论文信息
题目:Exploiting Proximity-Aware Tasks for Embodied Social Navigation
作者:Enrico Cancelli, Tommaso Campari
来源:arXiv
时间:2023
Abstract
学习如何在封闭且空间受限的室内环境中在人类之间导航,是体现主体融入我们社会所需的关键能力。
在本文中,我们提出了一种端到端架构,该架构利用邻近感知任务(称为风险和邻近指南针)将推断常识性社会行为的能力注入到强化学习导航策略中。
为此,我们的任务利用了当前和未来碰撞危险(immediate and future dangers of collision)的概念。
此外,我们提出了一种专门为模拟环境中的社交导航任务设计的评估协议。这样做是为了通过分析人机空间交互的最小单元(称为“相遇”)来捕获策略的细粒度特征和特征。
Introduction
如图 1 所示,代理应该能够通过避开静态物体和移动人员来动态地、交互式地导航环境。

在 PointGoal 导航任务中(需要代理到达环境中的特定位置),没有任何传感器/驱动噪声的代理经过数十亿步的训练可以获得几乎完美的性能 [42]。即使存在噪声,其他方法 [45, 27] 也获得了令人印象深刻的结果。
另一个相关任务是对象目标导航,其中代理需要在给定对象类别的情况下查找并导航到特定对象。这项任务需要语义和导航功能,并导致基于语义图 [9,6,32] 的模块化方法的开发,以及使用强化学习 (RL) 的端到端训练模型 [46, 33]
但前面提到的所有任务都在基本静态的环境中构建了导航。场景中有感知、移动的人类引入的动态元素迫使我们重新思考当前模型的设计方式。
场景中有感知、移动的人类引入的动态元素迫使我们重新思考当前模型的设计方式。良好的导航政策不仅必须有效(即能够实现其目标)和高效(即能够通过接近最优的路径实现目标),而且还必须安全(在不伤害他人的情况下到达目的地)。该社交元素包含在社交导航任务 (SocialNav) [44, 29] 中,其中代理必须在模拟室内环境中处理 PointGoal 导航。
为了解决这一任务,Yokoyama 等人 [47] 引入了一个简单但非常有效的模型,该模型在 iGibson 2021 SocialNav 挑战赛中获得第一名。然而,该方法并未在其导航策略中明确编码任何社会行为。
我们为 SocialNav 任务定义了细粒度的评估协议,以更好地分析代理在人与代理交互期间的表现。我们的评估协议受到机器人技术中类似尝试[30]的启发,其中包括收集有关人类和机器人之间特定类型交互的统计数据(通过问卷调查)。
我们提出通过识别和表征人类与代理之间的遭遇来进行自动评估。为此,我们提取了短子序列,其中与人类的交互成为影响导航的主要因素,并且我们建立了一组规则,用于根据时间上人类代理空间关系的类型对每次遭遇进行分类。最后,我们还引入了基于 HM3D [31] 的情节数据集,用于体现社交导航,以评估不同环境中的代理。
