文章目录
项目主页:spinnerf3d.github.io (包含论文与代码)
摘要
编辑任务:从3D场景中移除不需要的对象
NeRF已经成为一种流行的新视角合成方法。然而,编辑和操作NeRF场景仍然是一个挑战。其中一个重要的编辑任务是从3D场景中移除不需要的对象,并对其进行修复,使得替换区域在视觉上是合理的并与其上下文一致。
本文方法:给定一组带姿态图像 和 单个输入图像的稀疏注释,首先获取目标对象的3D分割掩码。然后,我们引入了一种基于感知优化的方法,利用学习的2D图像inpainting 模型 将其信息转化到3D空间中,并确保视角一致性。
文章引入一个真实场景数据集,来评估3D场景inpainting 方法。
提示:以下是本篇文章正文内容,下面案例可供参考
一、简介
随着nerf 的广泛使用,编辑和操纵 nerf 场景的需求将继续增长,包括删除对象和图像inpaiting 3D场景,类似于已被充分研究的2D图像inpaiting 任务[23]。然而,障碍不仅是在三维inpaiting 过程本身,还存在于获得输入的分割mask。首先,NeRF场景被隐式地编码在神经映射权值中,导致一个纠缠和不可解释的表示,这不是易于操作的。此外,3D场景的inpaiting 必须在一个给定的视图中生成感知现实的外观,还必须保持基本的3D属性,如跨视图的外观一致性和几何合理性。该方法需要对多个图像进行注释(并保持多视角一致)对用户来说是一种负担。
一个吸引人的替代方案是对单个视图只期望最小的一组注释。这激发了一种能够从单视图稀疏注释中获得对象的视图一致的3D分割 mask 的方法。
本文方法:首先从一个目标对象上的少量用户定义的图像点(以及外部的一些负样本),算法使用基于视频的模型[4]初始化掩模,并通过拟合 semantic NeRF [36,76,77]将其提升为一个连贯的3D分割。然后,在应用预先训练的二维画家[48]多视图图像集,一个定制NeRF拟合过程用于重建三维画场景,利用感知损失[72]负责 2维inpainting 的不一致。

二、相关工作
1.Image Inpainting
早期的技术依赖于patch[9,16],最近的神经方法优化感知实现和重建(例如,[22,27,48])。为了提高视觉保真度,各种研究方向仍在继续被探索,包括对抗性训练([40,73])、框架的改进([27,30,62,63])、多元输出([73,75])、多尺度处理([21,58,69])和感知指标(如[22,48,72])。
我们的工作利用了预训练的LaMa [48],它应用了受Transfirmer [11,12]启发的频域变换[7]。然而,这些都不能将问题提升到3D图像中;因此,以一致的方式修复一个场景的多个图像仍然是一项未被充分探索的任务。我们的方法通过基于多视图的NeRF模型直接在三维中操作。
2.NeRF 操作
基于可微体积渲染[18,52]和位置编码[13,49,53],NeRFs [35]在新视图合成中表现出了显著的性能。控制NeRF场景仍然是一个挑战。Clip-NeRF [55]、Object-NeRF [64]、LaTeRF [36]和其他[25,32,70]引入了改变和完成由NeRFs表示的对象的方法;然而,它们的性能仅限于简单的对象,而不是具有显著杂乱和纹理的场景,或者它们专注于其他任务,而不是一般的 inpainting(例如,重新上色或变形)。
与我们的方法最密切相关的是NeRF-In [31],一个同期未发表的作品,它使用2D图像的几何和亮度先验,但没有解决不一致性;相反,它使用简单的像素损失,来减少用于拟合的视图数量,从而降低了最终视图合成质量。类似地使用像素损失,同期的 Remove-NeRF模型[60]通过排除基于不确定机制的视图来减少不一致性。相比之下,我们的方法能够通过一种感知的[72]训练机制,以一种视图一致的方式合并二维信息,从而绘制出具有挑战性的现实世界场景的NeRF表示。这避免了对 inpainting 的过度限制(通常会导致模糊)。
