- 聚焦爬虫 : 爬取页面中指定的页面内容
- 编码流程
- 指定URL
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
- 数据解析分类 :
- 正则
- bs4
- xpath (***)
- 数据解析原理概述
- 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
- 1. 进行指定标签的定位
- 2. 标签或者标签对应的属性总存储的数据进行提取 (解析)
format案例




正则表达式实战
- 需求 : 爬取糗事百科图片
- re.S单行匹配
-re.M多行匹配
- 二进制格式 : content
- format : 用于格式化字符串的强大工具。它可以将变量、表达式以及其他值插入到格式化字符串的特定位置
图片链接的地方
正则数据解析
拿到图片地址的地方并且写正则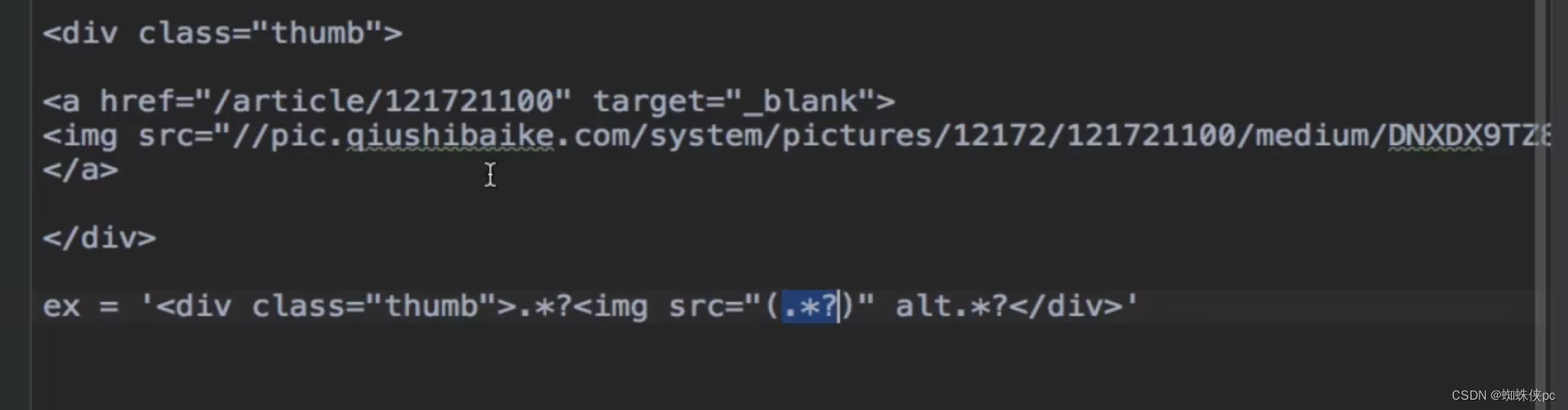
没有协议的图片地址
import re
import requests
import os
#创建文件夹
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs')
url = 'https://www.qiushibaike.com/pic/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
#使用通用爬虫对一整张页面进行爬取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫将页面中的糗图进行解析
#正则表达式
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(page_text,ex,re.S) #正则用到数据解析时一定用的re.S
print(img_src_list) #拿到图片地址的列表
for src in img_src_list:
#拼接出一个完整的图片url
src = 'http:'+src
#请求到了图片的二进制
img_data = requests.get(url=src,headers=headers).content#content以二进制的形式存储
#生成图片名称
img_name = src.split('/')[-1]
#图片最终存储的路径
iimgPath = './qiutuLibs/'+img_name
with open(iimgPath,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功!!!")bs4进行数据解析
- 数据解析原理
- 1.标签定位
- 2.提取标签,标签属性中存储的数据值
- bs4数据解析的原理
- 1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
-2.通过调用BeautifulSoup对象中相关的属性或方法进行标签定位和数据提取
- 环境安装
- pip install bs4
- pip install lxml
- 如何实例化BeautifulSoup对象
- from bs4 import BeautifulSoup
- 对象实例化
- 1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'lxml')
- 2.将互联网上获取的页面源码加载到该对象中
page_text =response.text
soup = BeautifulSoup(page_text,'lxml')
- 提供的用于数据解析的方法和属性
- soup.tagName : 返回的是文档中第一次出现的tagName对应的标签
- soup.find() :
-find('tagName') :等同于soup.tarName
- 属性定位 :
- soup.find('div',class_/id/attr='song')
- soup.find_all('tagName') : 返回符合要求的所有标签 (列表)
- select :
- select('某种选择器(id,class,标签...选择器)'),返回的是一个列表
- 层级选择器 :
- soup.select('.tang > ul > li > a')
- soup.select('.tang > ul > li a') :空格表示的多个层级
- 获取标签之间的文本数据 :
- soup.a.text/string/get_text() 两个属性,一个方法
- text/get_text() : 可以获取某一个标签中所有的文本内容
- string : 只可以获取该标签下面直系的文本内容
- 获取标签中的属性值
- soup.a['href']

BeautifluSoup实战:爬取三国演义书籍
import requests
from bs4 import BeautifulSoup
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
#发起请求
page_text = requests.get(url=url,headers=headers).text.encode('ISO-8859-1')
print(page_text)
soup = BeautifulSoup(page_text,'lxml') #实例化对象
li_list = soup.select('.book-mulu > ul >li') #拿到所有的li标签
print(li_list)
fp = open ('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title =li.a.string #拿到a标签的文本内容
detail_url ='https://www.shicimingju.com/'+li.a['href'] #拿到该章内容的网页
detail_page_text = requests.get(url=detail_url, headers=headers).text.encode('ISO-8859-1')
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='chapter_content')
#解析到了章节的内容
content = div_tag.get_text()
# 持久化存储
fp.write(title +':'+content+'\n')
print(title,'爬取成功!!!')