总之,这项工作的贡献有三个:
(1)基于邻近感知任务的体现社交导航的新颖架构;我们在两个公共数据集上展示了该模型的有效性。
(2)一种新的基于遭遇的评估协议,用于分析社交导航模型。
(3)基于 HM3D 数据集(称为 HM3D-S)的一组用于评估体现社交导航的情节。
Related Work
Embodied Navigation
人们对研究具体环境中的室内导航越来越感兴趣[14]。这主要归功于由 3D 室内环境 [8, 36, 31] 组成的大规模数据集,以及允许研究人员在这些 3D 环境中模拟导航的模拟器 [35, 36, 21]。
为了研究具身人工智能,提出了许多任务[1],包括:PointGoal 导航[42]、ObjectGoal 导航[4]、具身问答[41]以及视觉和语言导航(VLN)[2, 22]。
为了解决代理在静态、单代理环境中运行的这些问题,提出了模块化方法 [7,10,9,32],利用 SLAM、路径规划和探索策略以及端到端 RL 训练策略[40,27,45,6,46],没有利用任何显式地图。
Socially-Aware Navigation
无碰撞多智能体导航 [5, 39, 13, 23] 和动态环境中的导航 [3] 的工作已扩展到有人在场的情况下的导航 [19, 16, 12, 24, 11]。
Chen 等人 [12] 采用 CADRL [13] 等防撞算法,并引入常识性社会规则来减少不确定性,同时最大限度地降低发生冻结机器人问题 [38] 的风险。
其他工作 [16, 11] 尝试使用时空图 [24] 等技术来模拟人机交互。这些方法通常在极简模拟环境中进行了测试,这些模拟环境提供了具有简单障碍的完整知识,并且通常假设移动代理之间进行协作。
Egocentric Visual SocialNav
越来越多的工作开始研究以自我为中心的视觉数据的 SocialNav。
大规模以自我为中心的社交合规演示数据集 [20] 和智能体在社交环境中导航的轨迹 [34, 25] 使得能够通过模仿学习来训练社交导航智能体。
尽管如此大的数据集很有用,但在模拟中训练智能体仍然很有用,这样就可以观察现实世界中不易收集的极端情况。通过模拟,代理通常使用模仿学习 [37]、端到端强化学习 [47] 或规划器与 RL [29] 的组合进行训练。
Evaluation of SocialNav
SocialNav [17] 之前的工作通常使用总体成功率、路径效率、避免碰撞或与人类路径的相似性来评估。
成功率是有限的,因为代理正在与人类打交道,最好安全导航以避免碰撞,即使这意味着成功率较低。