3. 背景: NeRF 知识
请见博客【三维重建】NeRF原理+代码讲解
三、方法
给定一组RGB图像,I = {Ii} ni=1,以及相应的3D姿态,g = {Gi} ni=1,和相机内在矩阵,K,模型期望一个具有稀疏用户注释的“源”视图。从这些输入中,我们生成了一个场景的NeRF模型,能够从任何新的观点合成一个 inpaint 的图像。
我们首先从单视图注释源(4.1.1节)中获得一个初始的3D掩码,然后拟合一个semantic NeRF,以提高掩码的一致性和质量(4.1.2节)。在4.2中,我们描述了视图一致的inpaint 方法,它将视图和恢复的mask 作为输入。我们的方法利用二维inpainter [48]的输出作为外观和几何先验,来监督一个新的NeRF的拟合。
3.1.多视图分割
3.1.1掩码初始化
将带注释的源代码视图表示为I1 。将对象和源视图的稀疏信息给给一个交互式分割模型Edgeflow15],以估计初始源对象掩码 M 1 ^ \hat{M~1~} M 1 ^。然后将训练视图作为一个视频序列,与 M 1 ^ \hat{M~1~} M 1 ^ 一起给出一个视频实例分割模型V [4,57],以计算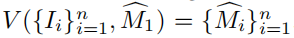 ,得到每个视图的mask。初始的掩码
,得到每个视图的mask。初始的掩码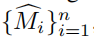
,通常在边界附近是不准的,因为训练视图并不是相邻的视频帧。因此,我们使用语义NeRF模型[36,76,77]来解决不一致性并改进 mask(4.1.2),从而获得每个输入视图的 mask 用于inpaint(4.2)。
3.1.2基于nerf的分割
多视图分割模块输入为:RGB图像、相应的相机内在和外部参数,以及初始掩码,训练一个semantic NeRF [76,网络见图2];对于点x和视图方向d,除了密度σ(x)和颜色c(x,d),它返回一个“objectness”的逻辑值 s(x)。然后得到目标的概率 p(x) = Sigmoid(s(x) )。 我们使用快速收敛的 Instant-NGP[3,37,38]作为NeRF架构。
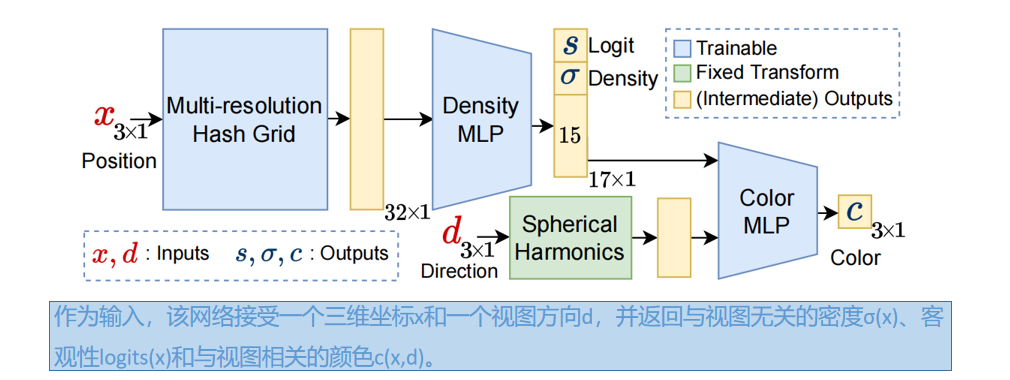
与光线 r 相关的期望objectness逻辑值,是通过渲染 r 上点的密度,而不是颜色得到的:
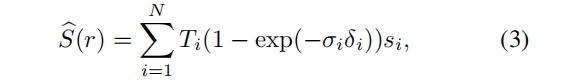
为简单起见,s(r(ti)) 用 si 表示。然后使用分类损失来监督一个射线,objectness的概率,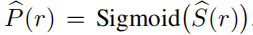
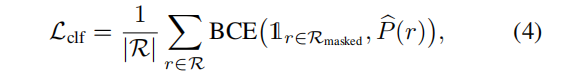
训练 Lcls时,color 被分离以限制对 logits 值的监督更新。这将防止更改现有的几何结构,因为梯度更新会改变密度值 σ。
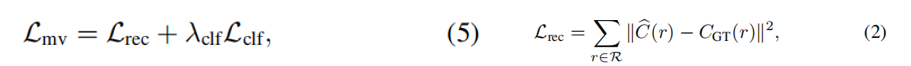
经过优化后,通过对目标概率进行阈值化,并对概率大于0.5的像素进行mask,得到了3d一致性掩模{Mi}n i=1。最后,我们采用两阶段优化,进一步改进mask: 在获得初始三维mask后,从训练视图呈现mask,并用于监督二次多视图分割模型作为初始猜想。
3.2.多视图 Inpainting
图3显示了视图一致的Inpainting NeRF的概述,使用以下损失训练:

其中,L’rec 为 未mask 像素的重建损失,LLPIPS 和Ldepth 定义了感知和深度损失,权值为λ.
