本章实战目的是,对用户的历史定位数据,采用数据挖掘技术对基站进行分群并对不同的商圈分群进行特征分析,以选取合适的商圈进行促销。所选用的方法是聚类。
本文分为以下几个部分:
- 离差标准化
- 模型构建
- 模型分析
- 总结
离差标准化
由于各个属性之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行归一化处理。本文选择离差标准化。
代码如下:
#-*- coding: utf-8 -*-
#数据标准化到[0,1]
import pandas as pd
#参数初始化
filename = 'D:/ProgramData/PythonDataAnalysiscode/chapter14/demo/data/business_circle.xls' #原始数据文件
standardizedfile = 'D:/ProgramData/PythonDataAnalysiscode/chapter14/demo/data/standardized.xls' #标准化后数据保存路径
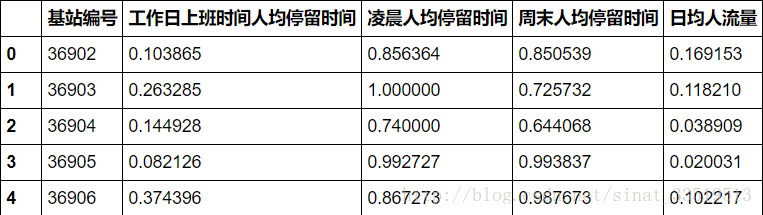
data = pd.read_excel(filename, index_col = u'基站编号') #读取数据
data = (data - data.min())/(data.max() - data.min()) #离差标准化
data = data.reset_index()
data.to_excel(standardizedfile, index = False) #保存结果标准化之后的结果如下:
模型构建
数据经过预处理之后,可以作为建模数据。
本文采用层次聚类算法对数据进行商圈聚类。层次聚类与K-means不同,层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
其中,自底向上的策略先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数;自顶向下的策略,先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。常用的为自底向上策略。层次聚类具体例子可参考周志华《机器学习》中第九章的层次聚类。
首先,画出谱系聚类图。
代码如下:
#-*- coding: utf-8 -*-
#构建商圈聚类模型
#谱系聚类图
import pandas as pd
#参数初始化
standardizedfile = 'D:/ProgramData/PythonDataAnalysiscode/chapter14/demo/data/standardized.xls'
data=pd.read_excel(standardizedfile,index_col=u'基站编号')
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram#scipy层次聚类函数
z=linkage(data,method='ward',metric='euclidean')#谱系聚类图
p=dendrogram(z,0)
plt.show()谱系聚类图如下:
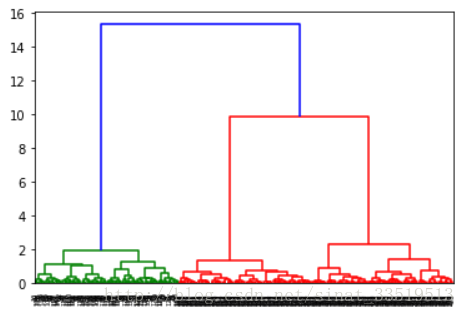
由图可以看出,可以把聚类类别分为3类。
书中的层次聚类算法是sklearn.cluster中的AgglomerativeClustering,但之前做的时候好像这边导入有问题(现在用python3.5是正常的),所以换成了scipy.cluster.hierarchy中的层次聚类。
层次聚类算法如下:
#-*- coding: utf-8 -*-
#层次聚类算法
import pandas as pd
#参数初始化
standardizedfile = 'D:/ProgramData/PythonDataAnalysiscode/chapter14/demo/data/standardized.xls'
data=pd.read_excel(standardizedfile,index_col=u'基站编号')
#由谱系聚类图可得类别数可取3
k=3
#from sklearn.cluster import AgglomerativeClustering#导入层次聚类函数
#model=AgglomerativeClustering(n_clusters=k,linkage='ward')
#model.fit(data)#训练模型
import scipy.cluster.hierarchy as hcluster #导入scipy的层次聚类函数
y_pred=hcluster.fclusterdata(data.iloc[:,:4],criterion='maxclust',t=k)
#详细输出原始数据及其类别
#r=pd.concat([dara,pd.Series(model.lables_,index=data.index)],axis=1)#详细输出每个样本对应的类别
r=pd.concat([data,pd.Series(y_pred,index=data.index)],axis=1)
r.columns=list(data.columns)+[u'聚类类别']#重命名表头
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#正常显示中文
plt.rcParams['axes.unicode_minus']=False#正常显示负号
style=['ro-','go-','bo-']#设置样式
xlabels=[u'工作日人均停留时间',u'凌晨人均停留时间',u'周末人均停留时间',u'日均人流量']#X轴标签
pic_output='D:/ProgramData/PythonDataAnalysiscode/chapter14/demo/type_'#图片输出前缀设置
#逐一作图,作出不同样式
for i in range(1,k+1):
plt.figure()
tmp=r[r[u'聚类类别']==i].iloc[:,:4]
for j in range(len(tmp)):
plt.plot(range(1,5),tmp.iloc[j],style[i-1])
plt.xticks(range(1,5),xlabels,rotation=20)
plt.title(u'商圈类别%s'%(i))
plt.subplots_adjust(bottom=0.15)#调整底部
#plt.show()
plt.savefig(u'%s%s.png'%(pic_output,i))#保存图片输出每一个商圈类别的特征图如下:

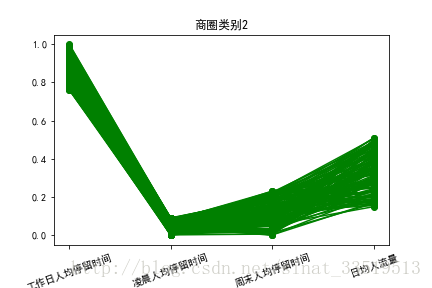
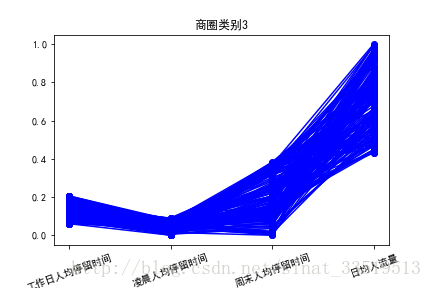
类别分析
针对上述三个图的特点进行分析,发现,对于商圈类别1,凌晨人均停留时间和周末人均停留时间较长,而工作日人均停留时间较短,日均人流量较少,此类别基站覆盖的区域类似于住宅区;对于商圈类别2,工作日人均停留时间较长,同时凌晨人均停留时间和周末人均停留时间较短,此类别基站覆盖区域类似于上班族的工作区域;对于商圈类别3,日均人流量较大,而工作日人均停留时间、凌晨人均停留时间和周末人均停留时间都较短,该类别基站覆盖区域类似于商业区。
对比而言,人流量最大的商圈类别3更有利于促销活动。
总结
本章内容中的原数据已经是处理好了的,数据预处理较为简单,主要收获是对层次聚类做了一个很好的实践,对其结果的价值也有了很好的了解。