在 iGibson 挑战中,SocialNav 还使用 STL(按时间长度加权的成功)和 PSC(个人空间合规性)进行评估,即代理与行人距离超过阈值距离 (0.5m) 的时间步百分比。
与这些指标相反,我们根据代理与行人的遭遇类型提出了细粒度的评估。
Background:the SocialNav Task
在 Embodied Social Navigation [44,29,47] 中,与 PointGoal Navigation 一样,智能体的目标是到达目标位置,但与人类主体的碰撞构成失败,并将终止该情节。
情节 e e e 由代理轨迹 α α α、人类轨迹元组 ( p i p^i pi) 和目标 g g g 来表征。智能体轨迹 α α α 是智能体从情节趋势开始到结束的一系列位置和旋转。形式上, α = { α t } t ∈ [ 0 , t e n d ] α = \{α_t\}_{t∈[0,t_{end}]} α={ αt}t∈[0,tend],其中 α t ∈ S E ( 2 ) α_t ∈ SE(2) αt∈SE(2) 是智能体在时间 t t t 相对于原点的 2D 平移和旋转。
类似地,同一情节中人类的轨迹是与第 i 个人类相关的位置和旋转序列。形式上, p i = { p t i } t ∈ [ 0 , t e n d ] ∀ i ∈ P p^i = \{p^i_t\}_{t∈[0,tend]} ∀i ∈ P pi={ pti}t∈[0,tend]∀i∈P 且 p t i ∈ S E ( 2 ) p^i_t ∈ SE(2) pti∈SE(2)。在我们的模拟中,每个人的移动都受到起点和终点的限制,人沿着最短路径在这两点之间来回移动。
目标 g ∈ G g ∈ G g∈G 由世界坐标中的 2D 位置指定。智能体必须在任意时间点提供一个动作 (lin vel, ang vel) ∈ [ − 1 , + 1 ] 2 \in [−1, +1]^2 ∈[−1,+1]2,表示归一化的线性前进速度和归一化的顺时针旋转角速度(其中 +1 是最大速度, -1 最大向后/逆时针速度)。当代理距离目标目标点 0.2 米以内时,将调用停止操作。代理有 500 个动作(或步骤)来到达目标位置。如果它与人类相撞,情节会立即终止。
Method
图 2 显示了我们的框架的轮廓。
它包括两个主要模块:(i)邻近特征提取,以及(ii)策略架构。邻近特征提取模块细化从模拟器获得的邻近信息,以提取描述社交交互某些方面的特征(地面真实邻近特征)。
策略架构从 RGB-D 和 GPS+Compass 传感器中提取嵌入,作为我们的邻近感知任务的输入。这些任务完善了这种嵌入并创建了 n 个任务嵌入(每个任务一个),然后通过状态注意力将其融合在一起。动作是从状态注意力输出中采样的。
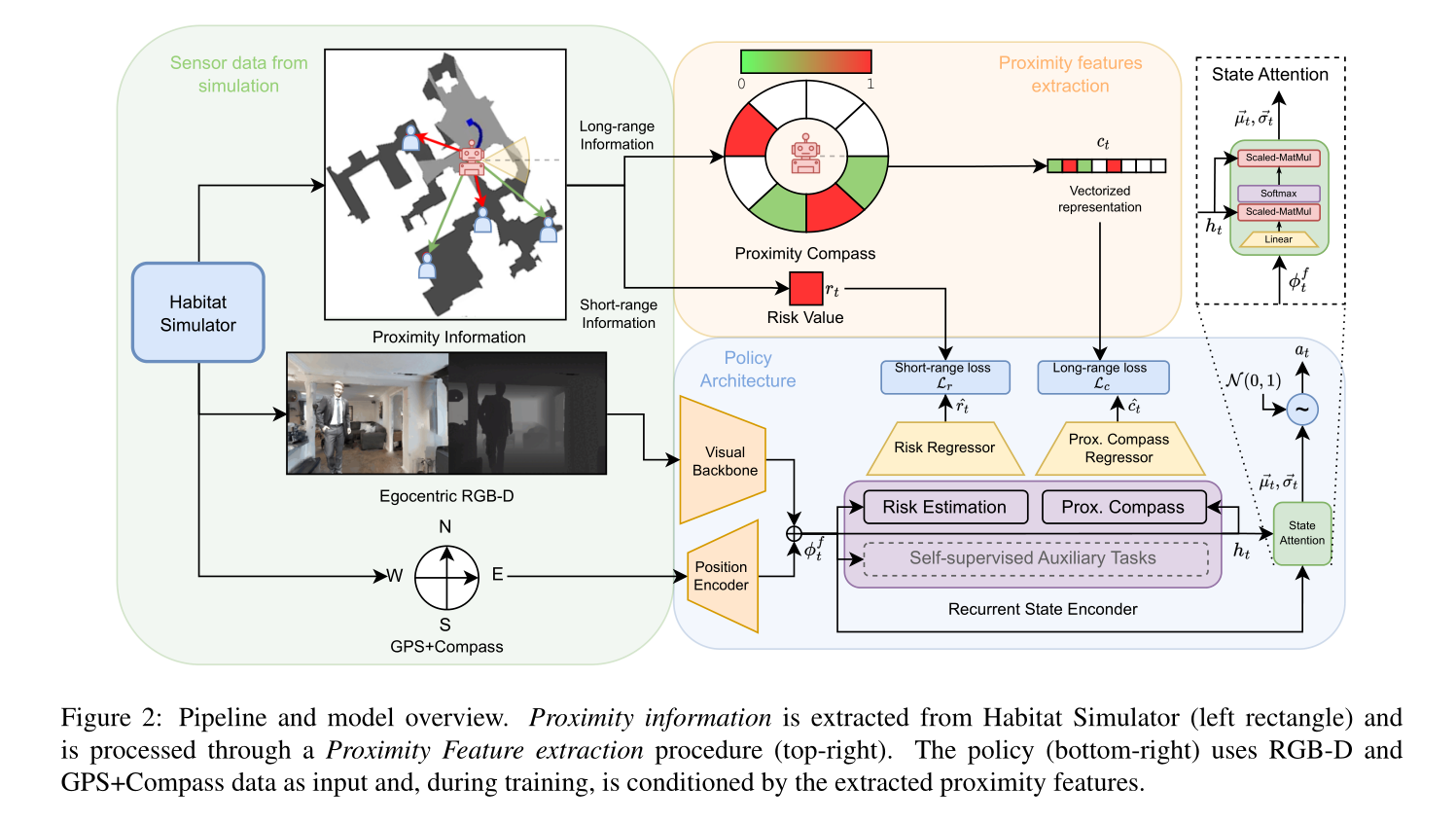
Policy Architecture
我们的策略网络包含以下模块:
i)两个编码器(视觉主干和位置编码器),用于从 RGB-D 和 GPS+罗盘传感器创建嵌入;
ii) 循环状态编码器,通过一系列循环单元累积这种嵌入;
iii) 状态注意力模块,通过注意力机制融合这些单元的输出,以产生机器人必须执行的动作。
我们使用 CNN(视觉主干) f ( ⋅ ) f(·) f(⋅) 将每个 RGB-D 帧 x t x_t xt 编码为视觉嵌入 ϕ t v = f ( x t ) \phi ^v_t = f(x_t) ϕtv=f(xt)。使用线性层 g ( ⋅ ) g(·) g(⋅) 对主体 α t α_t αt 的位置和旋转进行编码,以获得嵌入 φ t p = g ( α t ) φ^p_t = g(α_t) φtp=g(αt)。然后将这两个编码器的输出连接成最终的嵌入 ϕ t f = ϕ t v ⊕ ϕ t p \phi ^f_t = \phi ^v_t ⊕ \phi ^p_t ϕtf=ϕtv⊕ϕtp 。
为了随着时间的推移积累嵌入,我们遵循 Y e 等人 [45] 的 PointNav 设计,并将我们的状态编码器实现为一堆并行循环单元。每个时间步的每个单元都会被输入 ϕ t f \phi ^f_t ϕtf ,并输出其内部状态,称为信念 b e l i e f belief belief。
拥有多个 b e l i e f belief belief 的关键思想是每个循环单元都可以专注于特定的导航方面。
关于机器人应该采取什么行动的最终决定是通过根据情况对每个信念进行加权来采样的。因此,所有信念 B B B 随后通过状态注意力模块融合,以计算我们对动作进行采样的正态分布的平均值 µ t ⃗ \vec {µ_t} µt 和标准差 σ t ⃗ \vec {σ_t} σt。
形式上,给定 { R U ( i ) } ∀ i ∈ B \{RU^{(i)}\}_{∀i∈B} { RU(i)}∀i∈B 一组循环单元,编码置信 h t h_t ht 定义为:

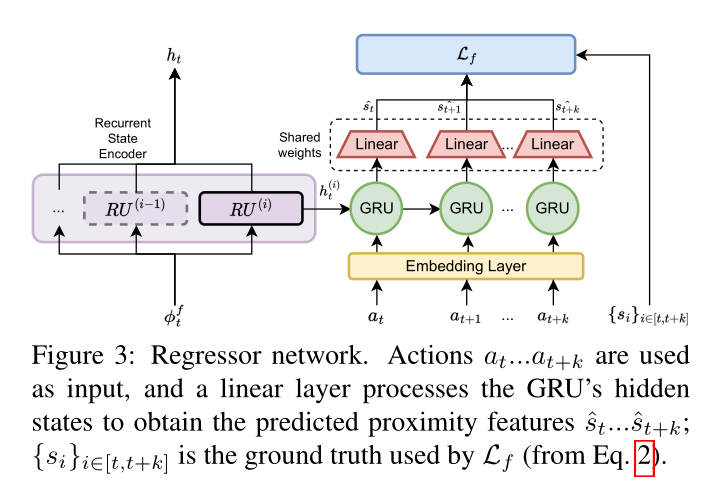
Proximity-Aware Tasks
有了多种信念,我们可以在嵌入中注入不同的信号,例如,某一集中发生的社会动态。
为此,在训练期间,我们用独特的辅助损失来调节每个信念,并在策略网络的优化步骤中与行动和价值损失联合优化。
这是通过回归器网络(见图 3)使用特定类型的邻近特征处理每个信念来完成的,该网络计算我们的邻近感知任务预测。每个辅助任务负责预测时间范围 [ t , t + k ] [t, t+k] [t,t+k] 内的邻近特征,以相应的信念 h(i) t 和执行动作的序列 { a j } j ∈ [ t , t + k ] \{a_j\}_{j∈[t,t+k]} {