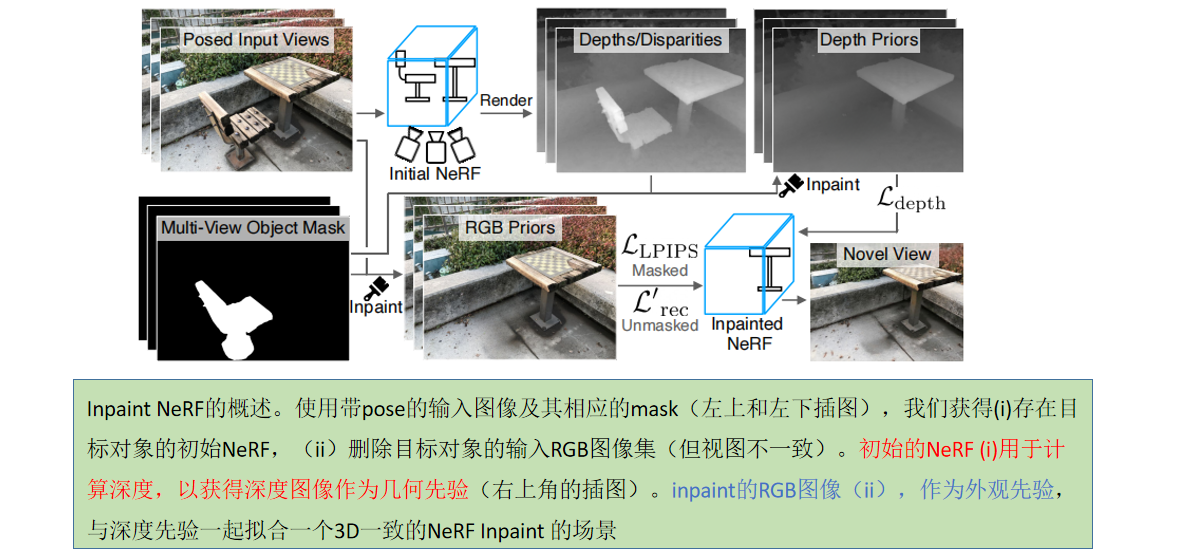
3.2.1 RGB先验
Inpaint NeRF 使用RGB输入,相机的内在和外在参数,以及相应的对象 mask,以拟合一个 删除了mask目标的NeRF到场景。首先,将每个图像和掩模对(Ii,Mi)给图像 inpainter INP: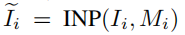
由于每个视图都是独立 inpaint 的,直接用于监督NeRF,由于三维不一致,会导致模糊的结果(见图7)。在本文中,我们没有使用均方误差(MSE)来优化掩蔽区域,而是使用感知损失LPIPS [72]来优化图像的掩蔽部分,同时仍然使用MSE来优化未掩蔽部分,损失的计算方法如下:
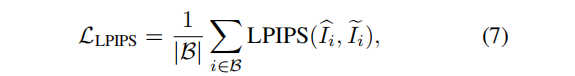
其中,B是介于1到n之间的batch 索引, I ^ \hat{I} I^ i 是使用NeRF渲染的第i个视图。多视图Ipaint NeRF 和分割模型 semantic NeRF 使用相同的架构(见图2)
3.2.2深度先验
即使有感知损失,Inpaint 视图之间的差异也会错误地引导模型收敛到退化的几何图形(例如,在摄像机附近可能会形成“雾”几何图形,以解释每个视图的不同信息)。因此,我们使用 inpaint 的深度图作为NeRF模型的额外指导,并在计算感知损失时分离权重,并使用感知损失只拟合场景的颜色。为此,我们使用了一个对包含不需要的对象的图像进行了优化的NeRF,并渲染了与训练视图对应的深度地图。深度图的计算方法是用到相机的距离而不是点的颜色代替等式 1:
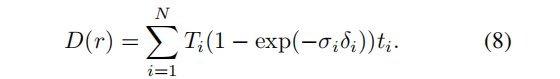
将渲染的深度给一个 inpainter,以获得已绘制的深度图: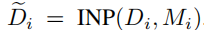
使用LaMa [48]进行深度 inpaint ,有足够高质量的结果,作为预处理步骤计算。然后,这些深度图被用来监督已绘制的NeRF的几何形状,通过其渲染深度的 L2距离:
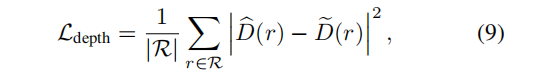
3.2.3基于patch 的优化
计算感知损失(等式7)需要在优化期间呈现完整的输入视图。因为渲染每个像素需要多个向前通过MLP,对于高分辨率图像,这是一个昂贵的过程,导致问题如(i)批大小|B|必须小,减小相应的内存中的计算图;(ii)缓慢优化,即使批大小为|B| = 1。
一个简单的解决方案是渲染一个缩小后的图像,并将其与缩小后的 inpaint 的图像进行比较;然而,如果缩小系数很大,这就会导致信息的丢失。根据图像的工作(例如,SinGAN [46]和DPNN [14])和3D作品(例如,ARF [71]),我们在patch 的基础上执行计算;我们不是渲染完整的视图,而是渲染较小的补丁,并根据感知损失将它们与 inpaint 图像中的对应patch 进行比较。
