回顾——聚焦爬虫:
爬取页面中指定的页面内容;获得相应的数据信息之后的处理我们就称之为数据解析
编码流程:
— 指定url
— 发起请求
— 获取响应数据
— 数据解析
— 持久化存储
数据解析分类:
— 正则
— bs4
— xpath(通用性较强)
数据解析原理概述:
— 解析的局部的文本内部都会在标签之间或者标签对应的属性中进行存储。
— 1. 进行指定标签的定位
— 2. 标签或者标签对应的属性中存储的数据值进行提取(解析)
1、数据解析——正则
1.1 findall:匹配字符串中所有的符合正则的内容
re.findall(pattern,string,flags=0)
# 用于返回包含所有匹配项的列表。返回string中所有与pattern相匹配的全部字串,返回形式为数组。
import re
# findall:匹配字符串中所有的符合正则的内容
lst = re.findall("m", "mai le fo len,mai ni mei!") #需要寻找的数,字符串
print(lst) # ['m', 'm', 'm']
#r是指被r前缀的字符串不进行转义
lst1 = re.findall(r"\d+", "5点之前,你要给我5000万")#也可以是需要的正则,字符串
print(lst1) # ['5', '5000']
#考虑到findall返回到列表效率不高
#finditer: 匹配字符串中所有到内容[返回到是迭代器],从迭代器中拿到内容需要.group()
it=re.finditer(r"\d+", "5点之前,你要给我5000万")
for i in it:
print(i.group())
'''
返回结果:
5
5000
'''1.2 search
import re
#search,找到一个结果就返回,返回的结果是match对象,拿数据需要.group()
s = re.search(r"\d+","我的电话号是:10086,我女朋友的电话是:10010")
print(s.group()) #100861.3 match
# match是从头开始匹配
s = re.match(r"\d+","我的电话号是:10086,我女朋友的电话是:10010") #当开头不是数字就会报错
s1 = re.match(r"\d+","10086,我女朋友的电话是:10010")
print(s1.group()) #10086
print(s.group()) #报错1.4 预加载正则表达式(提前编写正则,方便以后调用,提高效率)
import re
obj = re.compile(r"\d+")#存储正则表达式
ret=obj.finditer("我的电话号是:10086,我女朋友的电话是:10010")
for it in ret:
print(it.group())1.4.1 案例:提取指定字符
import re
s="""
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思辙</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
#提前编写正则表达式
# (?P<自定义组名>.*?) -》用于自定义的组名提取数据,P要大写
#后面的re.S是为了换行
obj = re.compile(r"<div class='.*?'><span id='.*?'>(?P<wahaha>.*?)</span></div>",re.S)
result = obj.finditer(s)
for i in result:
print(i.group("wahaha"))【运行结果】
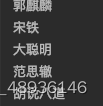
需要id值,也可以给id创建组名
import re
s="""
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思辙</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
obj = re.compile(r"<div class='.*?'><span id='(?P<id>.*?)'>(?P<wahaha>.*?)</span></div>")
result = obj.finditer(s)
for i in result:
print(i.group("id"))
print(i.group("wahaha"))
 https://www.runoob.com/python/python-reg-expressions.html#flags
https://www.runoob.com/python/python-reg-expressions.html#flags