在上一篇文章ARM基础(3):MPU内存保护单元详解及例子中,我介绍了MPU,我们知道MPU允许按区域修改一级Cache的属性,这个Cache一般为L1 Cache,它位于CPU的内部,用来加快指令和数据的访问速度。同时,CPU在处理共享数据时需要确保CPU和主存之间的数据一致性。这篇文章就来详细介绍一下L1 Cache的概念和用法。
文章目录
1 L1 Cache和L2 Cache的概念
(1)L1 Cache
在ARM体系结构中,L1(Level 1)缓存是位于CPU内部的第一级高速缓存,用于存储指令和数据。L1缓存被进一步分为指令缓存(I-Cache)和数据缓存(D-cache),它们分别专门用于存储指令和数据。I-Cache存储CPU执行的指令,而D-cache存储CPU读取和写入的数据。
I-Cache和D-cache的目的是通过提供更快的数据访问速度来减少对主内存的访问。当处理器核心需要执行指令时,它会首先在I-Cache中查找,如果指令已经缓存在I-Cache中,则可以立即执行。同样,当处理器核心需要读取或写入数据时,它会首先在D-cache中查找,如果数据已经缓存在D-cache中,则可以快速访问。
(2)L2 Cache
L2缓存位于CPU和主存之间,作为第二级高速缓存。它的容量比L1缓存更大,可以存储更多的数据,L2缓存是可共享的。它的存在是为了进一步提高缓存命中率和整体性能,以及减少对主存的访问延迟。
- 与L2缓存相比,L1缓存更接近处理器核心,因此具有更低的访问延迟和更高的带宽,但是实际上L2的访问速度也不低。
2 Cortex-M7中的L1 Cache
2.1 缓存行
Cortex-M7处理器上的L1缓存被分成了32字节的line,每个line都有一个地址标记。即每个缓存行的大小为32字节,缓存行是L1 Cache缓存的基本单位。其中,D-Cache是4路组相联的(每个缓存组可以存储四个缓存行,每个缓存行都有一个标记,用于指示该缓存行在主存中的位置),每组有四个line,而I-Cache则是2路组相联的。较大的缓存会增加成本,较高的组相联度可以提高命中率,但也会增加成本和复杂度,所以D-Cache设置为4路和I-Cache设置为2路是一种硬件上的权衡。
2.2 缓存的命中和替换
如果缓存命中,则数据将从缓存中读取,或者被用于更新到主存中。如果缓存未命中,则会分配并标记一个新的缓存行,并将读或写的数据填充到缓存中。如果所有的缓存行都被分配了,缓存控制器就会运行缓存行替换过程,即选择一行进行清理,并重新分配。D-Cache和I-Cache实现了一种伪随机替换算法,用于选择被替换的缓存行。这种算法可以在缓存行的替换过程中提高随机性,从而有效地利用缓存空间,提高缓存命中率。
2.3 RT1170的L1 Cache
在Cortex-M7中,L1 Cache是与CPU的AXI(Advanced eXtensible Interface)总线相连的,从内存中取数据或者写数据到内存中都是依靠这个总线实现的。以I.MX RT1170为例,它是一个双核的CPU,对于CM7来说,有一个32KB的I-Cache和一个32KB的D-cache,它的连接关系如下图所示:
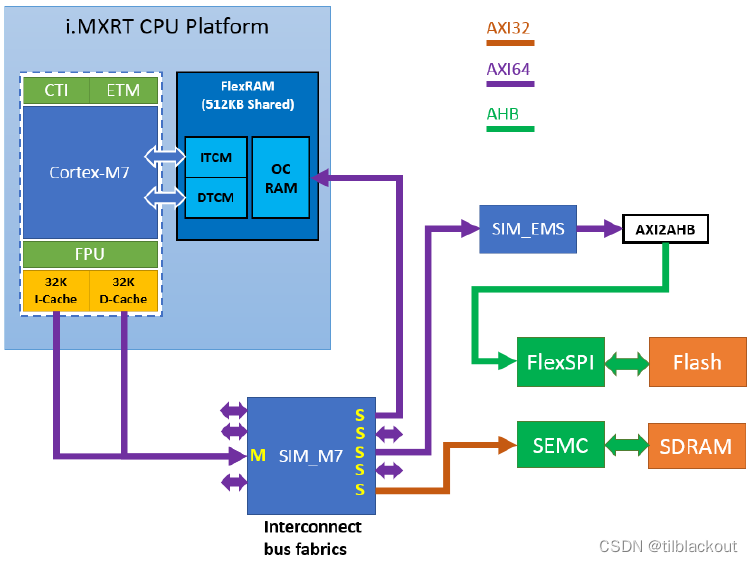
可以看到在RT1176中有两个紧耦合内存ITCM和DTCM,它的访问无需经过L1 Cache,速度非常快,所以建议将临界区的代码和数据放在TCM中,如向量表。需要注意的是,TCM存储器始终是non-Cacheable和non-Shareable的,而不管MPU如何设置。
3 缓存的相关函数
缓存操作的相关函数都是基于CMSIS开发标准的,函数定义在core_cm7.h中,如下表所示:
| CMSIS function | Description |
|---|---|
| void SCB_EnableICache (void) | Invalidate and then enable the instruction cache |
| void SCB_DisableICache (void) | Disable the instruction cache and invalidate its contents |
| void SCB_InvalidateICache (void) | Invalidate the instruction cache |
