往期文章
目录
一、图片准备工作
1. 图像切片
将要放入网络的视频准备好,放入./video文件夹,使用下列程序对视频进行切片:
import cv2
import os
import sys
#视频片段的路径
input_path = "./视频所在路径"
#设定每隔多少帧截取一帧
fram_interval = 7
filenames = os.listdir(input_path)
video_prefix = input_path.split(os.sep)[-1]
#建立一个新文件夹,名称为原文件夹名称后加上_frames
frame_path = '{}_frame'.format(input_path)
if not os.path.exists(frame_path):
os.mkdir(frame_path)
cap = cv2.VideoCapture()
for filename in filenames:
filepath = os.sep.join([input_path,filename])
cap.open(filepath)
#获取视频帧数
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
#若画质低,则略过头帧
#for i in range(42):
#cap.read()
for i in range(n_frames):
ret, frame = cap.read()
#每隔frame_interval帧进行一次截屏操作
if i % fram_interval == 0:
imagename = '{}_{:0>6d}.jpg'.format(filename.split('.')[0],i)
imagepath = os.sep.join([frame_path,imagename])
print('exported {}!'.format(imagepath))
cv2.imwrite(imagepath,frame)
#图片重命名
path="D:/wyc/myfirsttest/video_frame"
#获取该目录下所有文件,存入列表中
fileList=os.listdir(path)
n=0
m=0
for i in fileList:
#设置旧文件名
oldname=path+ os.sep + fileList[n]
#设置新文件名
newname=path+os.sep +"train"+str(m+1)+".jpg"
os.rename(oldname,newname)
print(oldname,'======>',newname)
n+=1
m+=1
cap.release()切片完成后的图片保存在./video_frame中,注意一定要修改新的图片名称方便后期训练。
2. 使用labelimg进行图像标定
页面介绍:

OpenDir:打开要进行标定的图片所在文件夹,所有要标定的图片会显示在右下角
ChangeSaveDir:选定VOC标签.xml文件的保存位置
View-》Auto-Save-Mode:选中打开自动保存
键盘切换英文输入-》w:开始标定
键盘切换英文输入-》a/d:上一张/下一张图片
二、制作Yolov5数据集
1.图片和标签的准备
Yolov5的VOC数据集包含三个部分:图片.jpg,VOC格式的标签.xml,yolov5格式的数据集.txt
在yolov5根目录下新建VOC文件夹结构如下:
VOC——VOC2007 ——Annotations
|——JPEGImages
|——YOLOLabels前两个文件夹可以根据喜好命名,三个子文件夹最好按照约定俗成的方法命名,避免影响YOLO读取。
在Annotations中放置标定的.xml标签,在JPEGImages中放置图片,由于更改了标签的存储路径,在VOC2007中批量修改.xml中指向的图片:
import xml.etree.ElementTree as ET
import os
path="./.xml文件存放位置/" # 路径后面记得加斜杠!!!
sv_path="./修改后要存放.xml的位置/"
imgpath="./新的path路径(图片所在的文件路径)"
files=os.listdir(path) #读取路径下所有文件名
for xmlFile in files:
if xmlFile.endswith('.xml'):
tree=ET.ElementTree(file = path+xmlFile) #打开xml文件,送到tree解析
root=tree.getroot() #得到文档元素对象
root[0].text='ImageSets'
#root[0].text是annotation下第一个子节点中内容,直接赋值替换文本内容
root[2].text=imgpath+xmlFile
root[2].text = root[2].text.replace('xml','jpg')
#替换后的内容保存在内存中需要将其写出
tree.write(sv_path+xmlFile) 2. 一步到位生成.txt数据集并划分训练集和测试集:
记得修改路径名和目标名称
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["Mr.C"]#这里修改成你的标签名称
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOC/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOC/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOC/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()生成完之后的文件结构:
VOC——images————train
| |——val
|
|——labels————train
| |——val
|
|——VOC2007——……labels中记录了标定目标的个数和位置,可以检查是否为空或者有负数:

三、训练模型
1. 修改数据集配置文件
找到根目录下的./data文件,复制voc.yaml重命名一份,修改其中参数如下:
train: ./train图像文件夹 #最好写成绝对路径,下同
val: ./val图像文件夹
nc: 1 # number of classes
names: ['标定的目标名称'] # class names其余部分全部注释掉
2.修改模型配置文件
找到根部录下./model文件,选择要作为训练的模型的.yaml,修改其中参数:
nc: 1 # number of classes其余不动。
3.修改主函数参数
根目录下找到train.py,配置部分:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT/'models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/myvoc.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=150)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
参数解析:
--weights:初始化的权重文件的路径地址
--cfg:模型yaml文件的路径地址
--data:数据yaml文件的路径地址
--hyp:超参数文件路径地址
--epochs:训练轮次
--batch-size:喂入批次文件的多少
--img-size:输入图片尺寸
--rect:是否采用矩形训练,默认False
--resume:接着打断训练上次的结果接着训练
--nosave:不保存模型,默认False
--notest:不进行test,默认False
--noautoanchor:不自动调整anchor,默认False
--evolve:是否进行超参数进化,默认False
--bucket:谷歌云盘bucket,一般不会用到
--cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
--image-weights:使用加权图像选择进行训练
--device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
--multi-scale:是否进行多尺度训练,默认False
--single-cls:数据集是否只有一个类别,默认False
--adam:是否使用adam优化器
--sync-bn:是否使用跨卡同步BN,在DDP模式使用
--local_rank:DDP参数,请勿修改
--workers:最大工作核心数
--project:训练模型的保存位置
--name:模型保存的目录名称
--exist-ok:模型目录是否存在,不存在就创建
--weights中default=路径修改为要训练的.pt所在位置
--cfg中default=对应权重.yaml所在位置
--data中default=数据集配置文件.yaml所在位置
--epochs中default=训练的轮数(直接影响训练效果和时间)
然后就可以运行train.py训练模型了!
