一. Chatglm
相对简单,而且微调之后性能比较奇怪,可以参考ChatGLM-6B 的部署与微调教程
1.1 MNN部署
https://github.com/wangzhaode/ChatGLM-MNN
1.1.1 Linux部署
git clone https://github.com/wangzhaode/ChatGLM-MNN.git
(1)编译MNN
cd MNN
mkdir build && cd build
#使用cuda
cmake -DCMAKE_BUILD_TYPE=Release -DMNN_CUDA=ON ..
make -j$(nproc)
cd ../..#退出
(2)文件拷贝
cp -r MNN/include/MNN include
cp MNN/build/libMNN.so libs/
cp MNN/build/express/*.so libs/
(3)权重下载
挂vpn
cd resource/models
# 下载fp16权值模型, 几乎没有精度损失
./download_models.sh fp16
# 下载int8权值模型,极少精度损失,推荐使用
./download_models.sh int8
# 下载int4权值模型,有一定精度损失
./download_models.sh int4
(4)体验
mkdir build && cd build
cmake -D WITH_CUDA=on ..
# start build(support Linux/Mac)
make -j$(nproc)
./cli_demo # cli demo
./web_demo # web ui demo
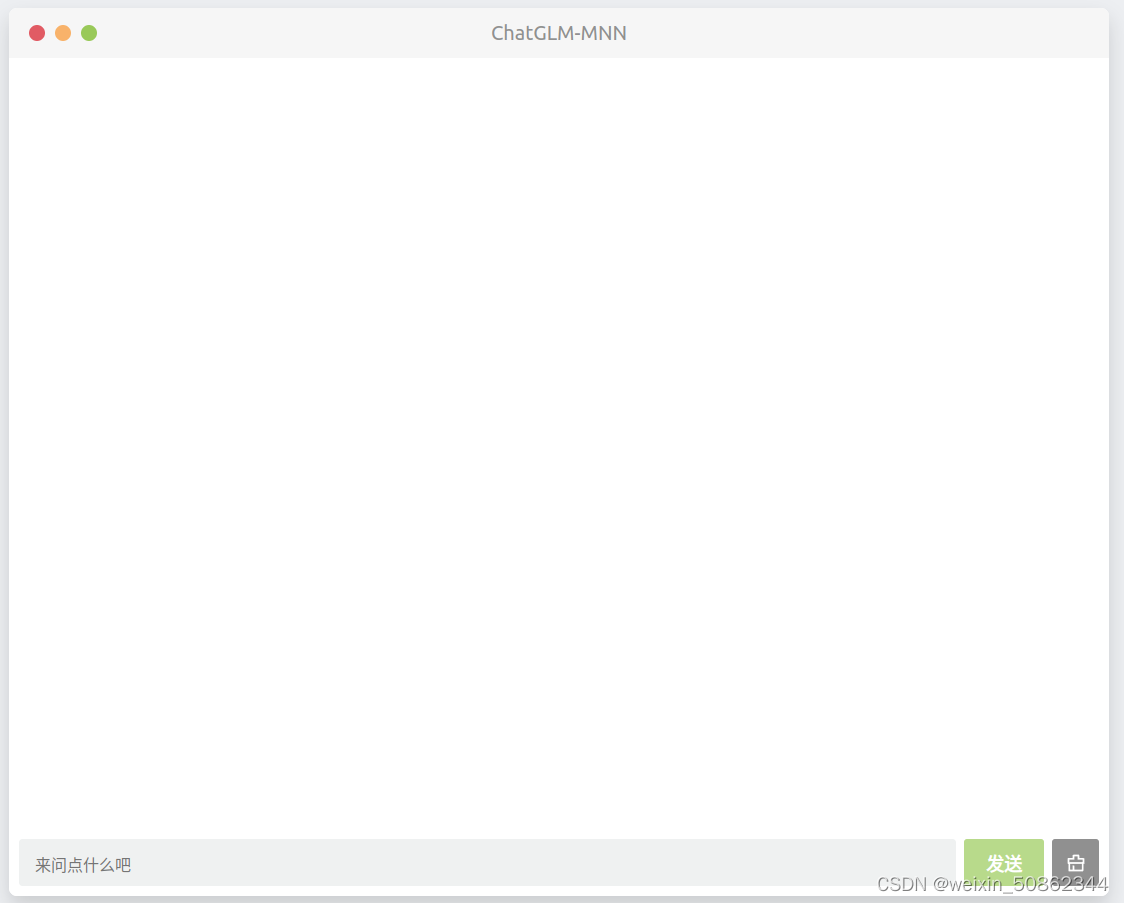
大概长这样但是很快就汇报内存,也是目前他们正在解决的问题
1.2 InferLLM部署
https://github.com/MegEngine/InferLLM