| void SCB_EnableDCache (void) | Invalidate and then enable the data cache |
| void SCB_DisableDCache (void) | Disable the data cache and then clean and invalidate its contents |
| void SCB_InvalidateDCache (void) | Invalidate the data cache |
| void SCB_CleanDCache (void) | Clean the data cache |
| void SCB_CleanInvalidateDCache (void) | Clean and invalidate the data cache |
Cache clean:将带有dirty标识的缓存行写入内存中,可以理解为flushInvalidate cache:将缓存中的所有有效数据标记为无效,这意味着下次访问这些数据时,系统将不会从缓存中读取,而是从主存或其他更低级别的缓存中获取最新的数据。失效缓存可以保证读取到最新的数据,特别是当其他设备或处理器修改了存储区域中的数据时。
用户只需要在MPU中设置不同内存区域的属性,然后通过上面列出的CMSIS功能启用缓存即可。例如,用户可以配置MPU是使用write-back还是write-through来对缓存进行操作。
write-back:在完成clean操作之前,cache中的数据不会写入到主存中write-through:一旦缓存行上的内容被写入,就更新到主存中。这对于数据一致性来说更安全,但需要更多的总线访问。- 实际上,
write-through只有很小的影响,除非同一个缓存集被重复且非常快速地访问。所以用哪一种方式是一种权衡。
- 实际上,
write-alloction:当缓存未命中时,需要为写入和读取操作都分配新的缓存行。
4 如何保证Cache的数据一致性
Cache可以给CPU性能带来一个很大的提升,但是用户应该注意缓存的维护和数据一致性。
4.1 例:播放Flash中的音频
假设我们想播放存储在外部Flash中的音频文件。数据流程图和连接关系如下:
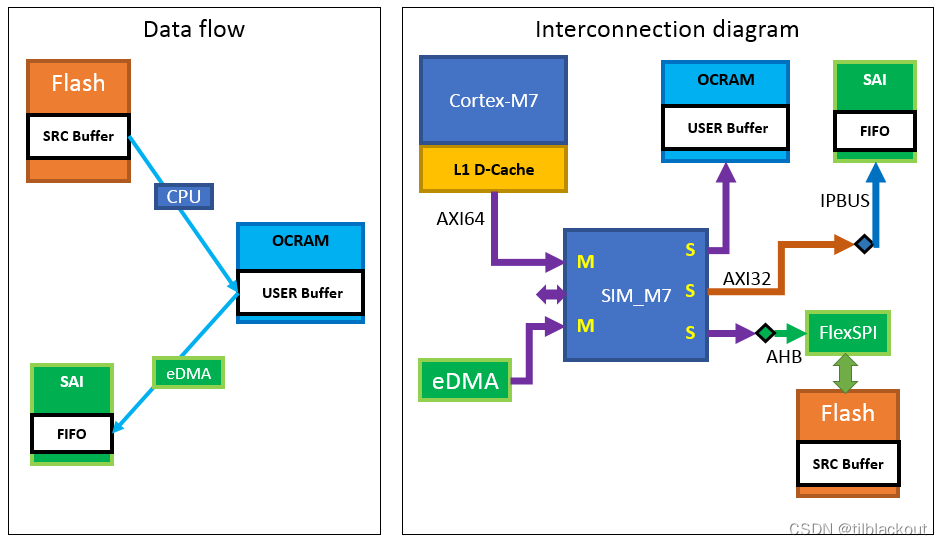
CPU通过L1 D-Cache读取SRC缓冲区中的音频文件内容,并解码PCM(Pulse Code Modulation)帧数据,写入OCRAM的USER缓冲区。用户缓冲区满后,eDMA开始将PCM帧数据复制到SAI IP模块内的FIFO。然后SAI使用移位操作将FIFO数据移到SAI总线进行音频回放。当CPU将帧数据写入启用L1缓存的OCRAM时,由于OCRAM的默认缓存策略为write-back,因此数据可能只写入cache。eDMA向SAI FIFO传输的数据不正确,导致数据一致性问题。有几种解决方法来解决这个问题:
- CPU将数据写入OCRAM后,执行D-Cache清理操作
- 在写操作开始前,将OCRAM内存区域缓存策略从
write-back设置为write-through - 配置OCRAM内存区域缓存策略为
non-cacheable - 配置OCRAM内存区域为
shareable,这会固定cache策略为non-cacheable。
4.2 使用cacheable buffer
对于定义在OCRAM,SRAM的buffer,一般都为Cacheable且Cache策略为write-back。如果要将定义在这里面的buffer作为DMA的源,用户必须在DMA开启之前执行一个D-Cache的清除操作,即SCB_CleanDCache();如果该buffer用作DMA的目标,在DMA完成后且CPU或其它主机读取数据之前,需要执行SCB_InvalidateDCache。
- buffer的地址应该基于L1缓存行的大小进行对齐,在Cortex-M7中为32字节
4.3 使用non-cacheable buffer
使用定义在non-cacheable内存区域的buffer直接解决了数据的一致性的问题,但是由于没有使用cache,这会导致访问这个buffer的速度会变慢很多。
最后以MCUXPresso IDE为例,看看如何定义一个non-cacheable buffer:
(1)在链接脚本中添加non-cacheable的内存段
