引言
从零开始用语义分割模型PIDNet训练自己的数据集。
PIDNet论文地址:https://arxiv.org/pdf/2206.02066.pdf
PIDNet项目地址:GitHub - XuJiacong/PIDNet: This is the official repository for our recent work: PIDNet
一、数据集的准备
首先说明下需要什么样的数据集:PIDNet需要的语义标签图像是8位的灰度图(和我们之前写过的BiSeNet需要的训练格式一样),语义分割的标签就是用的灰度值表示的。这里先展示下整体的一个数据集文件夹格式,如下图:
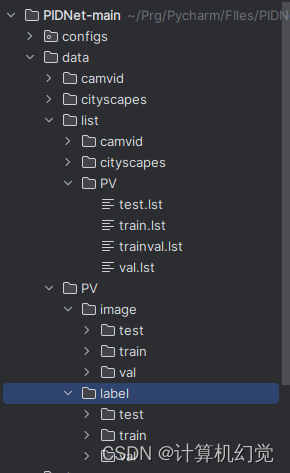
PV是我们数据集的名字,我们需要准备的就是list文件夹下的四个lst映射文件,以及PV文件夹下的image(原图)和label(语义分割图)文件。
1、 首先通过labelme标注图片,以及将json转换为分割后的图片,并且分割后的图片转换为8位的灰度图,这些操作已经在之前的博客介绍过,详细我的另一篇博客参照:
教程--从零开始使用BiSeNet(语义分割)网络训练自己的数据集_计算机幻觉的博客-CSDN博客
按照上面的方法取得8位的灰度图就行。
2、将第一步操作得到的原图和8位灰度图按照上图那个文件夹格式放就行,放完之后我们通过以下代码来获取lst(映射文件),注意修改自己数据集路径:
import os
def op_file():
# train
train_image_root = 'image/train/'
train_label_root = 'label/train/'
train_image_path = 'data/PV/image/train'
train_label_path = 'data/PV/label/train'
trainImageList = os.listdir(train_image_path)
trainLabelList = os.listdir(train_label_path)
train_image_list = []
for image in trainImageList:
train_image_list.append(train_image_root + image)
train_label_list = []
for label in trainLabelList:
train_label_list.append(train_label_root + label)
train_list_path = 'data/list/PV/train.lst'
file = open(train_list_path, 'w').close()
with open(train_list_path, 'w', encoding='utf-8') as f:
for i1,i2 in zip(train_image_list, train_label_list):
print(i1, i2)
f.write(i1 + " " + i2 + "\n")
f.close()
# test
test_image_root = 'image/test/'
test_label_root = 'label/test/'
test_image_path = 'data/PV/image/test'
testImageList = os.listdir(test_image_path)
test_image_list = []
for image in testImageList:
test_image_list.append(test_image_root + image)