为了拟合unmask 的区域,L’rec (Eq 6)只从 unmask 的像素中采样光线。通过分离感知损失和重建损失,我们防止了mask 内的不一致,同时避免了对场景的其余部分的不必要的变化。
3.2.4掩码精炼
在这里,我们考虑进一步利用多视图数据来指导图像 inpaint。特别是,目前二维inpainter 生成的部分训练图像可能在其他视图中可见;在这种情况下,没有必要对这些细节产生幻觉,因为它们可以从其他视图中检索到。为了防止这种不必要的inpaint,我们提出了一种mask refine 的方法:
对于每个源图像、深度和mask 元组,(Is、Ds、Ms),我们替换至少一个其他视图中可见的 I 和 d 中的像素,以缩小源 mask,在这个细化步骤之后,只有在所有训练视图中被不希望的对象遮挡的部分 I 和 d 将保持mask。因此,inpainter 必须填充更小的区域,从而改进 inpaint 。
四、实验

将我们的多视图分割模型与神经体积对象选择(NVOS)[44])、视频分割[4]和 人工注释mask(GT)进行了定性比较。我们的两阶段方法是指运行我们的多视图分割模型两次,第一次运行的输出作为第二次运行的初始化(见4.1.2)。我们的方法比NVOS的噪声小,NVOS也错过了目标的一些片段(例如,底部一行最低的花),但比单独的视频分割捕捉更多的细节(例如,花的模糊边缘)。我们的两阶段方法有助于填补单阶段输出的一些缺失的方面。

请注意,合成的视图彼此保持一致性;然而,依赖于视图的效果仍然存在(例如,钢琴裸露部分的照明)

由NeRF(在未掩蔽图像上),NeRF-In,NeRF-In(与单一掩蔽训练图像),和我们的方法。NeRF-In明显更加模糊,而NeRF-In(单一的)往往在细节更接近掩模边界的边缘时遇到困难
五、安装与代码讲解
1.项目安装
先克隆项目,然后安装依赖
git clone
pip install -r requirements.txt
pip install -r lama/requirements.txt
然后准备数据,以下是官方提供的数据链接:
https://drive.google.com/drive/folders/1N7D4-6IutYD40v9lfXGSVbWrd47UdJEC?usp=share_link
下载其中的statue压缩包,并用以下命令解压
unzip statue.zip -d data
其数据格式如下(images2是较大的分辨率,label中包含待去除目标的mask):
statue
├── images
│ ├── IMG_2707.jpg
│ ├── IMG_2708.jpg
│ ├── ...
