L1 Cache architecture
这篇整理了ARM Programmer’s Guide的内容,并透过实际例子来探讨VIVT(virtual indexed vritual tagged)、VIPT(virtual indexed physical tagged)、PIPT(physical indexed physical tagged)的差异性。
Virtually Addressed Caches(VIVT)
十多年前的ARM Processor L1 cache采用VIVT cache构架,在当时的ARM architecture reference 5.5.1节有提及主要的原因:
It allows cache line look-up to proceed in parallel with address translation.
由于cache access和address translation可以同时执行,因此当有cache miss发生时,就能够缩短取得physical memory address的时间(reduce miss penalty)。另外,在一般情况下cache hit发生次数较多,因此cache hit access不用经由address translation,对于提升性能也有帮助。
但也因为virtual address的特性,导致VIVT cache会产生一些严重问题,其中包含:
Problems
-
- homonyms
不同process中有同一个virtual address,并指向不同的physical address。因为virtual address相同,因此会使用同一个cache line,当切换到另一个process时,会导致误判成cache hit而取得错误data。
- homonyms
-
- synonyms
不同virtual address指向同一个physical address,例如mmap或是多个process共享同一个数据。因为是不同virtual address,也意味着同一份data会分别缓存在不同的cache line,可能导致其中一个process更新cache data后,另一个process的cache data没有被更新,因而取得较旧的数据。
- synonyms
Possible solutions
- Flush Cache
而针对cache数据不一致的问题,一个直接又暴力的解法就是flush cache。当context switch或是context swap时候,直接清空cache data,重新地从main memory中取得。以ARMv5为例,因为L1 cache分成data cache和instruction cache,其flush cache流程是:- 如果data cache为write-back,则清空
- invalidating the data cache
- invalidating the instruction cache
- 清除write buffer
另外,virtual cache access也需要考察page permission问题,因此cache unit实际上会去向TLB询问此virtual address的permission。因此当context switch时,TLB也同样地要需要invalidate。
上述可以得知flush cache所带来的成本相当高,毕竟每次context swap或是switch时都需要clean和reload data。在The ARM Fast Context Switch Extension for Linux提到,context switch时flush cache所造成的时间成本可能多达200 microseconds,对real-time需求较高的application来说是蛮严重的问题。
Fast Context Switch Extension
为了降低flush cache次数,2009年ARM采用软件实作搭配ARMv5构架,提出Fast Context Switch Extension解法。FCSE主要是用来解决不同process使用相同virtual address range问题。
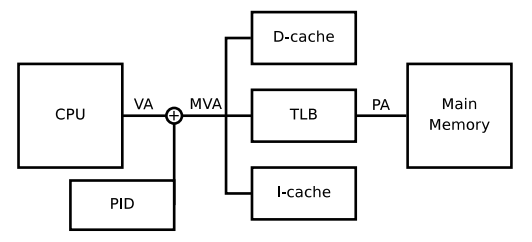
其概念是将virtual address的最高位前7 bit改成process ID,如此一来不同process就能各自拥有不同的virtual address range。不过这样的设计问题就是process数量受到限制,7 bit最多只能有2^7 = 128 process数量。论文中也有说明此机制适用在部份embedded system场景。
From Virtual Cache to Physical Cache
随着应用场景复杂化和multi-core processor的发展,invalidating和clean cache成本对性能逐渐造成不可忽视的影响(后续再补数据图),从ARM在Cortex-A series processors document中有特别提及这点,因此从ARMv6开始,全部改采用VIPT instruction cache / PIPT data cache L1 cache构架。
Physically-addressed caches(VIPT)
ARM现代处理器多数L1 cache已采用physically-addressed cache,减少VIVT造成cache coherency问题。而之所以有virtual indexed physical tagged(VIPT)cache,是为了在address translation latency和cache access中取得平衡。VIPT机制中,index取自virtual address,因此可以先进行部分cache line查找流程,等address tranlation后取得physical tag,再进行最后tag比对。
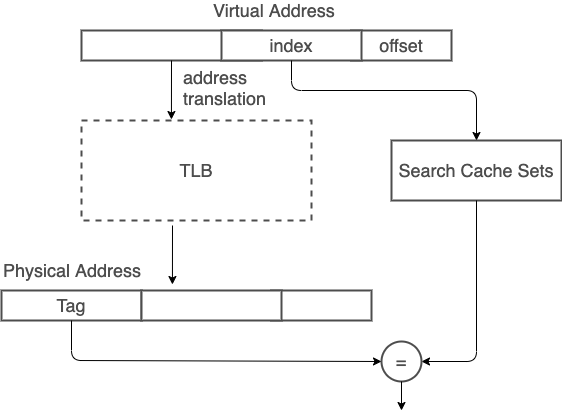
不过因为VIPT会使用到部分virtual address,为了避免产生VIVT所造成的synonyms问题,在使用VIPT时会受限于hardware的page size。
举例来说,常见的page size是4KB(2^12),所以physical address和virtual address的0 - 11 bit为相同数值。利用这特性,只要在这12 bit内分配cache index和cache offset bit数,就能够确保一个physical address data只会在同一个cache line上。
如此一来,cache size就会被限制在2^12 * multi-way。像是physical page size为4KB(2^12),cache line为64(2^6)bytes,采用four-way associative cache,则cache size大小就是4KB * 4 = 16KB。

如果page size是4KB,four-way associative cache size是64KB会发生什么事?
如果cache size是64 KB,则cache index需要8 bit,cache line同样为6 bit,8 + 6 = 14多于physical page size的12 bit,那么多出来的2个bit就有可能因为address translation而发生synonyms问题。
Possible solutions - page coloring
面对上述产生的问题,其中一项解决方法就是page coloring,就是将上述多出来的2 bit区分颜色,2 bit就会有2^2 = 4个颜色。
并限制不同颜色需要对应到不同physical page。如此一来就可以避免不同virtual address和不同cache index却对应到同一个physical address。
Physically-addressed caches(PIPT)
如果cache size不想受限于page size,又要避免page coloring,最简单又直接的方式就是直接采用PIPT的方式,当然这也就增加cache hit latency,不过相较于context switch所带来的VIVT在clean cache成本和可能发生数据不一致性,PIPT相对单纯。在ARMv6之后的L1 data cache就是采用PIPT。
VIPT v.s. PIPT
在上述提到的ARM A系列规格,可以发现到L1 cache中,instruction cache是VIPT four-way associative cache,而data cache是PIPT four-way associative cache。是怎样的考察才会让这两个cache在规格上有所差异?
在ARM community中就有人提过此问题:
Why is the I-cache designed as VIPT,while the D-cache as PIPT?
而ARM工程师给了解答:
PIPT caches are more flexible(can share data across processes without needing a cache flush on context switch),but more power intensive(I need to to a TLB lookup on every access rather than just on line-fill(i.e. when I miss)).
The instruction cache doesn’t generally need these advantages - it’s read-only - and the disadvantage is a significant one if you care about building a very power efficient core.