堆
是一种完全二叉树,分为大堆,小堆
如果有一个关键码的集合 int K[ ] = {27,15,19,18,28,34,65,49,25,37} ; 把它的所有元素按完全二叉树的顺序存储方式存储
在一个一维数组中,并满足:Ki <=K2*i+1 且Ki <=K2*i+2 ( Ki >=K2*i+1 且Ki >=K2*i+2) i = 0,1,
2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
建堆的方式
有两种,1.向上建堆,2.向下建堆
向上建堆
时间复杂度为:O(N*logN)
typedef int HPDataType;
//交换函数
void Swap(HPDataType* a, HPDataType* b) {
HPDataType temp = *a;
*a = *b;
*b = temp;
}
//向上调整的条件是:调整的child结点之前的结点应该也为大堆/小堆,所以,向上调整建堆的时候,是从数组的第一个元素开始
void ADjustUp(HPDataType* a, int child) {
//向上调整
int parent = (child - 1)/2;
while (child >0) //child!=0
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);//取地址进行交换
//进行交换
child = parent;
parent = (child - 1) /2;
}
else {
break;
}
}
}
//向上建堆
//for (int i = 0; i < n; i++) {
// ADjustUp(arr, i);
//}
int main(){
int arr[]={
23,23,1,32,12,3,12,31,324};
int n=sizeof(arr)/sizeof(arr[0]);//得到数组的个数大小
//n-1表示为数组最后一个元素的下标,(n-1-1)/2得到其父节点,从父结点开始,向下调整
for (int i = 0; i < n; i++) {
ADjustUp(arr, i);
}
}
向下建堆
时间复杂堆为:O(N)
typedef int HPDataType;
//交换函数
void Swap(HPDataType* a, HPDataType* b) {
HPDataType temp = *a;
*a = *b;
*b = temp;
}
//向下调整建堆的条件为:左右子树都为大堆/小堆,所以从最后一个结点开始,又因为如果是叶子结点的话,本身调整是没有意义的,所以就从倒数第二层开始
void AdjustDown(HPDataType* a, int n, int parent) {
int child = parent * 2 + 1;//先找到左孩子的位置
while (child < n) {
//从左右孩子里面选一个
if (child + 1 < n && a[child + 1] > a[child]) {
//如果右孩子存在,且,右孩子大于左孩子
child++;//
}
if (a[child] > a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
//向下建堆
int main(){
int arr[]={
23,23,1,32,12,3,12,31,324};
int n=sizeof(arr)/sizeof(arr[0]);//得到数组的个数大小
//n-1表示为数组最后一个元素的下标,(n-1-1)/2得到其父节点,从父结点开始,向下调整
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(arr, n, i);
}
}
计算两种方式的时间复杂度
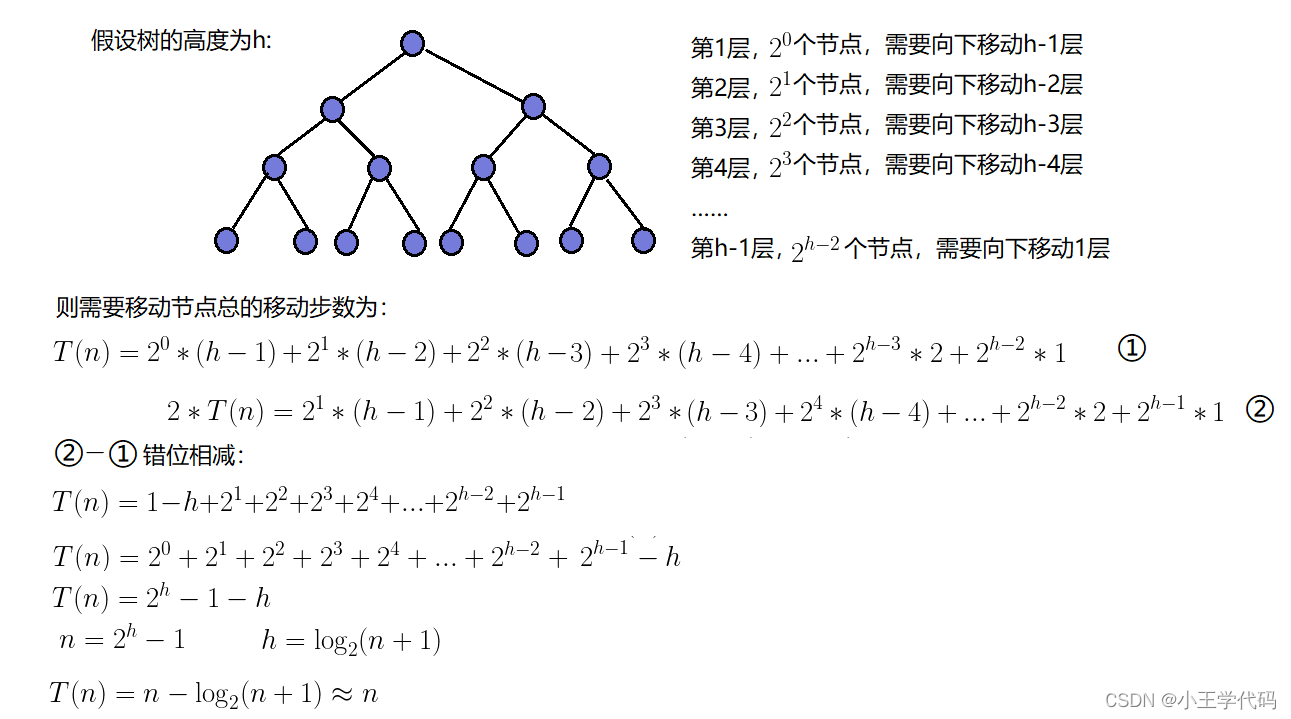
我们可以看到的是向下调整建堆时间复杂度更小,我们通过每一层的每一个结点的最多需要调整的次数为依据,假设高度为h,如果是向上调整的话,最后一个结点(最后一层,也就是2^(h-1)个结点),最多调整h-1次,向上的时候需要调整的每一层结点变少,层数变少,所以最后肯定是总调整次数更多
如图所示:这个图可以从数学的角度上来解决这个问题
堆排序
采用向上或者是向下调整的方法,最后实现排序,最后的时间复杂度为:O(N*logN)
//所以不管是向上还是向下建堆,时间复杂度都是为O(N*logN)
void HeapSort(int arr[],int n){
//比较偏向于向下调整建堆 时间复杂度:O(N)
for(int i=(n-1-1)/2;i>=0;i--){
AdjustDown(arr,n,i);
}
//向上建堆,时间复杂度为 O(N*logN)
//for (int i = 0; i < n; i++) {
// ADjustUp(arr, i);
//}
//进行排序,如果想要升序,那就建大堆,然后进行向下调整
int end = n - 1;//从最后一个结点开始
