机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
sklearn.datasets包内置了一些小规模的示例数据集。为了评估数据规模的影响,控制数据的统计属性(典型的是特征的相关性和忠实度),也可以产生合成数据。该包也可以作为评价机器学习算法性能的基准数据集的所在。
通用数据集 API
对于不同类型的数据集,有三个不同类型的数据集接口。最简单的是样本图像接口。数据集生成函数和svmlight加载器共享一个简化接口,返回一个元组(X, y). 该元组包括一个n_samples * n_features numpy数组X, 一个长度为n_samples, 包括目标变量y的数组。
示例数据集(toy datasets)、真实数据集和来自mldata.org的数据集,结构更加复杂。这些函数返回类字典的对象,至少包括两项:一个形如n_samples * n_features的数组,拥有data键;一个长度为n_samples的numpy数组,拥有target键。
数据集也包括DESCR描述,一些数据集包括feature_names and target_names.
示例数据集
scikit-learn自带一些小的标准数据集,并不需要从外部网站下载任何文件。
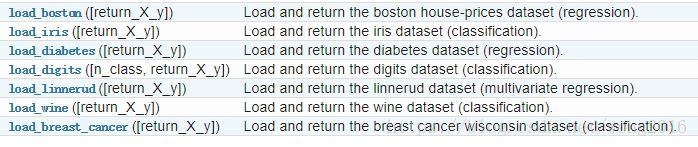
这些数据集可以用来快速检验不同算法的表现,然而,因为数据规模太小,它们并不能代表算法对来自真实世界的数据的真正表现。
样本图像
scikit也自带了几个JPEG图像样本数据集。这些数据集可以被用来检验算法和pipeline 2D数据。

样本生成器
scikit-learn包括不同的随机样本生成器,可以创造大小和复杂度可控的人造数据集。
分类/聚类数据生成器
生成对应离散target的特征矩阵,这里主要介绍单个类标签的情况。

make_blobs, make_classification都可以产生多个类别的数据集,这是通过分配每个类一个或者多个正态分布的数据点实现的。make_blobs提供了关于每个类的中心和标准差的更大控制,所以主要用来演示聚类。make_classification通过以下形式规定数据的噪音:
相关、冗余且无信息的特征;
每个类包括多个高斯类;
特征空间的线性变换。
make_circles and make_moons可以产生二维二值分类数据集,包括最佳的高斯噪音。
回归生成器
make_regression通过随机特征的最优线性组合,再加入随机误差,产生回归的目标变量。make_sparse_uncorrelated通过具有固定系数的四个特征的线性组合,产生目标变量。
从mldata.org仓库下载数据集
mldata.org是一个机器学习的开放数据仓库,sklearn.datasets包可以直接从mldata.org下载数据集,使用sklearn.datasets.fetch_mldata函数。例如,为了下载MNIST数字识别数据库:

MNIST数据库由总共7万个手写数字的实例组成,每个实例是大小为 的像素,标签0~9的数字。
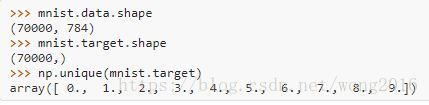
在首次下载后,数据集保存在由参数data_home指定的路径下,默认路径是~/scikit_learn_data/

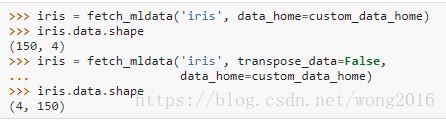
mldata.org下载的数据数组经常以(n_features, n_samples)的形式组织,这和scikit-learn组织数据的形式相反。所以,sklearn.datasets.fetch_mldata默认操作是转置矩阵,这由参数transpose_data控制:
阅读更多精彩内容,请关注微信公众号:统计学习与大数据