│ └── IMG_2736.jpg
└── images_2
├── IMG_2707.png
├── IMG_2708.png
├── ...
├── IMG_2736.png
└── label
├── IMG_2707.png
├── IMG_2708.png
├── ...
└── IMG_2736.png
如果要训练自己的数据,可以安装colmap,用以下代码求出位姿信息:
python imgs2poses.py <your_datadir>
2.跑原始NeRF,得到深度信息:
rm -r LaMa_test_images/*
rm -r output/label/*
python DS_NeRF/run_nerf.py --config DS_NeRF/configs/config.txt --render_factor 1 --prepare --i_weight 1000000000 --i_video 1000000000 --i_feat 4000 --N_iters 4001 --expname statue --datadir ./data/statue --factor 2 --N_gt 0
之后,渲染的disparities (反深度) 就会在 lama/LaMa_test_images文件夹中, 相关的前景mask标签在 lama/LaMa_test_images/label.
3.运行 LaMa 来产生几何和表观引导
LaMa主要结合mask,将深度图和RGB图中的目标去掉,并用背景填充,得到看着很真实的inpaint 图像。
cd lama
export TORCH_HOME=$(pwd) && export PYTHONPATH=$(pwd)
python bin/predict.py refine=True model.path=$(pwd)/big-lama indir=$(pwd)/LaMa_test_images outdir=$(pwd)/output
inpainted disparities(修改后的深度图) 在lama/output/label. 复制并将其放在 data/statue/images_2/depth.,代码如下:
dataset=statue
factor=2
rm -r ../data/$dataset/images_$factor/depth
mkdir ../data/$dataset/images_$factor/depth
cp ./output/label/*.png ../data/$dataset/images_$factor/depth
然后产生 inpainted RGB 图像:
dataset=statue
factor=2
rm -r LaMa_test_images/*
rm -r output/label/*
cp ../data/$dataset/images_$factor/*.png LaMa_test_images
mkdir LaMa_test_images/label
cp ../data/$dataset/images_$factor/label/*.png LaMa_test_images/label
python bin/predict.py refine=True model.path=$(pwd)/big-lama indir=$(pwd)/LaMa_test_images outdir=$(pwd)/output
rm -r ../data/$dataset/images_$factor/lama_images
mkdir ../data/$dataset/images_$factor/lama_images
cp ../data/$dataset/images_$factor/*.png ../data/$dataset/images_$factor/lama_images
cp ./output/label/*.png ../data/$dataset/images_$factor/lama_images
inpainted RGB 图像在 lama/output/label, 并复制到了 data/statue/images_2/lama_images.