while (end>0) {
Swap(&arr[end], &arr[0]);
AdjustDown(arr, end, 0);//向下调整
end--;
}
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
}
int main()
{
int arr[]={
2,231,2,3,12,312,3,123,423,4,2};
int n=sizeof(arr)/sizeof(arr[0]);
HeapSort(arr,n);
return0;
}
Top-K问题
Top-K问题:从N个数据中找出前k个最大/最小的数
当然,在N的数值不是很大的时候,我们可以使用堆排序的方法,找到对应的前k个数值,但是当N的个数为10亿,或者是100亿的时候,这个数据的处理量就不能用原本的简单的堆排序方法啦
思路如下
假如说是100亿个数据量,我们由以下的内存换算可知,100亿个整数的数据量就是将近40G,所以不能单纯用简单的堆排序来运算
新的思路如下:
- 建立一个大小为k的数组,将前k个数值建成一个小堆
- 最后遍历剩余的数值,对于每一个数值,都进行向下调整(如果是这个数值大于顶部结点,就代替他,并进行向下调整)
- 最后这个小堆的数据就是最大的前k个
void AdjustDown(int* a, int n,int parent) {
int child = parent * 2 + 1;//先找到左孩子
while (child < n) {
//对于小堆的向下调整
if (child + 1 < n && a[child + 1] < a[child]) {
//如果右孩子大于左孩子,那么就进行交换
child++;
}
if (a[child] < a[parent]) {
int temp = a[child];
a[child] = a[parent];
a[parent] = temp;
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
void PrintTopK(const char*file,int k){
//输出前k个数值
//1.我们先创建为k个数据的小堆
int*topK=(int*)malloc(sizeof(int)*k);
assert(topK);
FILE*fout=fopen(file,"r");//读取文件 file
if(fout==NULL){
perror("open fail");
return;
}
//读取前k个数值做小堆
for(int i=0;i<k;i++){
fscanf(fout,"%d",&topK[i]);//读取前k个数值在数组topK中
}
for(int i=(k-2)/2;i>=0;i--){
AdjustDown(topK,k,i);//将topK数组建立小堆
}
//2.将剩余的n-k个元素依次于对顶元素进行交换,不满则替换
int val=0;
int ret=fscanf(fout,"%d",&val);
while(ret!=EOF){
//如果文件中的数值全部被读取,那么就会返回EOF
if(val>topK[0]){
topK[0]=val;//直接赋值即可,不必要交换
AdjustDown(topK,k,0);//向下调整
}
ret=fscanf(fout,"%d",&val);
}
for(int i=0;i<k;i++){
printf("%d",topK[i]);//打印topK数组中k个数值,这就是文件中n个数值中最大的前k个数
}
print("\n");
free(topK);
fclose(fout);
}
void CreateNData(){
//创建N个数据
int n=1000000;
srand(time(0));//使用随机数前要i使用这个代码
const char*file="data.txt";
FILE*fin=fopen(file,"w");
if(fin==NULL){
perror("fopen fail");
return;
}
for(int i=0;i<n;i++){
int x=rand()%10000;
fprintf(fin,"%d\n",x);//读写n个数据在fin所对应的“data.txt”文件中
}
fclose(fin);//关闭文件,这样才能正确的在硬盘文件中“data.txt”存储数值
}
int main()
{
CreateNData();
PrintTopK("data.txt",10);//表示从文件data.txt中读取前10个最大的数值
return 0;
}
实验结果如下:成功读取出来1000000随机数中前k个最大的数字

本文主要是对于堆的定义,堆的两种创建方式,向上建堆和向下建堆,进行代码演示,并对其分析时间复杂度,且实现了堆排序,实际上堆排序就是先建立堆(向上向下都可,建议向下),然后使用while循环,循环n-1次对于头尾进行交换,然后进行向下调整,上文有详解,最后是对于Top-K堆问题的解释,并附上代码进行演示