aj}j∈[t,t+k] 为条件,其中 k 是要预测的未来帧的数量。形式上,对于给定的邻近特征序列 { s j } j ∈ [ t , t + k ] \{s_j\}_{j∈[t,t+k]} {
sj}j∈[t,t+k],该任务旨在优化以下辅助损失:

我们设计了两种类型的邻近任务,对应于两个社交特征:
(i)风险估计
(ii)邻近指南针
我们的设计的优点是可以轻松扩展其他可能更复杂的社交任务,并且还可以与 Y e 等人 [45] 中使用的通用自我监督任务兼容(例如,CPC|A [18]或 ID [28, 46])。为了利用不同的邻近特征,我们从模拟器中提取每个人的相对位置。中介。我们将此数据称为邻近信息:
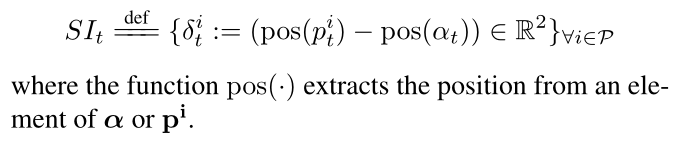
Risk Estimation
风险估计是一项邻近感知任务,旨在处理短距离社交互动,以告知代理即将发生的碰撞危险。
给定 S I t SI_t SIt,我们将 Risk 值定义为一个标量,表示智能体与最近的人在最大距离 D r D_r Dr 内的距离有多近。该值的范围从 0(最近的邻居比 D r D_r Dr 远米远)到 1(智能体和最近的人距离 D r D_r Dr 还远)。人发生碰撞)。表示为:
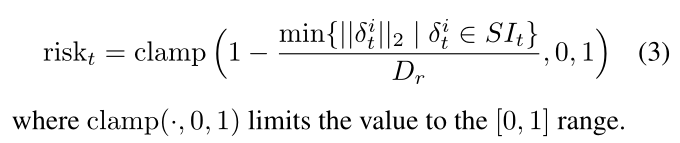
Proximity Compass
邻近感知任务对社会动态的远距离部分进行建模。该特征不仅捕获了半径 D c > D r D_c > D_r Dc>Dr 的更大区域内的社交互动,而且还捕获了一个人可能来的方向的微弱指示。就像人类可以根据之前的观察、对环境的部分了解以及人的轨迹来猜测人的行踪一样;我们希望我们的代理在训练时获得类似的知识
此类信息通过邻近指南针来表示。在罗盘中,北代表代理所看的方向,并且象限被划分为有限数量的不重叠的扇区。给定每个人 i ∈ P , θ a → i i ∈ P,θ_{a→i} i∈P,θa→i 表示连接智能体与该人的线段的角度。指南针的北边。这些角度与特定扇区相关。我们计算同一象限人群中每个部门的风险值。整个罗盘通过从北向顺时针展开扇区序列来表示为矢量。形式上,如果我们有 k k k 个等效扇区,则向量 c o m p t ∈ R k comp_t ∈ R^k compt∈Rk 定义为:
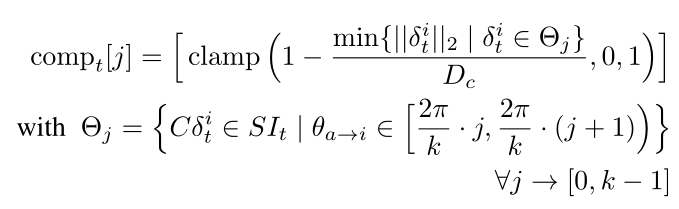
Implementation details
我们实验中使用的视觉主干是针对 RGB-D 帧的 ResNet-18 的修改版本。我们使用[47]中使用的相同实现;这会产生大小为 512 的输出嵌入。对于代理的位置编码器,我们使用输出大小为 32 的线性层。我们的循环状态编码器被实现为单层 GRU 堆栈,每个隐藏维度为 512。两个邻近任务的回归器均实现为隐藏大小为 512 的单层 GRU。动作序列 { a i } i ∈ [ t , t + k ] \{a_i\}_{i∈[t,t+k]} {