4.启用TensorBoard追踪训练进度
在根目录下打开命令提示符,启动虚拟环境,键入:
tensorboard --logdir=runs/train可以在提供的localhost6006查看训练结果:
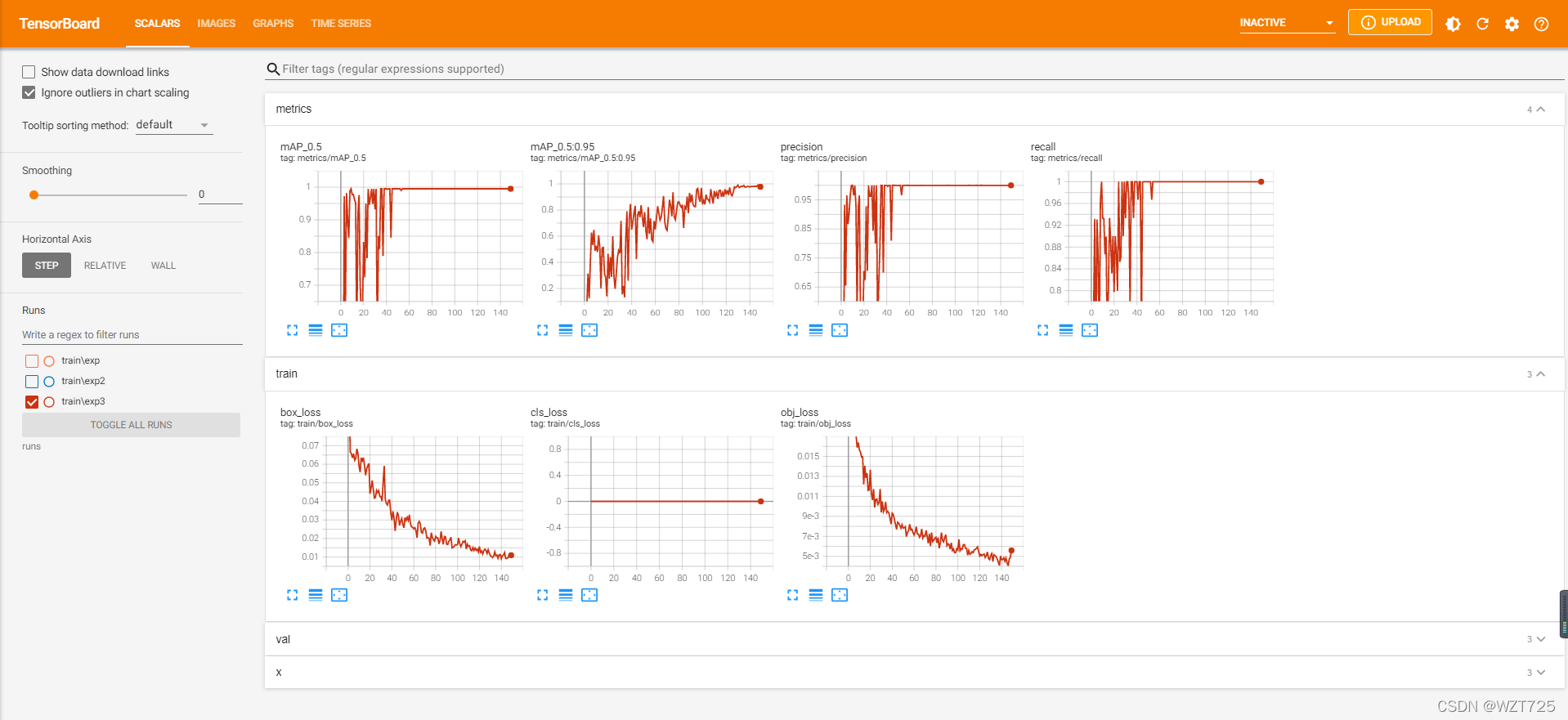
模型训练好后用TensorBoard查看结果:
tensorboard --logdir=runs
四、模型验证
训练好的数据保存在./run/train/exp,包括训练好的两个.pt权重文件(一个是最后一次训练的,一个是最好的)。
在根目录打开detect.py,配置部分:
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=0, help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
参数解析:
--weights:权重的路径地址
--source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
--output:网络预测之后的图片/视频的保存路径
--img-size:网络输入图片大小
--conf-thres:置信度阈值
--iou-thres:做nms的iou阈值
--device:是用GPU还是CPU做推理
--view-img:是否展示预测之后的图片/视频,默认False
--save-txt:是否将预测的框坐标以txt文件形式保存,默认False
--classes:设置只保留某一部分类别,形如0或者0 2 3
--agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
--augment:推理的时候进行多尺度,翻转等操作(TTA)推理
按照和train一样的方法修改--weights,选择训练好的.pt文件
1. 验证图片或视频:
将图片放入./data/image下,修改--source下的路径,运行detect.py,验证结果保存在./runs/detect/exp
验证视频和验证图片同样的方法
3. 用摄像头进行验证:
将--source修改成:
parser.add_argument('--source', type=str, default=0, help='file/dir/URL/glob, 0 for webcam')default指代的摄像头和用openCV的VideoCapture调用的摄像头一致。
到此就全部完成了用yolov5训练自己的数据集。