记录一下用DeepLabV3+模型从下载、环境配置、网络训练到模型预测(推理)的全过程,以及如何利用自己的数据集进行模型训练和模型的backbone(骨干网络)的修改,非常详细,很适合小白食用,希望能够大家提供参考。
主要有以下几个部分:
文章目录
1.简介
废话不多说,先给大家上链接。
论文地址:https://arxiv.org/pdf/1802.02611.pdf
代码地址:
Tensorflow版本的GitHub地址:https://github.com/tensorflow/models/tree/master/research/deeplab
Pytorch版本的Github地址:
https://github.com/VainF/DeepLabV3Plus-Pytorch
公共数据集地址:
PASCAL VOC 2012:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
Deeplabv3+模型是由谷歌在2021年提出来的一个用于语义分割的模型,它可以进行多分类语义分割也可以进行实例分割,在公共数据集PASCAL VOC 2012和Cityscapes上达到了89.0%及82.1%的精度,同时也是一个较为轻便的模型,因此Deeplabv3+是一个兼具了速度和精度的模型。原版本是基于Tensorflow写的,有大神给出了pytorch版本的,本文是基于pytorch版本的复现流程。
模型介绍及网络设计可以参考这几篇博客,写的很好,我这里就不过多介绍了。
http://t.csdn.cn/z82Ji
https://blog.csdn.net/oYeZhou/article/details/112231858
2.模型下载及环境配置
首先来到上面给出的github网址下载模型,地址如下:
https://github.com/VainF/DeepLabV3Plus-Pytorch。
以下进行环境配置。
1)创建虚拟环境。首先打开cmd窗口,输入conda create --name Deeplabv3_plus python=3.8,创建名为Deeplabv3_plus的虚拟环境,这样我们后续安装的所有包就都在这个虚拟环境下进行,这样可以避免不同的网络模型对包的版本需求不同,而造成的不兼容问题。以后的所有操作都在这个环境下进行。这里我指定了python=3.8,后面我们pytorch的版本也是基于3.8进行安装的。