ai}i∈[t,t+k] 通过嵌入层,然后馈送到 GRU 的输入。初始隐藏状态初始化为 h t ( i ) h^{(i)}_t ht(i) ,k 设置为 4。完整方案请参见图 3。
每个模型都使用 DD-PPO [42] 算法在 3 个 GPU Nvidia A5000 上进行训练,每台机器有 8 个并行环境。我们的奖励函数如下

An evaluation protocol for SocialNav
我们引入了一种评估协议来分析导航代理在 SocialNav 任务上的性能。我们将代理与环境中其他行人之间的遭遇分为四类(正面、交叉口、盲角、跟随者),并提出一组指标来分析不同类型的遭遇。
Encounter
我们将在情节 e e e 中发生在智能体和特定行人之间的遭遇正式定义为给定时间范围 [ t 1 , t 2 ] ⊆ [ 0 , t e n d ] [t_1, t_2] ⊆ [0, t_{end}] [t1,t2]⊆[0,tend]内轨迹 α α α 和 p i p^i pi 的子序列,以满足以下约束:
• Time Constraint:时间范围 [ t 1 , t 2 ] [t_1,t_2] [t1,t2]大于阈值 T m i n T_{min} Tmin;
• Spatial Constraint:智能体与人之间的测地距离 i ∀ t ∈ [ t 1 , t 2 ] i ∀t ∈ [t_1, t_2] i∀t∈[t1,t2] 小于阈值 D m a x D_{max} Dmax;
• Haeding Constraint:在第一个 T f r o n t T_{front} Tfront 时间步中,人 i i i 位于代理前面。也就是说,给定智能体的航向角 θ t a θ^a_t θta , θ t a → i θ^{a→i}_t θta→i 连接智能体与人 i 的线段角度和阈值 θ m a x , ∣ θ t a − θ t a → i ∣ ≤ θ m a x θ_{max},|θ^a_t - θ^{a→i}_t | ≤ θ_{max} θmax,∣θta−θta→i∣≤θmax 满足 ∀ t ∈ [ t 1 , t 1 + T f r o n t ] ∀t ∈ [t_1, t_1 + T_{front}] ∀t∈[t1,t1+Tfront]。
Inclusion rule
为了描述智能体和人类之间的遭遇,我们设计了一种称为包含规则(inclusion rule, IR)的启发式方法。
每个 IR 由以下参数定义:
• Δ t i 、 Δ t a Δ^i_t、Δ^a_t Δti、Δta 分别表示在时间范围 [ t 1 , t ] [t_1, t] [t1,t] 内智能体和人 i 的轨迹大致方向的近似值,其中 t ∈ [ t 1 , t 2 ] t ∈ [t_1, t_2 ] t∈[t1,t2],其中 t 1 、 t 2 t_1、t_2 t1、t2 是遭遇的开始和结束时间步;