对于MCUXPresso IDE来说,可以直接在GUI中修改:
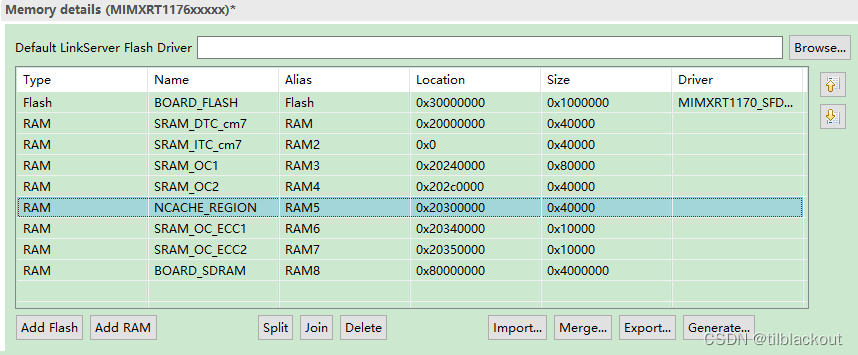
①在Memory details中添加NCACHE_REGION
②在链接脚本中添加input section

(2)MPU配置
对于DTCM来说,由于16组MPU的配置可以按优先级来覆盖。所以上面的代码我们先配置DTCM的cache策略默认为Write-back, no write allocate,代码如下:
MPU->RBAR = ARM_MPU_RBAR(5, 0x20000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_256KB);
接着我们要配置一下non-cacheable区域的MPU,代码如下:
extern uint32_t __base_NCACHE_REGION;
extern uint32_t __top_NCACHE_REGION;
uint32_t nonCacheStart = (uint32_t)(&__base_NCACHE_REGION);
uint32_t size = (uint32_t)(&__top_NCACHE_REGION) - nonCacheStart;
volatile uint32_t i = 0;
while ((size >> i) > 0x1U)
{
i++;
}
if (i != 0)
{
/* The MPU region size should be 2^N, 5<=N<=32, region base should be multiples of size. */
assert(!(nonCacheStart % size));
assert(size == (uint32_t)(1 << i));
assert(i >= 5);
/* Region 10 setting: Memory with Normal type, not shareable, non-cacheable */
MPU->RBAR = ARM_MPU_RBAR(10, nonCacheStart);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 1, 0, 0, 0, 0, i - 1);
}
首先我们来看一下链接脚本文件evkmimxrt1170_freertos_hello_cm7_Debug_memory.ld中的相关定义:
__base_NCACHE_REGION = 0x20300000 ; /* NCACHE_REGION */
__base_RAM5 = 0x20300000 ; /* RAM5 */
__top_NCACHE_REGION = 0x20300000 + 0x40000 ; /* 256K bytes */
C语言中可以直接用extern获取在链接脚本中定义的变量,所以__base_NCACHE_REGION 和__top_NCACHE_REGION实际上就对应我们刚刚在Memory details中添加的NCACHE_REGION。然后前面的代码就是找到一个最小的整数i,使得2^i大于等于变量size,然后以此就可以对参数进行合法性判断:整个区域的大小是不是2的倍数、是否大小大于一个缓存行等。同时ARM_MPU_RASR最后一个参数,内存区域的大小正好就可以用i-1来表示为2^i字节。
最后就是调用ARM_MPU_RASR配置MPU了,其中TEX为1、C和B为0,表示这段内存的类型为Normal,cache策略为non-cacheable。
(3)定义变量并链接到NCACHE_REGION
我们可以使用__attribute(section())关键字来指定变量链接到哪个段,MCUXPresso IDE中提供了这个宏:
#define AT_NONCACHEABLE_SECTION_ALIGN(var, alignbytes) \
__attribute__((section("NonCacheable,\"aw\",%nobits @"))) var __attribute__((aligned(alignbytes)))
其中nobits表示该段为bss段,无需写入Flash。这里还加了字节对齐的属性,一般我们是4字节对齐,但有一些特殊的用例就有特殊的字节对齐的要求,比如eLCDIF的framebuffer需要8字节对齐。