决策树与随机森林讲解
文章目录
A–决策树:
(*)决策树的结构:

(*)决策树阶段:
训练阶段:

分类阶段:

(*)熵原理分析:
熵:物体内部的混乱程度。
(01)熵的计算式:
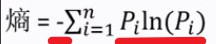
熵(n=i)的图像:

例如:

A={a,a,a,b,c}中的p(a)=3/5,p(b)=1/5,p©=1/5得到的熵:约为0.94
而B={c,c,c,c,b}中的p©=4/5,p(b)=1/5得到的熵:约为0.49
所以B的纯度更高。
解释:
当个体内部的元素类型越分散,p(i)的值越小,而熵的累加值越大;当个体内部的元素类型越集中,p(i)的值越大,而熵的累加值越小。
补充:
(02)Gini系数的计算式:
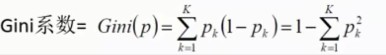
解释:
当个体内部的元素类型越分散,p(k)的值越小,而Gini系数越大;当个体内部的元素类型越集中,p(k)的值越大,而Gini系数越小。
(*)决策树实例-ID3算法-离散型数据处理:
(01)构造思想:
随着树深度的增加,节点的熵迅速降低,希望得到高度最矮的决策树。
(02)选定根节点:
1st:样本的分析:

原熵:根据"play"的记录不基于分类标签进行熵的计算,得到结果为:0.940。
**目标:基于不同的“label”进行“play”的预测。**根据现有的记录分别基于不同的Label得到以下划分:

然后针对不同的划分进行信息熵的计算:
outlook的熵计算过程:
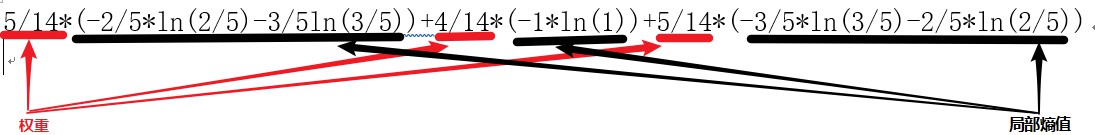
得到基于outlook分类的熵值为:0.693,信息增溢gain(look)=0.940-0.693=0.247。
同理,得到"label"对应的分类的信息增溢为:gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
通过对比**,基于“outlook”的分类的信息增溢最大,选取"outlook"作为根节点**。
(03)信息增溢率:
信息增溢率=信息增溢/基于label分类的熵值
(04)引入评价函数:
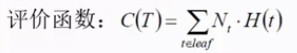
H(t)为当前叶子节点内所有样本的熵值,Nt为该叶子节点在所有叶子中的权重数(叶子节点的样本数),C(T)为所有叶子累加的熵值,C(T)越小,分类的结果相对越好。
补充:
C4.5算法-连续性数据处理:将连续型的数据值进行区间的划分。
(05)决策树的剪枝-防止“过拟合”风险:
样例:

剪枝方法:

预剪枝:通过控制决策次数,叶子样本数范围等设定边界值。
后剪枝:通过优化评价函数进行对每个节点的剪枝与否的结果进行评价。
(06)新的评价函数:

评价函数=代价函数+α*叶子节点数。(α为影响系数,当α↑,后者影响因素越大,应主要降低树的叶子节点数;而α↓,前者影响因素越大,叶子节点数相对不受限制。)
例如:

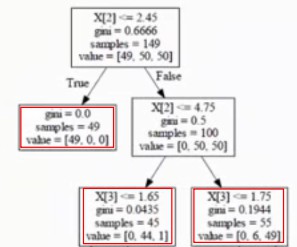
对当前节点进行分析:
若剪枝的 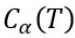 =0.5x100+1*α=50+α;
=0.5x100+1*α=50+α;
若不剪枝的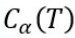 =(45x0.0435+55x0.1944)+2*α=12.62+2α;
=(45x0.0435+55x0.1944)+2*α=12.62+2α;
50+α<12.62+2α,则进行剪枝;50+α>12.62+2α,则不进行剪枝。
B-随机森林:
Bootstrapping:有放回采样
Bagging:有放回采样n个样本建立分类器
(*)双重随机:
(1)训练集随机(xx%),防止异常点。(2)特征集随机(xx%)。
C-决策树和随机森林的代码实现样例:
步骤:
(01)数据的导入:

(02)训练集的设置:
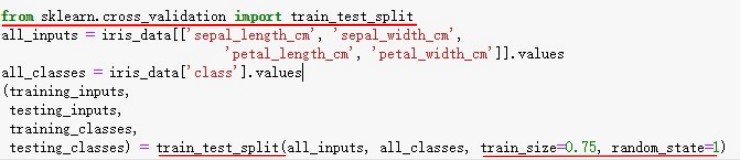
注:从sklearn.cross_validation库导入train_test_split函数,随机率为0.75,采用交叉验证。
(03)决策树容器的设置:
容器的属性( )
{ 1.criterion gini or entropy
2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分
如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被
剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起
被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,
或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。}
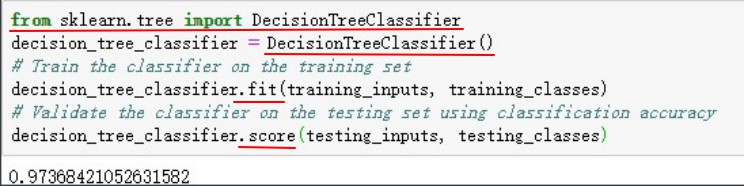
注:从sklearn.tree库导入DecisionTreeClassifier函数生成决策树容器,通道调用fit()和score()进行训练集的设置和训练精度的计算,采用classification accuracy精度。


注:采用交叉验证平均得分精度。
(04)参数调优:
网格搜索(Grid Search),探测整个范围内的参数,寻找表现最佳的参数组合。