• i n t e r s e c t intersect intersect 是一个二进制值,如果机器人和行人路径相交,则为 1,否则为 0;
• b l i n d ( t ) blind(t) blind(t) 是一个时间条件的二进制值,指示智能体在时间步 t 是否可以看到该人;
• d _ d i f f ( t ) d\_diff(t) d_diff(t):代理与人之间的测地距离和欧氏距离之间的差异
Encounter classification
我们定义了四类遭遇(受到 Pirk 等人[30]的启发),以及它们各自的包含规则(见图 4):
• 正面接近(Frontal approach ):机器人和人类来自相反的方向,并且具有大致平行的轨迹。因此,代理应稍微偏离以避免正面碰撞。 I R : ( ¬ b l i n d ( t ) ∀ t ∈ [ t 1 , t 1 + T v i e w ] ) ∧ π − Δ s l a c k ≤ ∣ Δ t 2 i − Δ t 2 a ∣ ≤ π + Δ s l a c k IR: (\neg blind(t) ∀t ∈ [t_1, t_1 + T_{view}]) ∧ π − Δ_{slack} ≤ |Δ^i_{t2} − Δ^a_{t2}| ≤ π+Δ_{slack} IR:(¬blind(t)∀t∈[t1,t1+Tview])∧π−Δslack≤∣Δt2i−Δt2a∣≤π+Δslack,其中 Δ s l a c k Δ_{slack} Δslack 是角度 π 上的松弛值(以弧度为单位), T v i e w T_{view} Tview 是代理必须看到该人的初始时间步数。
• 相交(Intersection):机器人和人的轨迹相交约90°。在这种情况下,智能体可能想要停下来并让位于人类,或者降低其线速度并稍微偏离。 I R : ( ¬ b l i n d ( t ) ∀ t ∈ [ t 1 , t 1 + T v i e w ] ) ∧ π 2 − Δ s l a c k ≤ ∣ Δ t 2 i − Δ t 2 a ∣ ≤ π 2 + Δ s l a c k ∧ i n t e r s e c t IR: (\neg blind(t) ∀t ∈ [t_1, t_1 + T_{view}]) ∧ \frac{π}{2} − Δ_{slack} ≤ |Δ^i_{t2} − Δ^a_{t2}| ≤ \frac{π}{2} + Δ_{slack} ∧ intersect IR:(¬blind(t)∀t∈[t1,t1+Tview])∧2π−Δslack≤∣Δt2i−Δt2a∣≤2π+Δslack∧intersect 。
