.eval()
response,history= model.chat(tokenizer, "请提出文本中xxxxxxxxxxx,文本:xxxxxxxxxxx",history=[])
print(response)

只有改成上面new.py才行