这里是监督学习第二课!
参考书目,chapter 2 and 3 of kernel methods for Pattern analysis
Overview 概述
我们会展示线性方法是如何被拉到一个更高的维度空间,然后提供非线性回归。
特征映射就是一个把输入映射到新空间的映射
这样我们就可以让这个方法相对于原输入非线性,对于映射后的特征线性。
直接的特征映射也叫 基底函数方法
隐性的特征映射也叫核映射。
我上一篇博客已经讲了线性系统求解。
Xw = y
这里X是m *n的大小。
如果mn一样大,w就有唯一解,否则这个问题就叫ill-posed。
有ill -posed就有well -posed。对于一个问题
若存在一个解
这个解是唯一的
解永远由数据决定。
也就是说,如果不是well-posed,那就是ill-posed。
那么如何解决ill posed呢?也就是如何解决解不唯一的问题 ?或者是没有解的问题?
岭回归 ridge regression
我们已经知道如果有假设空间,我们可以用交叉验证来选择假设class。
另一种方法是,我们可以修改误差函数,添加一个复杂度式子。
这个方法也叫做正则化regularization
(说了这么多废话终于可以讲岭回归了)

我们发现其实新的loss function就是原来的loss function加上一个新的term。这个term就是用来限制复杂度的。
因为一些原因,w的参数可以决定复杂度。所以这个新的项term 就是 wTw,也就是w与自己的内积。然后这个长得跟入一样的系数就是表示复杂度的重要性。
因为原来的loss function中没有复杂度,所以入为0.也就是说,入越趋近于0,复杂度越不重要(较少考虑复杂度对loss的影响)
dual representation对偶表达
这个比较难理解,其实就是说如果把w换一种写法是什么样。中间的证明我略过了,有兴趣可以知乎搜一下。其实不是很重要。

