大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用11-基于pytorch框架的卷积神经网络与注意力机制对街道房屋号码的识别应用,本文我们借助PyTorch,快速构建和训练卷积神经网络(CNN)等模型,以实现街道房屋号码的准确识别。引入并注意力机制,它是一种模仿人类视觉注意机制的方法,在图像处理任务中具有广泛应用。通过引入注意力机制,模型可以自动关注图像中与房屋号码相关的区域,提高识别的准确性和鲁棒性。
一、项目介绍
街道房屋号码识别是计算机视觉中的一个重要任务,通过对街道房屋号码的自动识别,可以对街道图像进行更好的理解和分析。本文将介绍如何使用PyTorch框架和注意力机制,结合SVHN数据集,来实现街道房屋号码的分类识别。
二、SVHN数据集
SVHN(Street View House Numbers)是一个公开的大规模街道数字图像数据集。该数据集包含了从Google Street View中获取的房屋门牌号码图像,可以用于训练和测试机器学习模型,以实现自动识别街道房屋号码的任务。
2.1 数据集下载和加载
首先,我们需要下载并加载SVHN数据集。在PyTorch中,我们可以使用torchvision库中的datasets模块来实现这一步。
数据集的下载与查看:
train_dataset = datasets.SVHN(root='./data', split='train', download=True)
images = train_dataset.data[:10] # shape: (10, 3, 32, 32)
labels = train_dataset.labels[:10]
images = np.transpose(images, (0, 2, 3, 1))
# Plot the images
fig, axs = plt.subplots(2, 5, figsize=(12, 6))
axs = axs.ravel()
for i in range(10):
axs[i].imshow(images[i])
axs[i].set_title(f"Label: {
labels[i]}")
axs[i].axis('off')
plt.tight_layout()
plt.show()
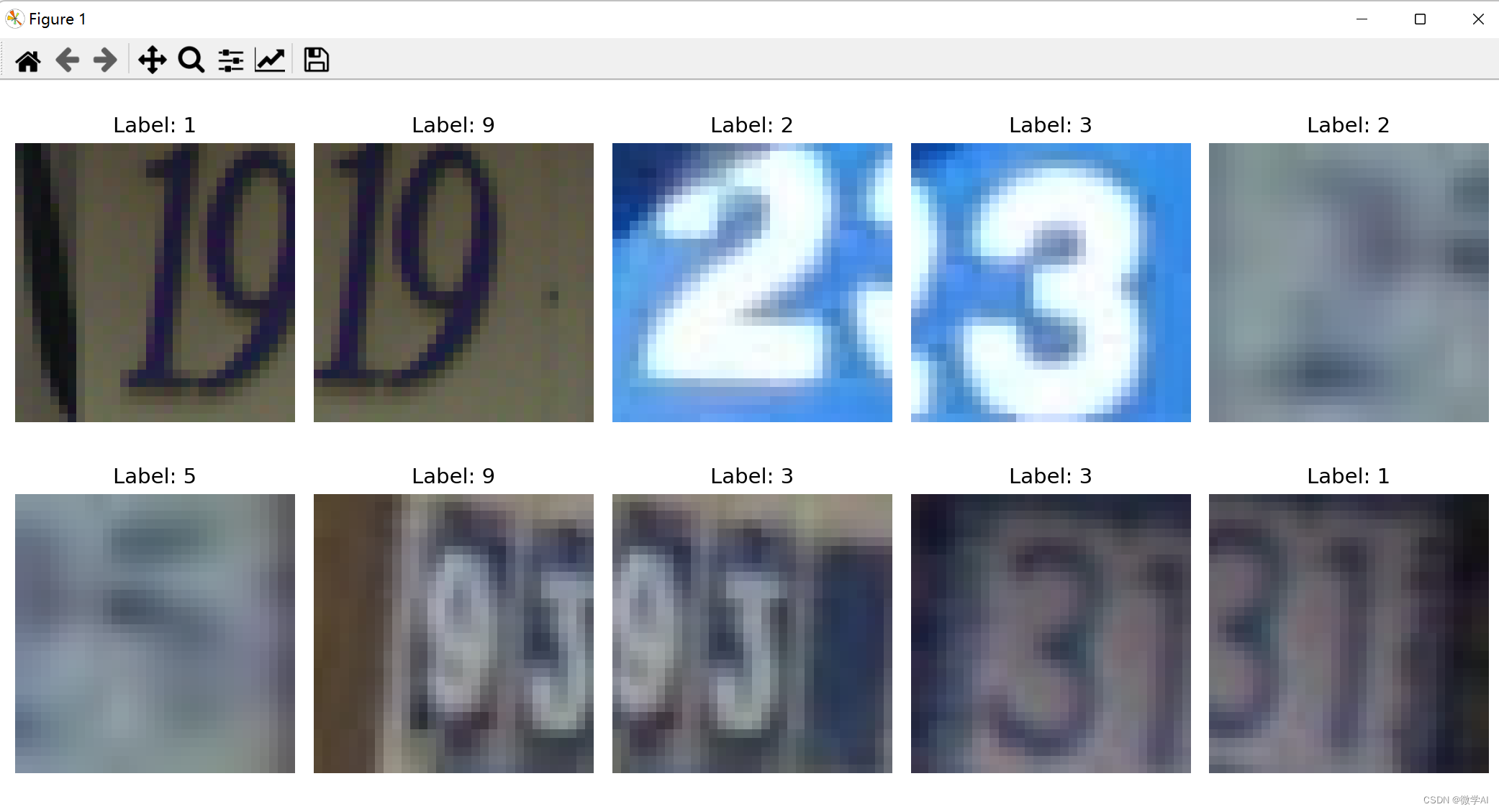
数据集的加载,预处理,便于输入模型训练:
import torch
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 下载并加载SVHN数据集
trainset = datasets.SVHN(root='./data', split='train', download=True, transform=transform)
testset = datasets.SVHN(root='./data', split='test', download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)
三、卷积网络搭建
使用PyTorch搭建卷积神经网络。卷积神经网络(Convolutional Neural Network, CNN)是一种主要用于处理具有类似网格结构的数据的神经网络,如图像(2D网格的像素点)或者文本(1D网格的单词)。
3.1 网络结构定义
下面是一个基础的卷积神经网络模型,包含两个卷积层、两个最大池化层和两个全连接层。
from torch import nn
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.drop_out = nn.Dropout()
self.fc1 = nn.Linear(7 * 7 * 64, 1000)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.drop_out(out)
out = self.fc1(out)
return self.fc2(out)
四、加入注意力机制
注意力机制是一种能够改进模型性能的技术。在我们的模型中,我们将添加一个注意力层来帮助模型更好地专注于输入图像中的重要部分。
4.1 注意力层定义
我将实现基本的注意力层,这个层将会生成一个和输入同样大小的注意力图,然后将输入和这个注意力图对应元素相乘,以此来实现对输入的加权。
注意力机制层的数学原理:
注意力机制的数学原理可以用以下公式表示:
给定输入张量 x ∈ R b × c × h × w x \in \mathbb{R}^{b \times c \times h \times w} x∈Rb×c×h×w,其中 b b b 是批量大小, c c c 是通道数, h h h 是高度, w w w 是宽度。注意力机制分为两个阶段:特征提取和特征加权。
1.特征提取阶段:
首先,通过自适应平均池化层(AdaptiveAvgPool2d)将输入张量 x x x 在高度和宽度上进行平均池化,得到形状为 b × c × 1 × 1 b \times c \times 1 \times 1 b×c×1×1 的张量 y y y。这里使用自适应平均池化是为了使得张量 y y y 在不同尺寸的输入上也能产生相同的输出。
2.特征加权阶段:
接下来,通过全连接层(Linear)和非线性激活函数ReLU对张量 y y y 进行特征变换,减少通道数,并保留重要特征。然后再通过另一个全连接层和Sigmoid激活函数得到权重张量 y ′ ∈ R b × c × 1 × 1 y' \in \mathbb{R}^{b \times c \times 1 \times 1} y′∈Rb×c×1×1,表示每个通道的权重值。这里的权重值在0到1之间,用于控制每个通道在后续的计算中所占的比重。将权重张量 y ′ y' y′ 扩展成与输入张量 x x x 相同的形状,并将其与输入张量相乘,得到经过注意力加权的特征张量。这样就实现了对输入张量的自适应特征加权。
数学表示为:
y = AdaptiveAvgPool2d ( x ) y ′ = Sigmoid ( Linear ( ReLU ( Linear ( y ) ) ) ) output = x ⊙ y ′ y = \text{AdaptiveAvgPool2d}(x) \\ y' = \text{Sigmoid}(\text{Linear}(\text{ReLU}(\text{Linear}(y)))) \\ \text{output} = x \odot y' y=AdaptiveAvgPool2d(x)y′=Sigmoid(Linear(ReLU(Linear(y))))output=x⊙y′
其中 ⊙ \odot ⊙ 表示按元素相乘操作。
注意力机制层的搭建代码:
class AttentionLayer(nn.Module):
def __init__(self, channel, reduction=16):
super(AttentionLayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel// reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
4.2 在网络中加入注意力层
我们将注意力层加入到ConvNet模型中:
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
AttentionLayer(32))
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
AttentionLayer(64))
self.drop_out = nn.Dropout()
self.fc1 = nn.Linear(8 * 8 * 64, 1000)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.drop_out(out)
out = self.fc1(out)
return self.fc2(out)
五、模型训练与测试
接下来,我们将进行模型的训练和测试。
5.1 模型训练
import torch.optim as optim
model = ConvNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 20 == 0: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
5.2 模型测试
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
六、结论
这篇文章就像是一张奇妙的地图,引领你进入计算机视觉任务的神奇世界。在这个世界里,你将与PyTorch和注意力机制这两位强大的伙伴结伴前行,共同探索街道房屋号码识别的奥秘。
想象一下,你置身于繁忙的街道上,满目琳琅的房屋号码挑战着你的视力。而你却拥有了一种神奇的眼力,能轻松识别出每一个号码。这种超凡能力正是计算机视觉任务的魔法所在。
我们要携手PyTorch这位强大的工具,它如同一把巧妙的魔法棒,能帮助我们构建强大的神经网络模型。通过PyTorch,我们可以灵活地定义模型的结构,设置各种参数,并进行高效的训练和推理。
我们遇到了注意力机制,就像是一盏明亮的灯塔,照亮了我们前进的方向。注意力机制能够使神经网络集中注意力于图像中的重要区域,从而提高识别的准确性。利用这种机制,我们可以让模型更加聪明地注重街道房屋号码所在的位置和细节,从而更好地进行识别。而SVHN数据集则是我们探险的指南,其中包含了大量真实世界中的街道房屋号码图像。通过导入这些数据,我们可以让模型从中学习并提高自己的识别能力。这些图像将带领我们穿越城市的角落,感受不同场景下的挑战和变化。通过这篇文章,我们不仅可以更深入地理解计算机视觉任务的本质,还能获得启发。就像是一次奇妙的冒险,我们将学会如何使用PyTorch和注意力机制来实现街道房屋号码的识别任务。让我们一起跟随这个引人入胜的旅程,开拓视野,追寻新的可能性吧!