基于C#调用TensorRT 部署Yolov5模型
NVIDIA TensorRT™ 是用于高性能深度学习推理的 SDK,可为深度学习推理应用提供低延迟和高吞吐量。详细安装方式参考以下博客: NVIDIA TensorRT 安装 (Windows C++)
前文中已经介绍了在C++中利用TensorRT 部署Yolov5模型,但在实际应用中,经常会出现在C#中部署模型的需求,目前TensorRT无法直接在C#调用函数接口实现模型部署,此处利用动态链接库功能,构建TensorRTSharp,实现C#部署模型。
1. 构建TensorRTSharp
1.1 创建动态链接库项目
1.1.1 新建TensorRT接口实现文件
右击解决方案,选择添加新建项目,添加一个C++空项目,将C++项目命名为:cpp_tensorrt_api。进入项目后,右击源文件,选择添加→新建项→C++文件(cpp),进行的文件的添加。具体操作如所示。
1.1.2 配置C++项目属性
右击项目,点击属性,进入到属性设置,此处需要设置项目的配置类型包含目录、库目录以及附加依赖项,本次项目选择Release模式下运行,因此以Release情况进行配置。
(1)设置常规属性
进入属性设置后,在最上面,将配置改为Release,平台改为x64。
常规设置下,点击输出目录,将输出位置设置为< $(SolutionDir)dll_import/tensorrt >,即将生成文件放置在项目文件夹下的dll文件夹下;其次将目标文件名修改为:tensorrtsharp;最后将配置类型改为:动态库(.dll),让其生成dll文件。
(2)配置附加包
此处需要使用TensorRT与OpenCV两个外部依赖包,因此需要配置相关设置,具体操作方式按照在C++中利用TensorRT 部署Yolov5模型配置C++项目部分。
1.2 编写C++代码
1.2.1 推理引擎结构体
Logger是TensorRT工具套件用于创建IBuilder、IRuntime或IRefitter实例的记录器,该类中log()方法未进行实例化,因此需要将其实例化,重写该类中的log()方法。
class Logger : public nvinfer1::ILogger{
void log(Severity severity, const char* message) noexcept{
if (severity != Severity::kINFO)
std::cout << message << std::endl;
}
} gLogger;
为了实现模型推理能在各个接口中传递推理的相关配置信息,所以将相关重要类或结构体整合到NvinferStruct结构体中,如下:
typedef struct tensorRT_nvinfer {
Logger logger;
nvinfer1::IRuntime* runtime;
nvinfer1::ICudaEngine* engine;
nvinfer1::IExecutionContext* context;
cudaStream_t stream;
void** data_buffer;
} NvinferStruct;
IRuntime为TensorRT反序列化引擎,允许对序列化的功能上不安全的引擎进行反序列化,该类中deserializeCudaEngine()方法可以重构本地保存的模型推理文件;IcudaEngine为创建的网络上执行推理的引擎,保存了网络模型的相关信息; IExecutionContext为用于模型推理的上下文,是最终执行推理类;cudaStream_t为CUDA stream标志,主要用于后面在GPU显存上传输数据使用;data_buffer为GPU显存输入/输出缓冲内存位置,用于在显存上读取和输入数据。
1.2.2 接口方法规划
TensorRT进行模型推理,一般需要十个步骤,主要是:初始化Logger对象、创建反序列化引擎、读取本地推理模型并初始化推理引擎、创建用于推理上下文、创建GPU显存输入/输出缓冲区、准备输入数据、将输入数据从内存加载到显存、执行推理计算以、从显存读取推理结果到内存和处理推理计算结果。我们根据原有的十个步骤,对步骤进行重新整合,并根据推理步骤,调整方法接口。
对于方法接口,主要设置为:推理引擎初始化、创建GPU显存输入/输出缓冲区、加载图片输入数据到缓冲区、模型推理、读取推理结果数据以及删除内存地址六个接口,目前 TensorRT模型推理接口只允许图片输入,暂不支持其他数据的配置。
1.2.3 ONNX模型转换
TensorRT几乎可以支持所有常用的深度学习框架,对于caffe和TensorFlow来说,TensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet,chainer,CNTK等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对ONNX模型做解析。目前TensorRT主要是在更新的是ONNX模型转换,通过内置API将ONNX模型转换为TensorRT可以直接读取的engine文件;engine文件既包含了模型的相关信息,又包含了转换设备的配置信息,因此转换后的engine文件不可以跨设备使用。
模型转换接口方法为:
extern "C" __declspec(dllexport) void __stdcall onnx_to_engine(const wchar_t* onnx_file_path_wchar,
const wchar_t* engine_file_path_wchar, int type);
onnx_file_path_wchar为ONNX格式的本地模型地址,engine_file_path_wchar为转换后的模型保存地址,type为模型保存的精度类型,当type = 1时保存为FP16格式,type = 2时保存为INT8格式。