我们可以看出w从原来的式子变成了一个累加的项也就是xi的线性组合。然后α的表达式和原来的w有一些类似。
但是XTX 变成了XXT。
在这个过程中什么变了呢??是维度!维度就是矩阵的大小。在计算w的过程中,最大的开销是求逆矩阵。这个开销是n的3次方。(假设矩阵是n *n的方阵)
所以我们发现,随着XTX 改为XXT,两个矩阵的大小改变了,假设X是m*n的。那么
XTX = n*m * m * n = n*n
而XXT = m * n*n *m = m * m
m是样本的数量,也就是有多少个数据点,n是数据的维度。
所以,根据维度和样本数量的大小关系,我们可以选择适合的w的表达。从而减少计算开销。
如果m<n ,那么用dual方法会更有效率。
也就是样本数量小于维度。
这里有一个问题,如果样本还没有维度多,怎么可能计算出w?
对!所以我们用的是ridge regression。在这种情况下,w是一个估计值,我们尽可能的限制w的复杂性,这同样也是我们为什么必须使用ridge regression的原因。
basis function
现在讨论如何把输入就进行显性 映射 ,也就是basis function,基底函数。
这个很难解释,举个例子,如果我们现在有长和宽两个数据。我们要预测房子的价格。最简单的方法是用基底函数。
如果只在原来的的数据预测价格。我们知道房价和面积有线性关系。但这里没有面积这个数据。那么很可能我们的模型误差非常大(因为模型本身就是错误的)。
如果使用basis function,我们可以把长宽变成 长宽面积。 n =2 -> n = 3
这样多了一个维度的数据,我们就可以拟合这个数据了。
另外一个例子是xor问题。input 是2维的。然后我们知道对于分类问题,一个线性模型实际上是一条线,分割一个平面。把平面分成两个区域对应两个分类。
但实际上。不可能存在这样的线。
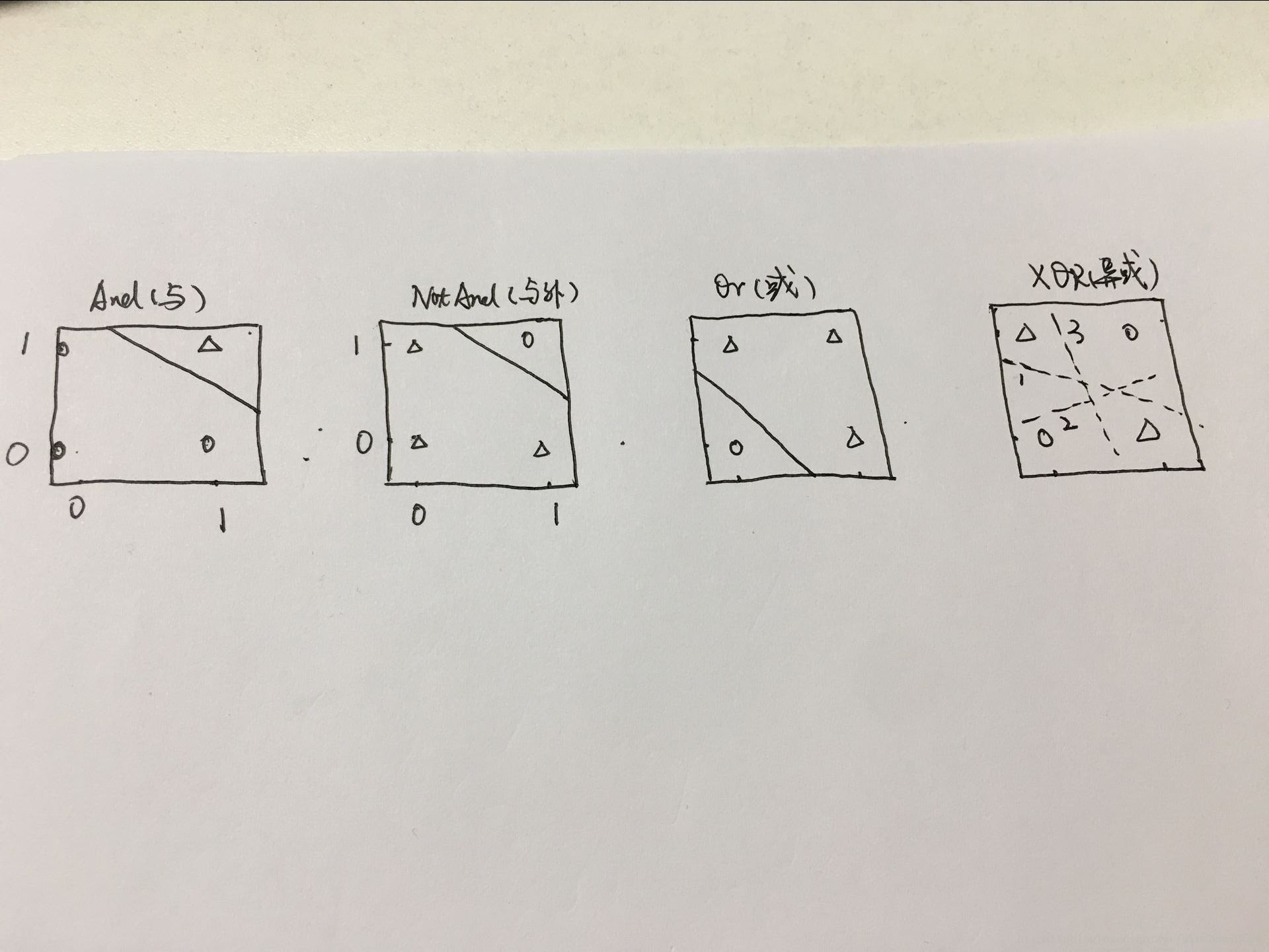
基底定义。




如果把XOR问题的x1 x2 变成x1 x2 x3,这样我们就可以把这个空间(平面)分开。
这里x3 就是x1和x2 的乘积。我们可以发现当x1 x2值不一样的时候,他们的成绩为-1 ,反之为1。
Kernel 函数 (隐性映射)
什么是kernel函数呢?
如果我们确定了前面的基函数,就等于确定了一个kernel函数,这个函数就是两个 数据点(x和t)经过基函数变换后的点积或内积。

问题:核函数有什么用?
我们可以利用核函数将原来的w表达式再次改写。而不同的核函数暗示着不同的特征映射。意味着我们可以对原数据进行一定的特征工程和高维映射。而我们不需要知道对应的basis function是什么样的。

我们发现kernel的回归也是dual 表达。这是因为K的大小是m * m,这表示依赖于样本数,如果我们依赖于维度,很可能这个维度非常大,例如高斯核是无限维的,还有多项式核的维度也非常大。
到此为止,核函数也讲完了。当然了,课件上还有很多数学推导都被我略过了,这部分过于复杂。有兴趣的朋友可以留言我们讨论一下。
核函数的描述网上特别少,大部分都是直接配合SVM。但是其实svm和核函数是互相独立的。
kernel函数有时候还被当成滤波,大家不要弄混了,虽然这两个东西差不多
顺便推荐林轩田的机器学习课程。(b站就有)。