test_list_path = 'data/list/PV/test.lst'
file = open(test_list_path, 'w').close()
with open(test_list_path, 'w', encoding='utf-8') as f:
for i1 in test_image_list:
f.write(i1 + "\n")
f.close()
# val
val_image_root = 'image/val/'
val_label_root = 'label/val/'
val_image_path = 'data/PV/image/val'
val_label_path = 'data/PV/label/val'
valImageList = os.listdir(val_image_path)
valLabelList = os.listdir(val_label_path)
val_image_list = []
for image in valImageList:
val_image_list.append(val_image_root + image)
val_label_list = []
for label in valLabelList:
val_label_list.append(val_label_root + label)
val_list_path = 'data/list/PV/val.lst'
file = open(val_list_path, 'w').close()
with open(val_list_path, 'w', encoding='utf-8') as f:
for (i1,i2) in zip(val_image_list, val_label_list):
f.write(i1 + " " + i2 + "\n")
f.close()
# trainval
trainval_list_path = 'data/list/PV/trainval.lst'
file = open(trainval_list_path, 'w').close()
with open(trainval_list_path, 'w', encoding='utf-8') as f:
for (i1,i2) in zip(train_image_list, train_label_list):
f.write(i1 + " " + i2 + "\n")
f.close()
with open(trainval_list_path, 'a', encoding='utf-8') as f:
for (i1,i2) in zip(val_image_list, val_label_list):
f.write(i1 + " " + i2 + "\n")
f.close()
if __name__ == '__main__':
op_file()二、相关代码修改
1、在datasets文件夹下复制同级目录的cityscapes.py,并且重命名为我们数据集的名称PV.py,如下图:
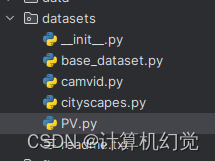
打开PV.py,将其中的Cityscapes全都修改为PV(你数据集的名称);修改num_classes=3(你的类别数,包含了背景,博主这里是三类);修改mean和std;修改label_mapping(几个类就写几个),修改class_weights(详细计算方法如下)
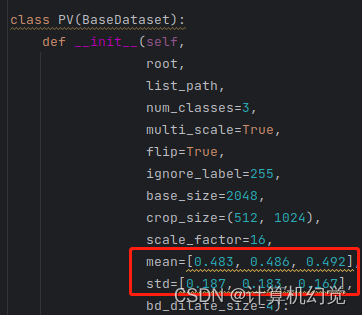