首先创建构建器,用于创建config、network、engine的其他对象的核心类,获取cuda内核目录以获取最快的实现。
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
其次就是将ONNX模型解析为TensorRT网络定义的对象,explicit_batch为指定与按位或组合的网络属性,network本地定义的网络结构,该结构支持直接读取ONNX网络结构到TensorRT格式。
const auto explicit_batch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicit_batch);
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
parser->parseFromFile(onnx_file_path.c_str(), 2);
接下来就是创建生成器配置对象,config主要需要设置工作空间长度以及模型的精度,此处提供FP16以及INT8格式。
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(16 * (1 << 20));
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
在读取完本地模型和配置完成相关设置后,就可以构建模型推理引擎,通过调用builder构建器下的buildEngineWithConfig()方法实现。
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
此处只需要模型转换,因此接下载将推理引擎转为文件流,保存到本地,后续模型推理时只需要直接读取本地保存的推理引擎文件即可。
nvinfer1::IHostMemory* model_stream = engine->serialize();
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
最后一步就是销毁前面所创建的地址对象,销毁的时候需要按照创建的先后顺序销毁。
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
1.2.4 初始化推理模型
TensorRT推理引擎结构体是联系各个方法的桥梁,后续实现模型信息以及配置相关参数进行传递都是在推理引擎结构上实现的,为了实现数据在各个方法之间的传输,因此在创建推理引擎结构体时,采用的是创建结构体指针,并将创建的结构体地址作为函数返回值返回。推理初始化接口主要整合了原有推理的初始化NvinferStruct对象、读取本地推理模型、初始化反序列化引擎、初始化推理引擎、创建上下文以及创建创建GPU数据缓冲区,并将这些步骤所创建的变量放在推理引擎结构体中。
初始化推理模型接口方法为:
extern "C" __declspec(dllexport) void* __stdcall nvinfer_init(const wchar_t* engine_filename_wchar, int num_ionode);
该方法返回值为NvinferStruct结构体指针,其中engine_filename_wchar为推理模型本地地址字符串指针,在后面使用上述变量时,需要将其转换为string字符串,利用wchar_to_string()方法可以实现将其转换为字符串格式:
std::string engine_filename = wchar_to_string(engine_filename_wchar);
首先第一步通过文件流方式读取本地模型文件,将模型文件读取到内存中:
std::ifstream file_ptr(engine_filename, std::ios::binary);
if (!file_ptr.good()) {
std::cerr << "文件无法打开,请确定文件是否可用!" << std::endl;
}
size_t size = 0;
file_ptr.seekg(0, file_ptr.end); // 将读指针从文件末尾开始移动0个字节
size = file_ptr.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file_ptr.seekg(0, file_ptr.beg); // 将读指针从文件开头开始移动0个字节
char* model_stream = new char[size];
file_ptr.read(model_stream, size);
// 关闭文件
file_ptr.close();
其次对模型进行初始化,模型初始化功能主要包括:初始化推理引擎结构体和对结构体里面定义的其他变量进行赋值操作,其主要是NvinferStruct中各个变量进行初始化操作:
NvinferStruct* p = new NvinferStruct(); // 创建推理核心结构体,初始化变量
p->runtime = nvinfer1::createInferRuntime(gLogger); // 初始化反序列化引擎
p->engine = p->runtime->deserializeCudaEngine(model_stream, size); // 初始化推理引擎
p->context = p->engine->createExecutionContext(); // 创建上下文
p->data_buffer = new void* [num_ionode]; // 创建gpu数据缓冲区
最后一步就是删除文件流数据,防止出现内存泄漏。
1.2.5 创建GPU显存输入/输出缓冲区
TensorRT主要是使用英伟达显卡CUDA在显存上进行模型推理的,因此需要在显存上创建输入输出的缓存区。其创建创建GPU显存输入/输出缓冲区方法接口为:
extern "C" __declspec(dllexport) void* __stdcall creat_gpu_buffer(void* nvinfer_ptr,
const wchar_t* node_name_wchar, size_t data_length);
其中nvinfer_ptr为NvinferStruct结构体指针,为第一步初始化后返回的指针,在该方法中,只需要重新将其转换为NvinferStruct类型即可:
NvinferStruct* p = (NvinferStruct*)nvinfer_ptr;
node_name_wchar为输入或输出节点名字符串,在此处我们只需要配置输入和输出的节点数据缓存区,并利用getBindingIndex()方法获取节点的序号,用于指定缓存区的位置:
const char* node_name = wchar_to_char(node_name_wchar);
int node_index = p->engine->getBindingIndex(node_name);
data_length为缓存区数据的长度,其数据长度为节点数据大小,然后直接调用cudaMalloc()方法创建GPU显存输入/输出缓冲区
cudaMalloc(&(p->data_buffer[node_index]), data_length * sizeof(float));
1.2.6 配置图片输入数据
TensorRT将数据加载到网络输入比较简便,只需要调用cudaMemcpyAsync()方法便可实现,对于此处,我们只设置了图片数据输入的情况,其实现方法接口为:
extern "C" __declspec(dllexport) void* __stdcall load_image_data(void* nvinfer_ptr,
const wchar_t* node_name_wchar, uchar * image_data, size_t image_size, int BN_means);
该方法返回值是NvinferStruct结构体指针,但该指针所对应的数据中已经包含了加载的图片数据。第一个输入参数nvinfer_ptr是NvinferStruct指针,在当前方法中,我们要读取该指针,并将其转换为CoreStruct类型;第二个输入参数node_name_wchar为待填充节点名,先将其转为char指针,并查询该节点的序列号:
const char* node_name = wchar_to_char(node_name_wchar);
int node_index = p->engine->getBindingIndex(node_name);
在该项目中,我们主要使用的是以图片作为模型输入的推理网络,模型主要的输入为图片的输入。其图片数据主要存储在矩阵image_data和矩阵长度image_size两个变量中。需要对图片数据进行整合处理,利用创建的data_to_mat () 方法,将图片数据读取到OpenCV中:
cv::Mat input_image = data_to_mat(image_data, image_size);
接下来就是配置网络图片数据输入,对于节点输入是图片数据的网络节点,其配置网络输入主要分为以下几步:
首先,获取网络输入图片大小。
使用engine中的getBindingDimensions ()方法,获取指定网络节点的维度信息,其节点要求输入大小在node_dim容器中,通过读取得到图片的长宽信息:
nvinfer1::Dims node_dim = p->engine->getBindingDimensions(node_index);
int node_shape_w = node_dim.d[2];
int node_shape_h = node_dim.d[3];
cv::Size node_shape(node_shape_w, node_shape_h);
size_t node_data_length = node_shape_w * node_shape_h;
其次,按照输入要求,处理输入图片。
在这一步,我们除了要按照输入大小对图片进行放缩之外,还要对输入数据进行归一化处理。因此处理图片其主要分为交换RGB通道、放缩图片以及对图片进行归一化处理。在此处我们借助OpenCV来实现。
对与数据归一化处理方式,我们在此处提供了两种处理方式,一种是百度飞桨归一化处理方式,另一种为普通数据处理方式,主要通过BN_means指定实现。对于普通数据处理方式,方式比较简单,OpenCV中有专门的方法可以实现,该方法可以直接实现交换RGB通道、放缩图片以及对图片进行归一化处理,我们通过调用该方式:
BN_image = cv::dnn::blobFromImage(input_image, 1 / 255.0, node_shape, cv::Scalar(0, 0, 0), true, false);
另一种为百度飞桨归一化处理处理方式,第一部需要交换RGB通道
cv::cvtColor(input_image, input_image, cv::COLOR_BGR2RGB);
接下来就是根据网络输入要求,对图片进行压缩处理:
cv::resize(input_image, BN_image, node_shape, 0, 0, cv::INTER_LINEAR);
最后就是对图片进行归一化处理,其主要处理步骤就是减去图像数值均值,并除以方差。查询PaddlePaddle模型对图片的处理,其均值mean = [0.485, 0.456, 0.406],方差std = [0.229, 0.224, 0.225],利用OpenCV中现有函数,对数据进行归一化处理:
std::vector<cv::Mat> rgb_channels(3);
cv::split(BN_image, rgb_channels); // 分离图片数据通道