2)环境激活。在cmd中输入activate Deeplabv3_plus,这样就激活了环境。

3)pytorch及相关包的安装。首先去官网下载pytorch,我这里下载的是torch1.8,python3.8版本的,同时下载torchaudio和torchvision,然后就可以安装了。
还是在cmd窗口,在虚拟环境激活的情况下,如果虚拟环境没激活,记得输入activate Deeplabv3_plus激活虚拟环境,输入pip install C:\Users\admin\Downloads\torch-1.8.1+cu111-cp38-cp38-win_amd64.whl 即可完成torch的安装,这里的C:\Users\admin\Downloads\torch-1.8.1+cu111-cp38-cp38-win_amd64.whl是本地的torch存放的路径,可根据情况自行修改。
然后依次安装另外两个包。
pip install C:\Users\admin\Downloads\torchaudio-0.8.1-cp38-none-win_amd64.whl
pip install C:\Users\admin\Downloads\torchvision-0.9.1+cu111-cp38-cp38-win_amd64.whl
好了,到此,我们的pytorch已经安装完毕了,剩下的就是简单的包了。
打开requirements.txt 把里面的torch和torchvision删掉,然后输入 pip install -r D:\Code\DeepLabV3Plus-Pytorch-master\requirements.txt把剩下的包也安装一下。
后面可能还有一些包,都是比较好安装的,这里就不赘述了。
4)环境配置。用pycharm打开项目,然后在“文件”-“设置”里面找到“Python解释器”,点击后面的“添加”按钮,
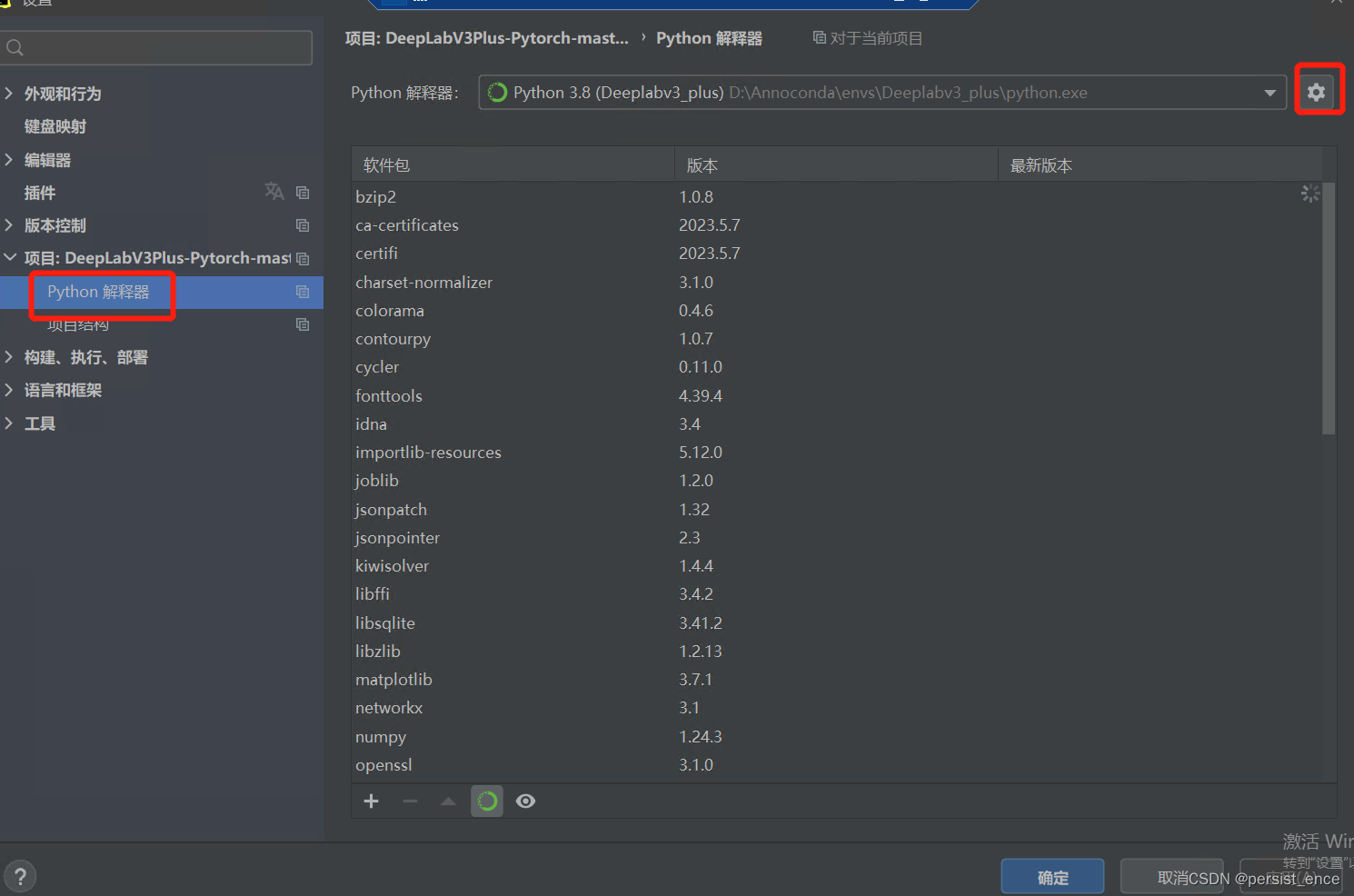
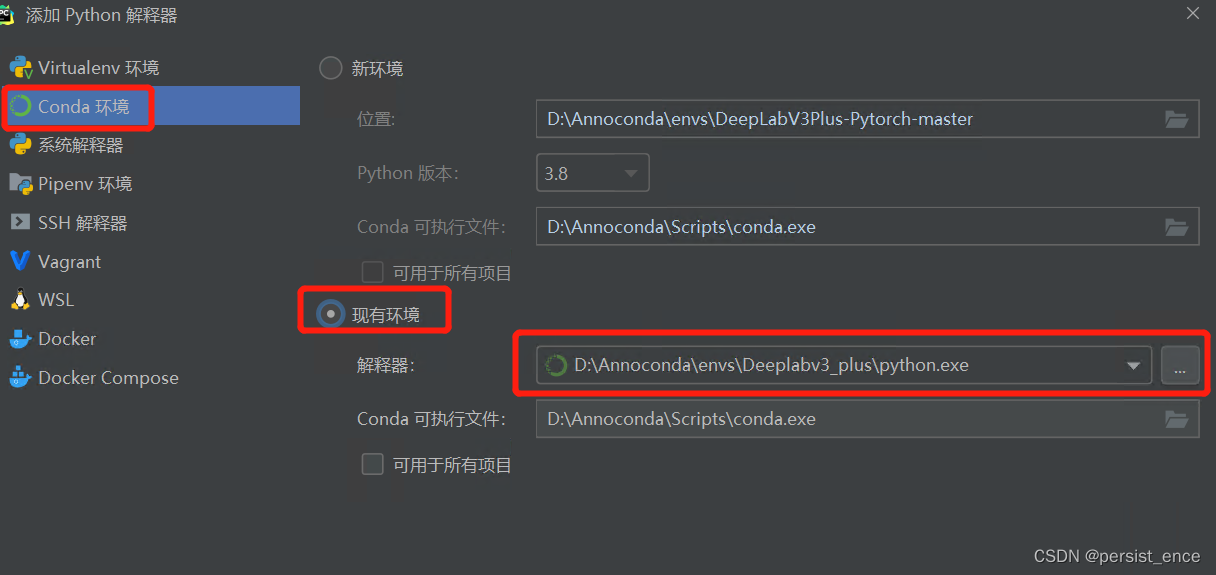
然后选择“Conda环境”-“现有环境”,点击解释器一栏最后面的按钮,找到我们刚刚创建的虚拟环境的路径,选择该路径下的python.exe。
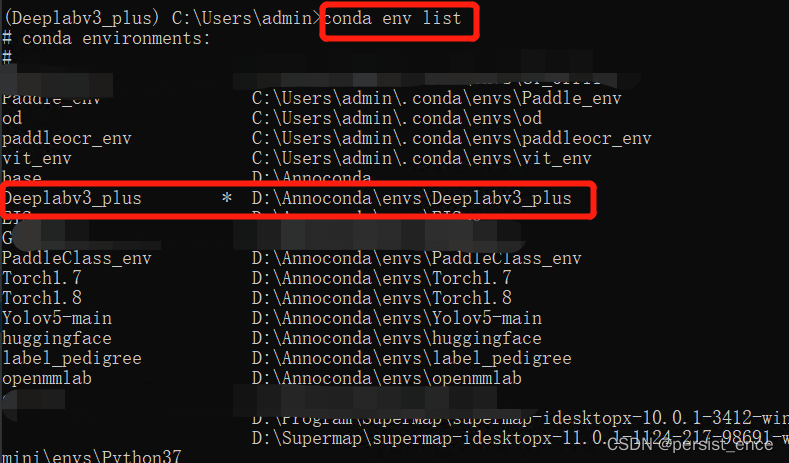