修改上面的需要计算自己数据集的mean、std和class_weights,运行下面代码即可:
from random import shuffle
import numpy as np
import os
import cv2
def get_weight(class_num, pixel_count):
W = 1 / np.log(pixel_count)
W = class_num * W / np.sum(W)
return W
def get_MeanStdWeight(class_num=3, size=(1080, 700)):
image_path = "data/PV/image/train/"
label_path = "data/PV/label/train/"
namelist = os.listdir(image_path)
"""========如果提供的是txt文本,保存的训练集中的namelist=============="""
# file_name = "../datasets/train.txt"
# with open(file_name,"r") as f:
# namelist = f.readlines()
# namelist = [file[:-1].split(",") for file in namelist]
"""==============================================================="""
MEAN = []
STD = []
pixel_count = np.zeros((class_num, 1))
for i in range(len(namelist)):
print(i, os.path.join(image_path, namelist[i]))
image = cv2.imread(os.path.join(image_path, namelist[i]))[:, :, ::-1]
image = cv2.resize(image, size, interpolation=cv2.INTER_NEAREST)
print(image.shape)
mean = np.mean(image, axis=(0, 1))
std = np.std(image, axis=(0, 1))
MEAN.append(mean)
STD.append(std)
label = cv2.imread(os.path.join(label_path, namelist[i]), 0)
label = cv2.resize(label, size, cv2.INTER_LINEAR)
label_uni = np.unique(label)
for m in label_uni:
pixel_count[m] += np.sum(label == m)
MEAN = np.mean(MEAN, axis=0) / 255.0
STD = np.mean(STD, axis=0) / 255.0
weight = get_weight(class_num, pixel_count.T)
print(MEAN)
print(STD)
print(weight)
return MEAN, STD, weight
if __name__ == '__main__':
get_MeanStdWeight()
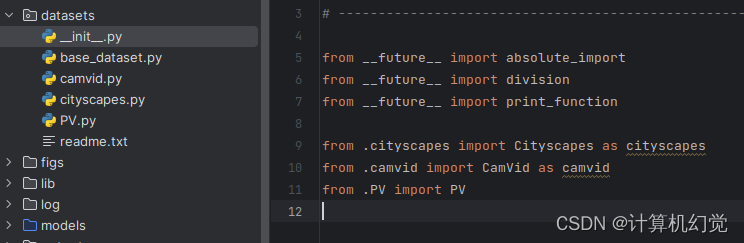
2、在datasets/__init_.py文件下导入我们刚才建立的数据集:
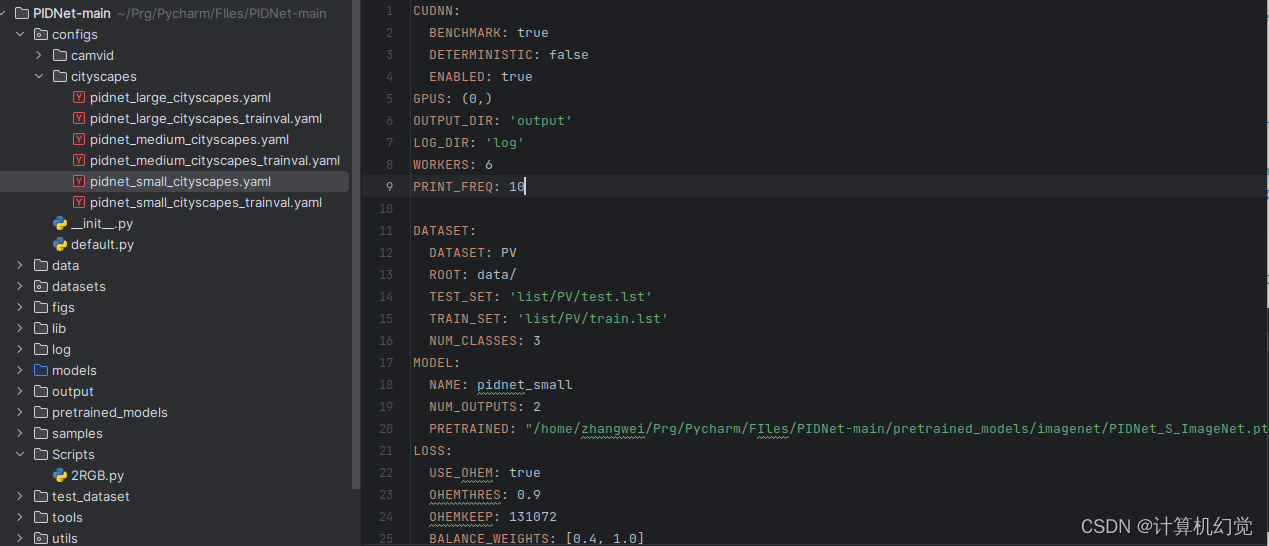
