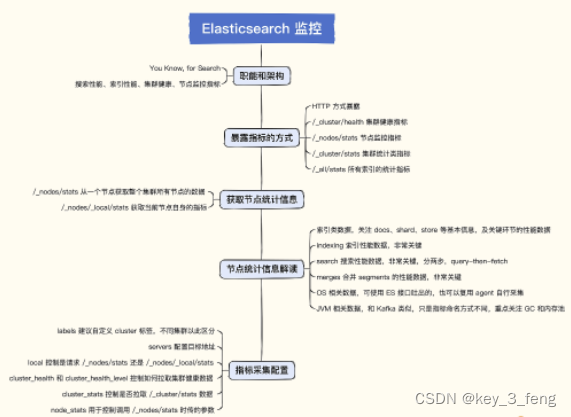
Elasticsearch 的核心职能就是对外提供搜索服务,所以搜索请求的吞吐和延迟是非常关键的,搜索是靠底层的索引实现的,所以索引的性能指标也非常关键,Elasticsearch 由一个或多个节点组成集群,集群自身是否健康也是需要我们监控的。
lasticSearch 的架构非常简单,一个节点就可以对外提供服务,不过单点的集群显然有容灾问题,如果挂掉了就万事皆休了。一般生产环境,至少搭建一个三节点的集群。

三个节点分别部署三个 Elasticsearch 进程,这三个进程把 cluster.name 都设置成相同的值,就可以组成一个集群。Elasticsearch 会自动选出一个 master 节点,负责管理集群范围内所有的变更,整个选主过程是自动的,不用我们操心。
架构图里绿色的 P0、P1、P2 表示三个分片,R0、R1、R2 代表分片副本,每个分片有两个副本,也就是说 P0 对应两个 R0,P1 对应两个 R1,P2 对应两个 R2。这些分片和副本是否成功分配到 Node 上并落盘写入,也是一个重要的监控指标。
索引部分是最关键的:
- docs 统计了文档的数量,包括还没有从段(segments)里清除的已删除文档数量。
- shard_stats 统计了分片的数量。
- store 统计了存储的情况,包括主分片和副本分片总共耗费了多少物理存储。
- indexing 是统计索引过程,ES 的架构里,索引是非常关键的一个东西,索引的吞吐和耗时都应该密切关注,index_total 和 index_time_in_millis 都是 Counter 类型的指标,单调递增。如果要求取最近一分钟的索引数量和平均延迟,就需要使用 increase 函数求增量。
- search 描述在活跃中的搜索(open_contexts)数量、查询的总数量,以及自节点启动以来在查询上消耗的总时间。
- fetch 统计值展示了查询处理的后一半流程,也就是 query-then-fetch 里的 fetch 部分。如果 fetch 耗时比 query 还多,说明磁盘较慢,可能是获取了太多文档,或者搜索请求设置了太大的分页。
- merges 包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。合并要消耗大量的磁盘 I/O 和 CPU 资源,如果 merge 操作耗费太多资源,也会被限制,即 total_throttled_time_in_millis 指标。
Elasticsearch 暴露指标的方式非常简单,就是几个 HTTP 接口,返回 JSON 数据,直接拉取解析即可,比 JMX 方式简单得多。我们要关注的核心是 /_cluster/health 和 /_nodes/stats 这两个接口,一个用来获取整个集群的监控数据,一个用来获取节点粒度的监控数据。 /_nodes/stats 接口返回的数据非常丰富,不但有索引类指标,还有 OS、JVM、Process、ThreadPool 指标,重点关注索引相关的指标和 JVM 相关的指标。
此文章为8月Day9学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。