如果不记得虚拟环境的位置,可以在cmd中输入conda env list查看虚拟环境的路径。
3. 使用公共数据集进行模型训练及预测
(1)模型训练
模型训练用到的是main.py。
1)环境就绪之后,就可以下载公共数据集进行训练了。这边我选择的是PASCAL VOC 2012数据集,数据集的下载链接已经置顶了。
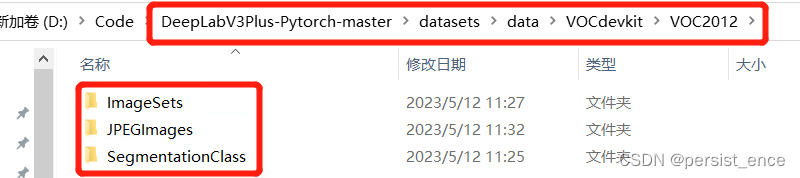
2)下载数据之后,我们把数据集解压,放在项目路径下,如下图所示。
然后修改main.py 里面的data_root为下载的数据集的路径,这里我用的相对路径“./datasets/data”。

3)设置好输入数据之后就可以点击运行main.py了。如果有报错的话,可以试试是不是需要加一句visdom -port 28333,我是直接运行的,没有遇到任何问题。
4)加预训练模型或者模型中断之后接着训练。
如果模型中断,需要接着上面的继续训练或者添加别人训练好的预训练模型,需要修改“ckpt”,将其修改为你存储模型的那个路径,我这里是用的相对路径“./checkpoints/best_deeplabv3plus_xception_voc_os16.pth”,然后修改“continue_training”为“True”。然后运行main.py就可以了。

(2)模型精度评价
模型训练完成之后,需要对其进行精度评价,进行精度评价也是在main.py中。
修改四个参数。
将“test_only”修改为“True”;
将“save_val_results”修改为"True",这个操作会将精度验证的结果存储到项目路径下的results文件夹下;
将"ckpt"修改为自己需要进行精度评价的模型路径,我这里是“./checkpoints/best_deeplabv3plus_xception_voc_os16.pth”;
将“continue_training”修改为“False”。


(3)模型预测或模型推理
模型推理或者模型预测用到的是predict.py。
需要修改以下几个参数:
"input"修改为自己的要预测的数据的路径;
"save_val_results_to"修改为自己要存放的预测结果的路径;
"ckpt"修改为自己训练好的模型的路径。



参数都修改完成后就可以进行预测了。
(4)backbone修改
