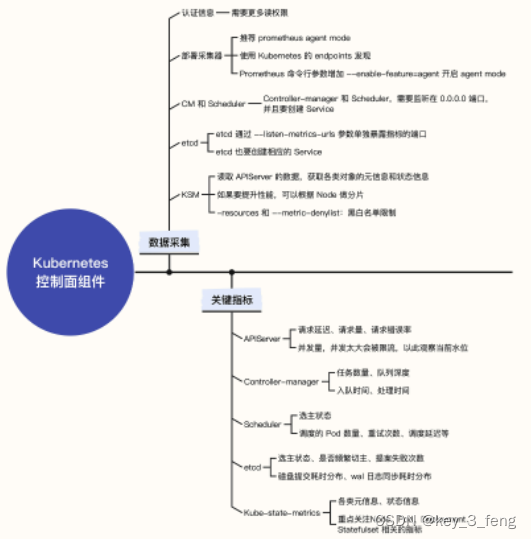
控制面组件的监控,包括 APIServer、Controller-manager(简称 CM)、Scheduler、etcd 四个组件。
1、APIServer
APIServer 的核心职能是 Kubernetes 集群的 API 总入口,Kube-Proxy、Kubelet、Controller-Manager、Scheduler 等都需要调用 APIServer,所以 APIServer 的监控,完全按照 RED 方法论来梳理即可,最核心的就是请求吞吐和延迟。
- apiserver_request_total:请求量的指标,可以统计每秒请求数、成功率。
- apiserver_request_duration_seconds:请求耗时的指标。
- apiserver_current_inflight_requests:APIServer 当前处理的请求数,分为 mutating(非 get、list、watch 的请求)和 readOnly(get、list、watch 请求)两种,请求量过大就会被限流,所以这个指标对我们观察容量水位很有帮助。
2、Controller-manager
Controller-manager 负责监听对象状态,并与期望状态做对比。如果状态不一致则进行调谐,重点关注的是任务数量、队列深度等。
- workqueue_adds_total:各个 controller 接收到的任务总数。
- workqueue_depth:各个 controller 的队列深度,表示各个 controller 中的任务的数量,数量越大表示越繁忙。
- workqueue_queue_duration_seconds:任务在队列中的等待耗时,按照控制器分别统计。
- workqueue_work_duration_seconds:任务出队到被处理完成的时间,按照控制器分别统计。
- workqueue_retries_total:任务进入队列的重试次数。
3、Scheduler
Scheduler 在 Kubernetes 架构中负责把对象调度到合适的 Node 上,在这个过程中会有一系列的规则计算和筛选,重点关注调度这个动作的相关指标。
- leader_election_master_status:调度器的选主状态,1 表示 master,0 表示 backup。
- scheduler_queue_incoming_pods_total:进入调度队列的 Pod 数量。
- scheduler_pending_pods:Pending 的 Pod 数量。
- scheduler_pod_scheduling_attempts:Pod 调度成功前,调度重试的次数分布。
- scheduler_framework_extension_point_duration_seconds:调度框架的扩展点延迟分布,按 extension_point 统计。
- scheduler_schedule_attempts_total:按照调度结果统计的尝试次数,“unschedulable”表示无法调度,“error”表示调度器内部错误。
4、etcd
etcd 在 Kubernetes 的架构中作用巨大,相对也比较稳定,不过 etcd 对硬盘 IO 要求较高,因此需要着重关注 IO 相关的指标,生产环境建议至少使用 SSD 的盘做存储。
- etcd_server_has_leader :etcd 是否有 leader。
- etcd_server_leader_changes_seen_total:偶尔切主问题不大,频繁切主就要关注了。
- etcd_server_proposals_failed_total:提案失败次数。
- etcd_disk_backend_commit_duration_seconds:提交花费的耗时。
- etcd_disk_wal_fsync_duration_seconds :wal 日志同步耗时。
5、KSM
Kube-state-metrics 这个组件,采集的很多指标都只是充当元信息,单独拿出来未必那么有用,但是和其他指标做 group_left、group_right 连接的时候可能又会很有用。
- kube_node_status_condition:Node 节点状态,状态不正常、有磁盘压力等都可以通过这个指标发现。
- kube_pod_container_status_last_terminated_reason:容器停止原因。
- kube_pod_container_status_waiting_reason:容器处于 waiting 状态的原因。
- kube_pod_container_status_restarts_total:容器重启次数。
- kube_deployment_spec_replicas:deployment 配置期望的副本数。
- kube_deployment_status_replicas_available:deployment 实际可用的副本数。
此文章为8月Day11学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。