std::vector<float> mean_values{ 0.485 * 255, 0.456 * 255, 0.406 * 255 };
std::vector<float> std_values{ 0.229 * 255, 0.224 * 255, 0.225 * 255 };
for (auto i = 0; i < rgb_channels.size(); i++) {
rgb_channels[i].convertTo(rgb_channels[i], CV_32FC1, 1.0 / std_values[i], (0.0 - mean_values[i]) / std_values[i]);
}
cv::merge(rgb_channels, BN_image);
最后,将图片数据输入到模型中。
TensorRT将输入数据加载到显存中需要通过cuda流方式,首先船舰一个异步流,并将输入数据赋值到输入流中:
cudaStreamCreate(&p->stream);
std::vector<float> input_data(node_data_length * 3);
memcpy(input_data.data(), BN_image.ptr<float>(), node_data_length * 3 * sizeof(float));
然后直接调用cudaMemcpyAsync()方法,将输入数据加载到显存上:
cudaMemcpyAsync(p->data_buffer[node_index], input_data.data(), node_data_length * 3 * sizeof(float), cudaMemcpyHostToDevice, p->stream);
1.2.7 模型推理
上一步中我们将推理内容的数据输入到了网络中,在这一步中,我们需要进行数据推理,实现模型推理的方法接口为:
extern "C" __declspec(dllexport) void* __stdcall infer(void* nvinfer_ptr)
进行模型推理,只需要调用NvinferStruct结构体中的context对象中的enqueueV2 ()方法即可:
NvinferStruct* p = (NvinferStruct*)nvinfer_ptr;
p->context->enqueueV2(p->data_buffer, p->stream, nullptr);
1.2.8 读取推理数据
上一步我们对数据进行了推理,这一步就需要查询上一步推理的结果。对于我们所使用的模型输出,主要有float数据,其方法为:
extern "C" __declspec(dllexport) void __stdcall read_infer_result(void* nvinfer_ptr,
const wchar_t* node_name_wchar, float* output_result, size_t node_data_length);
其中node_data_length为读取数据长度,output_result 为输出数组指针。读取推理结果数据与加载推理数据方式相似,主要是将显存上数据赋值到内存上。首先需要获取输入节点的索引值:
const char* node_name = wchar_to_char(node_name_wchar);
int node_index = p->engine->getBindingIndex(node_name);
接下来在本地创建内存放置结果数据,然后调用cudaMemcpyAsync()方法,将显存上数据赋值到内存上:
std::vector<float> output_data(node_data_length * 3);
cudaMemcpyAsync(output_data.data(), p->data_buffer[node_index], node_data_length * sizeof(float), cudaMemcpyDeviceToHost, p->stream);
将数据读取出来后,将其放在数据结果指针中,并将所有结果赋值到输出数组中:
for (int i = 0; i < node_data_length; i++) {
*output_result = output_data[i];
output_result++;
}
1.2.9 删除推理核心结构体指针
推理完成后,我们需要将在内存中创建的推理核心结构地址删除,防止造成内存泄露,影响电脑性能,其接口该方法为:
extern "C" __declspec(dllexport) void __stdcall nvinfer_delete(void* nvinfer_ptr);
在该方法中,我们只需要调用delete命令,将结构体指针删除即可。
1.3 编写模块定义文件
在模块定义文件中,添加以下代码:
LIBRARY
"tensorrtsharp"
EXPORTS
onnx_to_engine
nvinfer_init
creat_gpu_buffer
load_image_data
infer
read_infer_result
nvinfer_delete
LIBRARY后所跟的为输出文件名,EXPORTS后所跟的为输出方法名。仅需要以上语句便可以替代extern "C" 、 __declspec(dllexport) 以及__stdcall的使用。
1.4 生成dll文件
前面我们将项目配置输出设置为了生成dll文件,因此该项目不是可以执行的exe文件,只能生成不能运行。右键项目,选择重新生成/生成。在没有错误的情况下,会看到项目成功的提示。可以看到dll文件在解决方案同级目录下\x64\Release\文件夹下。
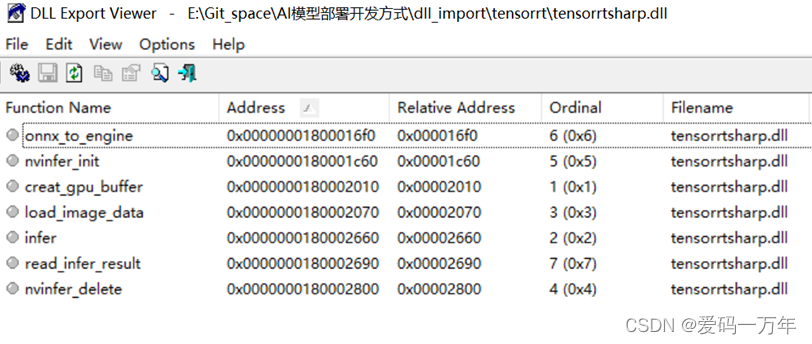
使用dll文件查看器打开dll文件,如图 tensorrt.dll文件方法输出目录所示;可以看到,我们创建的方法接口已经暴露在dll文件中。