3、打开configs/cityscapes/pidnet_small_cityscapes.yaml文件(博主这里选择最小的模型,你们随意),修改训练集名称、数据集路径、类别数以及训练模型地址:
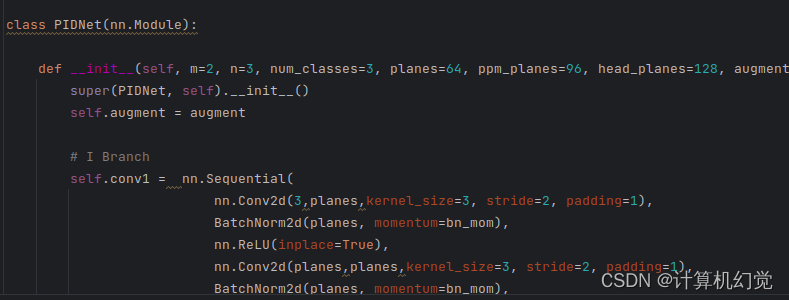
4、打开models/pidnet.py,修改PIDNet的num_classes为你的类别数:
三、开始训练
博主采用单GPU训练,你们记得修改yaml文件中的GPU数量,执行下面代码开始训练:
python tools/train.py --cfg configs/cityscapes/pidnet_small_cityscapes.yaml博主没遇到错误,你们要是遇到Error可以在评论区留言,博主都会一一解答。
需要注意的是,PIDNet网络会用到多次下采样,所以说对训练图片的尺寸大小是有一定要求的,不然会出现demoions不匹配的问题,博主的训练图片大小是1080x640的。可以通过裁剪的方式改变训练集大小,裁剪的代码在我之前的博客中也有(教程--从零开始使用BiSeNet(语义分割)网络训练自己的数据集_计算机幻觉的博客-CSDN博客)。
四、测试
1、图片测试:
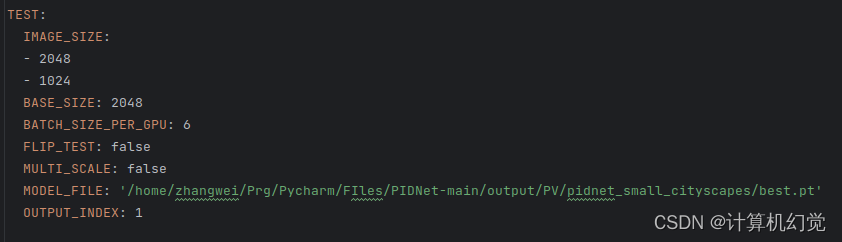
测试之前,需要指定好加载的训练模型,在yaml文件中修改,如下图:
执行代码,开始测试:
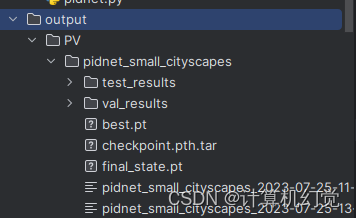
python tools/eval.py --cfg experiments/cityscapes/pidnet_small_cityscapes.yaml测试的结果会在output文件夹下,如下图:
注意:这个时候测试会发现,得到的图片是黑色的,也就是说最终保存的结果是8位的灰度图,而我们需要的是24位的RGB图片,解决方法:
再次打开datasets/PV.py文件(就是我们定义自己数据集的文件),增加color_list属性,如下:
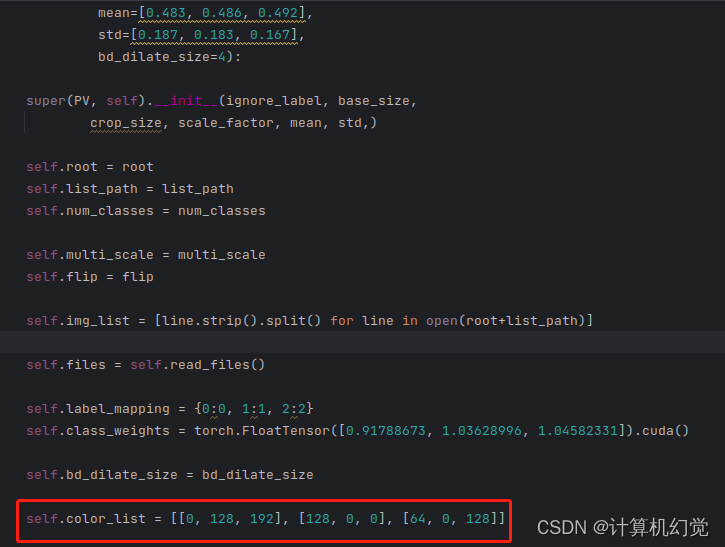
我这里是三类,所以颜色就随便写了三种(包含背景),根据你们自己需求就行。再增加label2color函数,如下图:
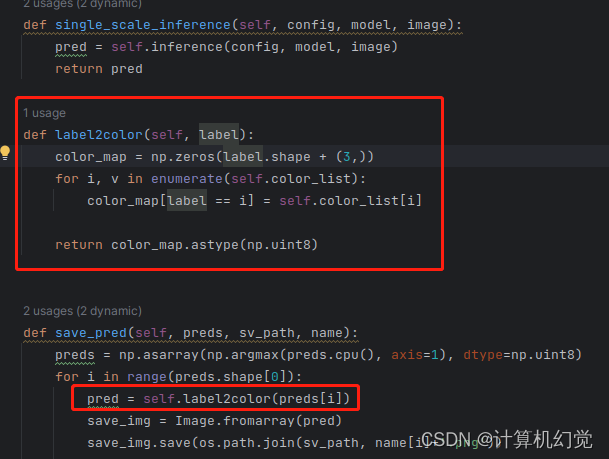
代码:
def label2color(self, label):
color_map = np.zeros(label.shape + (3,))
for i, v in enumerate(self.color_list):
color_map[label == i] = self.color_list[i]
return color_map.astype(np.uint8)
def save_pred(self, preds, sv_path, name):
preds = np.asarray(np.argmax(preds.cpu(), axis=1), dtype=np.uint8)
for i in range(preds.shape[0]):
pred = self.label2color(preds[i])
save_img = Image.fromarray(pred)
save_img.save(os.path.join(sv_path, name[i]+'.png'))再重新测试,输出的就是RGB图像了。
2、视频测试:
源代码没有提供视频测试,博主这里提供一个,代码如下:
import os
import pprint
import sys
sys.path.insert(0, '.')