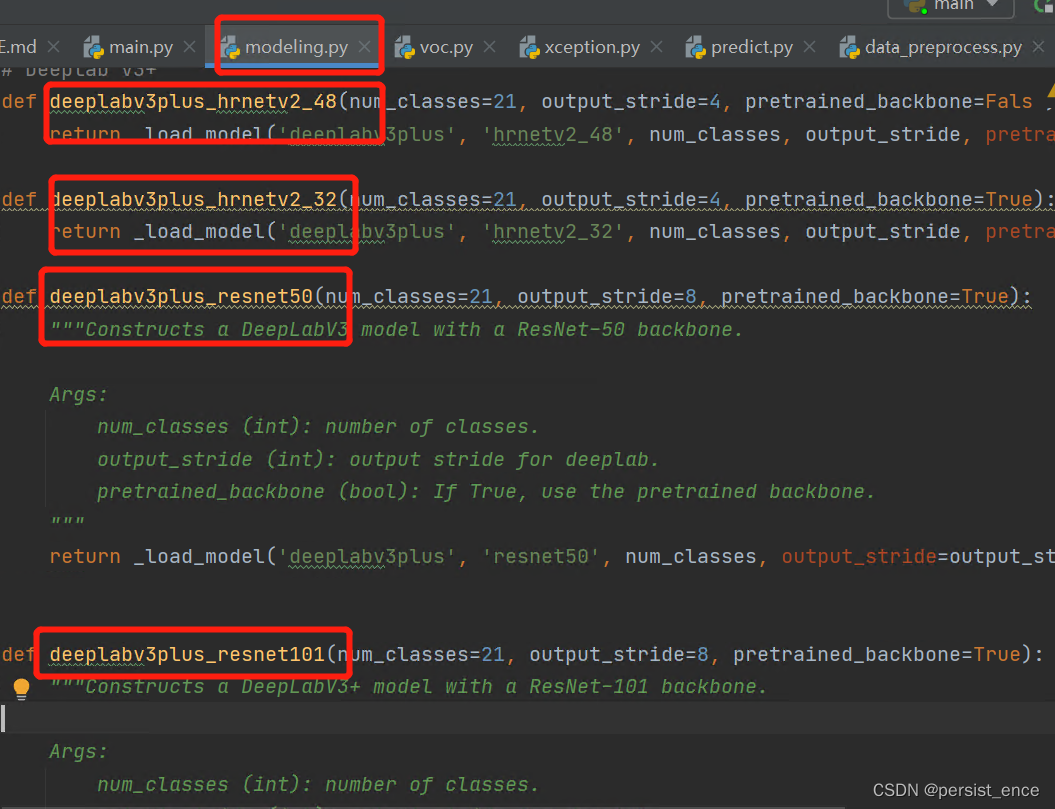
这里提供给大家的有hrnet,mobilenet,resnet和xception四种不同网络作为backbone的deeplabv3和**deeplabv3+**的模型。因此,网络很庞大,可以根据自己的需要更换backbone。
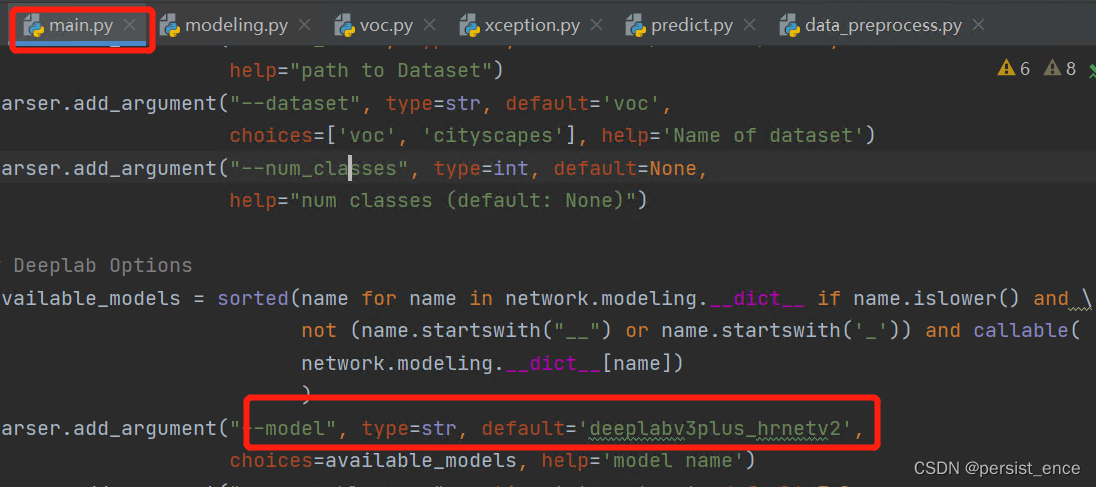
在network文件夹下,有个modeling.py的文件,里面提供了很多种模型供我们选择。比如我选择使用hrnetv2_48作为backbone的deeplabv3_plus模型,我们可以在main.py中修改model参数为我们要用的模型。
4. 使用自制数据集进行模型训练集预测
如果要用自己的数据集进行训练,需要先弄清楚,使用的VOC数据集的组织形式及会用到VOC数据集中的哪几个部分。
(1)VOC数据组织形式介绍
下图是VOC数据集的组织结构,我们如果要进行多分类语义分割的话,用到的有ImageSets文件夹,JPEGImages文件夹和SegmentationClass文件夹。
JPEGImages文件夹中存放的是用于训练的影像,格式为jpg格式。
SegmentationClass中存放的是标签数据集,格式为png格式。
ImageSets文件夹中嵌套着Segmentation文件夹,Segmentation文件夹中
存放train.txt,val.txt和trainval.txt,这三个txt文件中分别存放有用于训练的数据名字,用于验证的数据的名字和训练加验证的数据的名称。
讲完了VOC的数据组织形式,我们就可以将我们自己的数据集改造成这样的格式存放,然后就可以把数据集放进模型进行训练了。
(2)自制数据集改造
1)我们自己的数据集格式一般有一个数据文件夹,一个标签文件夹,我们先把数据文件夹中的数据全部转换为jpg格式,然后将标签文件夹中的数据转换成png格式。
2)将待训练的所有jpg图片全部放入JPEGImages文件夹中,将所有png标签全部放入SegmentationClass文件夹中。
3)在ImageSets文件夹中新建Segmentation文件夹,在Segmentatin文件夹中新建train.txt ,val.txt 和 trainval.txt。然后将要数据集中的图片,按照一定的比例分为训练集和验证集,将训练集和验证集的图片的名字写入对应的txt文件中就可以了。如果不会自己分堆的话,可以参考下面这段代码,帮助大家用自己的文件夹进行分堆,这里用到的是随机分堆。