4.运行多视角 inpainter NeRF
使用以下命令, 最后的 inpainted NeRF 优化将会展开. inpainted NeRF 的结果视频,将会按照每 i_video 保存一次.总训练次数 N_iters .
python DS_NeRF/run_nerf.py --config DS_NeRF/configs/config.txt --i_feat 200 --lpips --i_weight 1000000000000 --i_video 1000 --N_iters 10001 --expname statue --datadir ./data/statue --N_gt 0 --factor $factor
5.关键代码
- 读入数据,预处理,得到一些 GroundTruth
use_batching=True,表示将所有图像数据叠加在一起,并从中采样射线;
# 0.首先得到 colmap预处理得到的深度信息----------------------------------------------------------
if args.dataset_type == 'llff':
if args.colmap_depth:
depth_gts = load_colmap_depth( args.datadir, factor=args.factor, bd_factor=.75, prepare=args.prepare) # n_img个list,每一个包含: depth(3879) coord(3879,2) weight(3879)归一化
images, poses, bds, render_poses, i_test, masks, inpainted_depths, mask_indices = load_llff_data(args.datadir, args.factor, recenter=True, bd_factor=.75, spherify=args.spherify, prepare=args.prepare, args=args)
# mask代表前景掩码
H, W, focal = hwf
# 1.创建 nerf model---------------------------------------------------------------------------
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf_tcnn(args)
# 2.得到 rays_rgb(射线o,d 加上img,mask)---------------------------------------------------------
labels = np.repeat(masks[:, None], 3, axis=1) # [N, 3, H, W, 1]
rays = np.stack([get_rays_np(H, W, focal, p)
for p in poses[:, :3, :4]], 0) # 维度[N, ro+rd, H, W, 3],比如 (29, 2, 378, 504, 3)
rays_rgb = np.concatenate([rays, images[:, None]], 1) # (29, 2+1, 378, 504, 3) ray融入了img,
rays_rgb = np.concatenate([rays_rgb, labels], -1) # (29, 2+1, 378, 504, 3+1) ray融入了img,mask
rays_rgb = np.reshape(rays_rgb, [-1, 3, 4]) # (29, 378, 504, 2+1, 3+1) --> (5524848, 3, 4)
# 3.得到 rays_inp (射线o,d 加上img,inpainted_depths)-----------------------------------------------
rays = np.stack([get_rays_np(H, W, focal, p)
for p in poses[:, :3, :4]], 0) # [N, ro+rd, H, W, 3] (29, 2, 378, 504, 3)
labels = np.expand_dims(inpainted_depths, axis=-1) # [N, H, W, 1]
labels = np.repeat(labels[:, None], 3, axis=1) # [N, 3, H, W, 1]
rays_inp = np.concatenate([rays, images[:, None]], 1) # (29, 2+1, 378, 504, 3) ray融入了img
rays_inp = np.concatenate([rays_inp, labels], -1) # (29, 2+1, 378, 504, 3+1) ray融入了img, inpainted_depths
rays_inp = np.reshape(rays_inp, [-1, 3, 4]) # (29, 378, 504, 2+1, 3+1) --> (5524848, 3, 4)
# 4.得到 rays_depth(colmap得到的4个深度值)-----------------------------------------------------------
if args.colmap_depth(True):
for i in i_train(循环29张图):
rays_depth = np.stack(get_rays_by_coord_np(H, W, focal, poses[i, :3, :4], depth_gts[i]['coord']),
axis=0) # 2 x N x 3
# depth_gts[i]['coord']维度(2711,2),是图像上前景点的绝对坐标。这行代码,根据坐标得到对应的2711个射线
# 具体函数定义如下:
def get_rays_by_coord_np(H, W, focal, c2w, coords):
i, j = (coords[:, 0] - W * 0.5) / focal, -(coords[:, 1] - H * 0.5) / focal # (2711) (2711)
dirs = np.stack([i, j, -np.ones_like(i)], -1) # (2711, 3)
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3, :3], -1)