• 盲角(Blind Corner):特工从最初被遮挡的位置(例如角落或狭窄的门口)接近人员。在能见度如此有限的情况下,特工应谨慎行事,以避免发生碰撞。 I R : ( b l i n d ( t ) ∀ t ∈ [ t 1 , t 1 + T b l i n d ] ) ∧ d _ d i f f ( t 1 ) ≤ 0.5 IR: (blind(t) ∀t ∈ [t_1, t_1 + T_{blind}]) ∧ d\_ diff(t_1) ≤ 0.5 IR:(blind(t)∀t∈[t1,t1+Tblind])∧d_diff(t1)≤0.5 其中 T b l i n d T_{blind} Tblind 是代理不能看到该人的初始时间步数。
• 跟随人员(Person following):人和代理朝同一方向行驶。代理必须与人保持安全距离和相对较低的线速度。 I R : ( ¬ b l i n d ( t ) ∀ t ∈ [ t 1 , t 1 + T b l i n d ] ) ∧ ∣ Δ t 2 i − Δ t 2 a ∣ ≤ Δ s l a c k IR: (\neg blind(t) ∀t ∈ [t_1, t_1 + T_{blind}]) ∧ |Δ^i_{t2} − Δ^a_{t2}| ≤ Δ_{slack} IR:(¬blind(t)∀t∈[t1,t1+Tblind])∧∣Δt2i−Δt2a∣≤Δslack
Metrics
对于每个遭遇类别,我们评估:
• 遭遇生存率 (Encounter Survival Rate, ESR) 是没有人类碰撞的遭遇(在特定类别中)的百分比(例如,如果在盲角遭遇,代理在 20% 的时间内与人类发生碰撞的情况下,ESR将为80%);
• 平均线速度(Average Linear-Velocity, ALV)是智能体在一次遭遇中的平均线速度;
• 平均距离 (Average Distance, AD) 是代理相对于相遇中的人类的平均距离。
Experiment
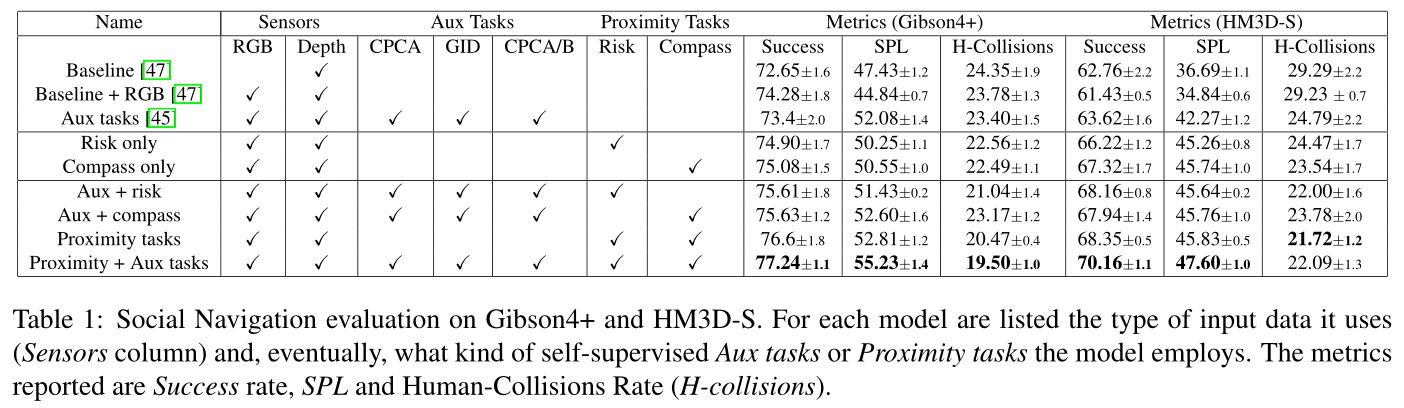
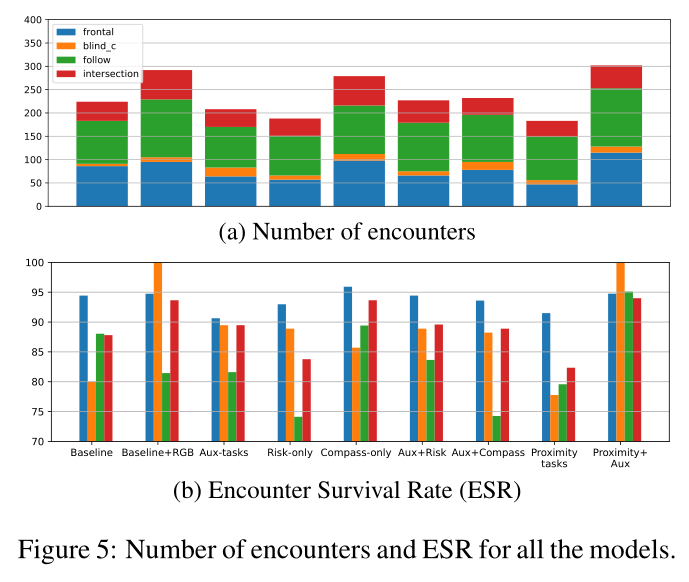
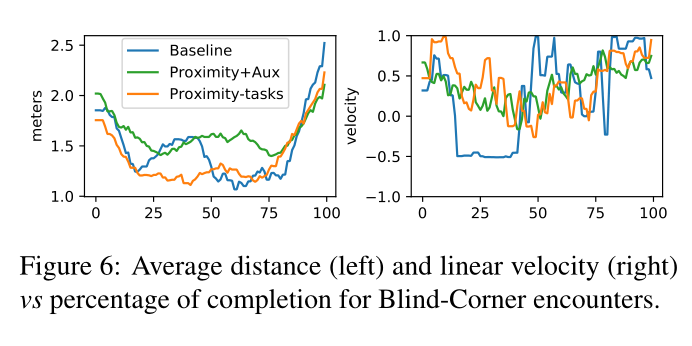

Conclusion
我们引入了基于两个邻近感知任务的体现社交导航模型。
我们的实验表明,单独利用社交信号或与自我监督的辅助任务相结合,在复杂和拥挤的场景中是一种有效的策略。
我们的模型可以通过仅使用邻近感知任务来避免大多数遭遇。
此外,通过结合邻近感知和辅助任务[45],它可以在几乎所有遭遇类别中以高置信度防止人类碰撞,尽管碰撞类别的数量有所增加。
在我们未来的工作中,我们将专注于模拟更自然的人类行为,我们将在 sim2real 域传输上进行实验