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.multiprocessing as mp
import time
from PIL import Image
import numpy as np
import cv2
import logging
import lib.data.transform_cv2 as T
from utils.utils import create_logger
from configs import config
from configs import update_config
torch.set_grad_enabled(False)
import torch.backends.cudnn as cudnn
import models
# args
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='/home/zhangwei/Prg/Pycharm/FIles/PIDNet-main/configs/cityscapes/pidnet_small_cityscapes.yaml')
parser.add_argument('--weight-path', type=str, default='/home/zhangwei/Prg/Pycharm/FIles/PIDNet-main/output/PV/pidnet_small_cityscapes/best.pt')
parser.add_argument('--input', type=str, default='/home/zhangwei/Prg/Pycharm/FIles/PIDNet-main/test_dataset/video.avi')
parser.add_argument('--output', type=str, default='/home/zhangwei/Prg/Pycharm/FIles/PIDNet-main/test_dataset/PIDNet.mp4')
parser.add_argument('opts',
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER)
args = parser.parse_args()
update_config(config, args)
# fetch frames
def get_func(inpth, in_q, done):
cap = cv2.VideoCapture(args.input)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # type is float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # type is float
fps = cap.get(cv2.CAP_PROP_FPS)
to_tensor = T.ToTensor(
mean=(0.3257, 0.3690, 0.3223), # city, rgb
std=(0.2112, 0.2148, 0.2115),
)
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
frame = frame[:, :, ::-1]
frame = to_tensor(dict(im=frame, lb=None))['im'].unsqueeze(0)
in_q.put(frame)
in_q.put('quit')
done.wait()
cap.release()
time.sleep(1)
print('input queue done')
# save to video
def save_func(inpth, outpth, out_q):
np.random.seed(123)
palette = np.random.randint(0, 256, (256, 3), dtype=np.uint8)
cap = cv2.VideoCapture(args.input)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # type is float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # type is float
fps = cap.get(cv2.CAP_PROP_FPS)
cap.release()
video_writer = cv2.VideoWriter(outpth,
cv2.VideoWriter_fourcc(*"mp4v"),
fps, (int(width), int(height)))
while True:
out = out_q.get()
if out == 'quit': break
out = out.numpy()
preds = palette[out]
for pred in preds:
video_writer.write(pred)
video_writer.release()
print('output queue done')
# inference a list of frames
def infer_batch(frames):
frames = torch.cat(frames, dim=0).cuda()
H, W = frames.size()[2:]
frames = F.interpolate(frames, size=(768, 768), mode='bilinear',
align_corners=False) # must be divisible by 32
out = model(frames)[0]
out = F.interpolate(out, size=(H, W), mode='bilinear',
align_corners=False).argmax(dim=1).detach().cpu()
out_q.put(out)
if __name__ == '__main__':
# args = parse_args()
logger, final_output_dir, _ = create_logger(
config, args.cfg, 'test')
logger.info(pprint.pformat(args))
logger.info(pprint.pformat(config))
# cudnn related setting
cudnn.benchmark = config.CUDNN.BENCHMARK
cudnn.deterministic = config.CUDNN.DETERMINISTIC
cudnn.enabled = config.CUDNN.ENABLED
# build model
model = model = models.pidnet.get_seg_model(config, imgnet_pretrained=True)
if config.TEST.MODEL_FILE:
model_state_file = config.TEST.MODEL_FILE
else:
model_state_file = os.path.join(final_output_dir, 'best.pt')
logger.info('=> loading model from {}'.format(model_state_file))
pretrained_dict = torch.load(model_state_file)
if 'state_dict' in pretrained_dict:
pretrained_dict = pretrained_dict['state_dict']
model_dict = model.state_dict()
pretrained_dict = {k[6:]: v for k, v in pretrained_dict.items()
if k[6:] in model_dict.keys()}
for k, _ in pretrained_dict.items():
logger.info(
'=> loading {} from pretrained model'.format(k))
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
mp.set_start_method('spawn')
in_q = mp.Queue(1024)
out_q = mp.Queue(1024)
done = mp.Event()
in_worker = mp.Process(target=get_func,
args=(args.input, in_q, done))
out_worker = mp.Process(target=save_func,
args=(args.input, args.output, out_q))
in_worker.start()
out_worker.start()
model.eval()
model = model.cuda()
frames = []
while True:
frame = in_q.get()
if frame == 'quit': break
frames.append(frame)
if len(frames) == 8:
infer_batch(frames)
frames = []
if len(frames) > 0:
infer_batch(frames)
out_q.put('quit')
done.set()
out_worker.join()
in_worker.join()
修改好自己的各个文件路径,执行代码:
python demo_video.py --cfg /home/zhangwei/Prg/Pycharm/FIles/PIDNet-main/configs/cityscapes/pidnet_small_cityscapes.yaml
稍微等一会儿即可,在test_dataset目录下可以看到生成的mp4文件,打开即可。

至此,PIDNet的训练教程结束,如果有什么问题可以留言,博主都会一一解答。