rays_o = np.broadcast_to(c2w[:3, -1], np.shape(rays_d)) # c2w 最后一列是原点O
return rays_o, rays_d # (2711, 3) (2711, 3)
depth_value = np.repeat(depth_gts[i]['depth'][:, None, None], 3, axis=2) # (2711) 广播至(2711,1 ,3) 绝对深度
weights = np.repeat( depth_gts[i]['weight'][:, None, None], 3, axis=2) # (2711) 广播至(2711,1 ,3) 归一化权重
rays_depth = np.concatenate([rays_depth, depth_value, weights], axis=1) # (2711,4,3) 4分别代表 colmap估计的射线0+d,深度,权重
rays_depth_list.append(rays_depth)
rays_depth = np.concatenate(rays_depth_list, axis=0) # (112377, 4 3) 29张图的前景射线,深度叠加在一起
# 5.得到 rays_rgb_clf 和 rays_inp--------------------------------------------------------------------
rays_rgb_clf = rays_rgb[rays_rgb[:, :, 3] == 0].reshape(-1, 3, 4) # (5524848,3,4) -> (4827239,3,4) 只保留了mask==0的部分
rays_inp = rays_inp[rays_rgb[:, :, 3] != 0].reshape(-1, 3, 4) # (5524848,3,4) -> (697609,3,4) 只保留了inpaint_mask!=0的部分
# 6.修改 rays_rgb
if not args.prepare:
rays_rgb = rays_rgb[rays_rgb[:, :, 3] == 1].reshape(-1, 3, 4) # (5524848,3,4) -> (23906,3,4)只保留了mask==0的部分
# 7.迭代产生 GroundTruth
raysRGB_iter = iter(DataLoader(RayDataset(rays_rgb), batch_size=N_rand, shuffle=True, num_workers=0,
generator=torch.Generator(device=device)))
raysINP_iter = iter(DataLoader(RayDataset(rays_inp), batch_size=N_rand, shuffle=True, num_workers=0,
generator=torch.Generator(device=device)))
raysRGBCLF_iter = iter(DataLoader(RayDataset(rays_rgb_clf), batch_size=N_rand, shuffle=True, num_workers=0,
generator=torch.Generator(device=device)))
batch_inp = next(raysINP_iter).to(device) # (1024,3,4)
batch = next(raysRGB_iter).to(device) # (1024,3,4)
batch_clf = next(raysRGBCLF_iter).to(device) # (1024,3,4)
# 7.1 target_s
batch_rays, target_s = batch[:2], batch[2]
target_s, label_s = target_s[:, :3], target_s[:, 3] #(1024,3)(1024)射线的颜色和 mask(都是1)
# 7.2 target_inp
batch_inp, target_inp = batch_inp[:2], batch_inp[2]
target_inp, depth_inp = target_inp[:, :3], target_inp[:, 3] #(1024,3)(1024)inpaint mask中的射线和深度
# 7.3 batch_clf
batch_rays_clf, target_clf = batch_clf[:2], batch_clf[2] #(1024,3)(1024)只保留mask=0的前景 射线的颜色和 mask(都是0)
# 7.4 得到来自colmap的深度 gt
raysDepth_iter = iter(DataLoader(RayDataset(rays_depth), batch_size=N_rand, shuffle=True, num_workers=0, generator=torch.Generator(device=device))) if rays_depth is not None else None
batch_depth = next(raysDepth_iter).to(device)
batch_rays_depth = batch_depth[:2] # 2 x B x 3
target_depth = batch_depth[2, :, 0] # B=1024
ray_weights = batch_depth[3, :, 0] # B=1024
- 读取待删除目标的mask,并用cv2.dilate做扩张(主要考虑到精准的mask,可能没涵盖目标的阴影等)
for i, f in enumerate(mskfiles): # mskfiles就是前景的mask,在label文件夹内
try:
msk = imread(f)
msk = msk / msk.max()
msk = cv2.resize( msk, (imgs.shape[1], imgs.shape[0]), interpolation=cv2.INTER_NEAREST)
print(msk.shape)
msk = cv2.dilate(msk, np.ones((5, 5), np.uint8), iterations=5)
masks.append(msk)
mask_indices.append(i)