import os
import random
if __name__ == '__main__':
file_root = r'D:\Code\DeepLabV3Plus-Pytorch-master\datasets\data\VOCdevkit\VOC2012\JPEGImages'
file_list = os.listdir(file_root)
num_files = int(len(file_list)*0.8)
selected_files = random.sample(file_list,num_files)
with open(r'D:\Code\DeepLabV3Plus-Pytorch-master\datasets\data\VOCdevkit\VOC2012\ImageSets\Segmentation\val.txt','w') as f:
for file in file_list:
if file not in selected_files:
f.write(file.split('.')[0])
f.write('\n')
f.close()
with open(r'D:\Code\DeepLabV3Plus-Pytorch-master\datasets\data\VOCdevkit\VOC2012\ImageSets\Segmentation\train.txt',
'w') as f:
for file in selected_files:
f.write(file.split('.')[0])
f.write('\n')
f.close()
with open(r'D:\Code\DeepLabV3Plus-Pytorch-master\datasets\data\VOCdevkit\VOC2012\ImageSets\Segmentation\trainval.txt',
'w') as f:
for file in file_list:
f.write(file.split('.')[0])
f.write('\n')
f.close()
用上述代码,写完之后,修改main.py里面的数据路径就可以用自己的数据进行训练啦,希望大家都能快速上手,训练出好的模型。