2.DS_NeRF/run_nerf_helpers_tcnn.py中的 NeRF_TCNN函数,将xyz(位置)和d(射线方向),映射成颜色和密度值:
共渲染4次,每次输入都是不同的 ray:
rgb, disp, acc, depth, extras = render(H, W, focal, chunk=args.chunk,
rays=batch_rays_clf, verbose=i < 10, retraw=True, **render_kwargs_train)
rgb_complete, _, _, _, extras_complete = render(H, W, focal, chunk=args.chunk,
rays=batch_rays, verbose=i < 10, retraw=True, detach_weights=True, **render_kwargs_train)
_, disp_inp, _, _, extras_inp = render(H, W, focal, chunk=args.chunk,
rays=batch_inp, verbose=i < 10, retraw=True, **render_kwargs_train) # disp_inp (1024)预测每个点weight得到的深度图
_, _, _, depth_col, extras_col = render(H, W, focal, chunk=args.chunk,
rays=batch_rays_depth, verbose=i < 10, retraw=True, depths=target_depth, **render_kwargs_train) # depth_col (1024)
每次渲染代码相同,具体 forward 过程如下
def forward(self, input):
x = input[:, :3] # (65536,3)
d = input[:, 3:] # (65536,3)
# sigma
x = (x + self.bound) / (2 * self.bound) # to [0, 1] self.bound=100
x = self.encoder(x) # 16倍分辨率的hash表,得到(65536,32)
h = self.sigma_net(x) # 得到(65536,16)
sigma = h[..., 0]
geo_feat = h[..., 1:]
# color
d = (d + 1) / 2 # tcnn SH encoding requires inputs to be in [0, 1]
d = self.encoder_dir(d)
h = torch.cat([d, geo_feat], dim=-1)
h = self.color_net(h)
# sigmoid activation for rgb
color = h # (65536,3)
outputs = torch.cat([color, sigma[..., None]], -1)
return outputs
- 计算损失
optimizer.zero_grad()
img_loss = img2mse(rgb, target_clf) # 输入(1024,3) 输出:0.05 函数img2mse = lambda x, y: torch.mean((x - y) ** 2)
psnr = mse2psnr(img_loss) # 函数 mse2psnr = lambda x: -10. * torch.log(x) / torch.log(torch.Tensor([10.]))
if not args.masked_NeRF and not args.object_removal: # True
img_loss += img2mse(rgb_complete, target_s) # rgb_complete 是用batch_rays渲染出的颜色
if 'rgb0' in extras_complete and not args.no_coarse:
img_loss0 = img2mse(extras_complete['rgb0'], target_s)
img_loss += img_loss0
# 3.计算深度损失
if args.depth_loss:
if args.weighted_loss:
depth_loss = img2mse(depth_col, target_depth) # target_depth(1024),是colmap的深度
img_loss0 = img2mse(extras['rgb0'], target_clf) # (1024,3)
loss = loss + img_loss0
每隔300个 iter,计算一次LPIP语义损失
np.random.shuffle(idx) # 一个batch中,随机抽取几张图片
random_poses = poses[idx]
# 按比例裁剪出patch。实验中缩放因子分别是2,8
patch_len = (hwf[0] / / lpips_render_factor / / patch_len_factor,
hwf[1] / / lpips_render_factor / / patch_len_factor)
rgbs, disps, (Xs, Ys) = render_path(random_poses, hwf, args.chunk, render_kwargs_test,
render_factor=lpips_render_factor,rgb_require_grad=True,need_alpha=False,detach_weights=True,patch_len=patch_len,masks=masks[idx])
# 得到 (4,23,31,3) (4,23,31) 以及随机选的batch个中心点坐标
prediction = ((rgbs[_] - 0.5) * 2).permute(2, 0, 1)[None, ...] # (23,31,3)
target = ((images[idx[_]] - 0.5) * 2).permute(2, 0, 1)[None, ...]
target = transform(target)[:, :, Xs[_]:Xs[_] + patch_len[0], Ys[_]:Ys[_] + patch_len[1]] # (23,31,3)
# 计算损失(LPIPS就是预训练的vgg):
lpips_loss += LPIPS(prediction, target).mean()