CVPR 2023 | 最新主干FasterNet!
简介
论文:https://arxiv.org/pdf/2303.03667v2.pdf
代码:https://github.com/jierunchen/fasternet

以前的研究:
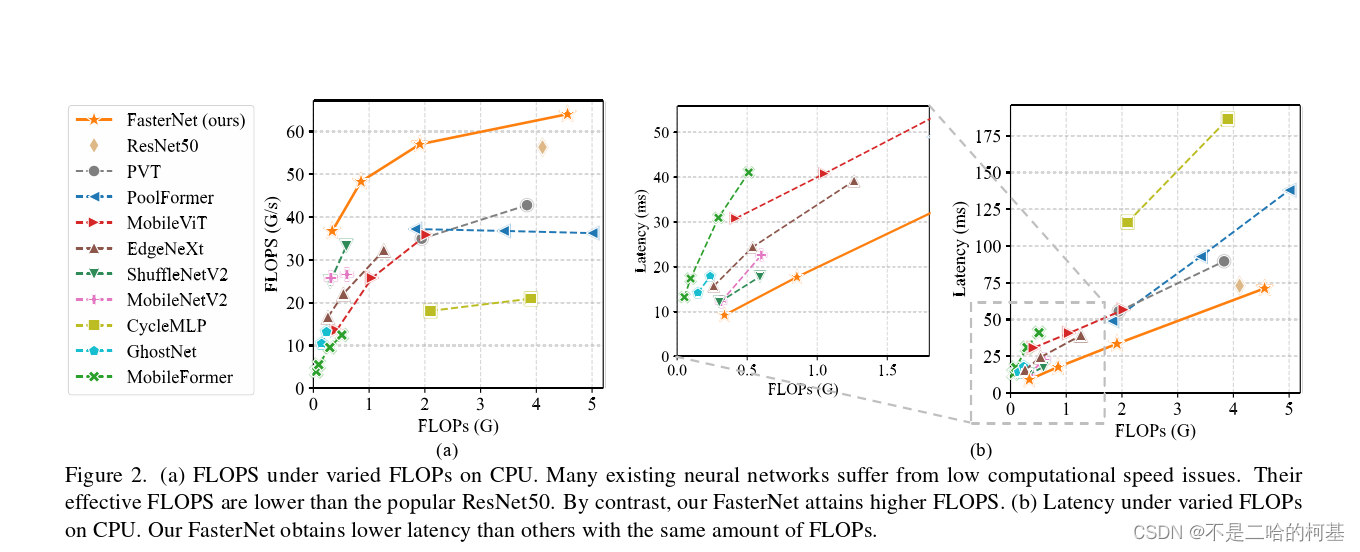
1、为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。
问题:
1、FLOPS低主要是由于运算符的频繁内存访问
作者干了什么:
- 指出了实现更高FLOPS的重要性,而不仅仅是为了更快的神经网络而减少FLOPs。
- 作者设计了一种的新的运算符,该运算符可以在减少FLOPs的情况下保持高FLOPS。
- 本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
- 基于PConv进一步提出FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。
介绍
神经网络在图像分类、检测和分割等各种计算机视觉任务中,一个巨大的趋势是追求具有低延迟和高吞吐量的快速神经网络,以获得良好的用户体验、即时响应和安全原因等。
MobileNet、ShuffleNet和GhostNet等利用深度卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在减少FLOPs的过程中,算子经常会受到内存访问增加的副作用的影响。MicroNet进一步分解和稀疏网络,将其FLOPs推至极低水平。尽管这种方法在FLOPs方面有所改进,但其碎片计算效率很低。此外,上述网络通常伴随着额外的数据操作,如级联、Shuffle和池化,这些操作的运行时间对于小型模型来说往往很重要。
延迟关系
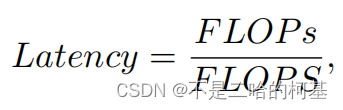
FLOPS (全部大写)是floating-point operations per second的缩写,意指每秒浮点运算次数。用来衡量硬件的性能。
FLOPs 是floating point of operations的缩写,是浮点运算次数,可以用来衡量算法/模型复杂度。
常用当然还有GFLOPs和TFLOPs
GFLOPS 就是 Giga Floating-point Operations Per Second,即每秒10亿次的浮点运算数,常作为GPU性能参数但不一定代表GPU的实际表现,因为还要考虑具体如何拆分多边形和像素、以及纹理填充,理论上该数值越高越好。1GFlops = 1,000MFlops。
相关工作
我们简要回顾了关于快速和高效神经网络的先前工作,并将这项工作与它们区分开来
CNN:它们利用滤波器的冗余性来减少参数和FLOP的数量,但在增加网络宽度以补偿精度下降的同时,也增加了内存访问。相比之下,我们考虑了特征图中的冗余,并提出了PConv来同时减少FLOPs和内存访问。

ViT,MLP,and variants:在本文中,我们重点分析了卷积操作,特别是DWConv,因为以下原因:第一,注意力相对于卷积的优势是不清楚或有争议的。其次,基于注意力的机制通常比卷积机制运行得更慢,因此对于当前的行业来说变得不太有利。最后,DW - Conv在许多混合模型中仍然是流行的选择,因此值得仔细检查。
Design of PConv and FasterNet
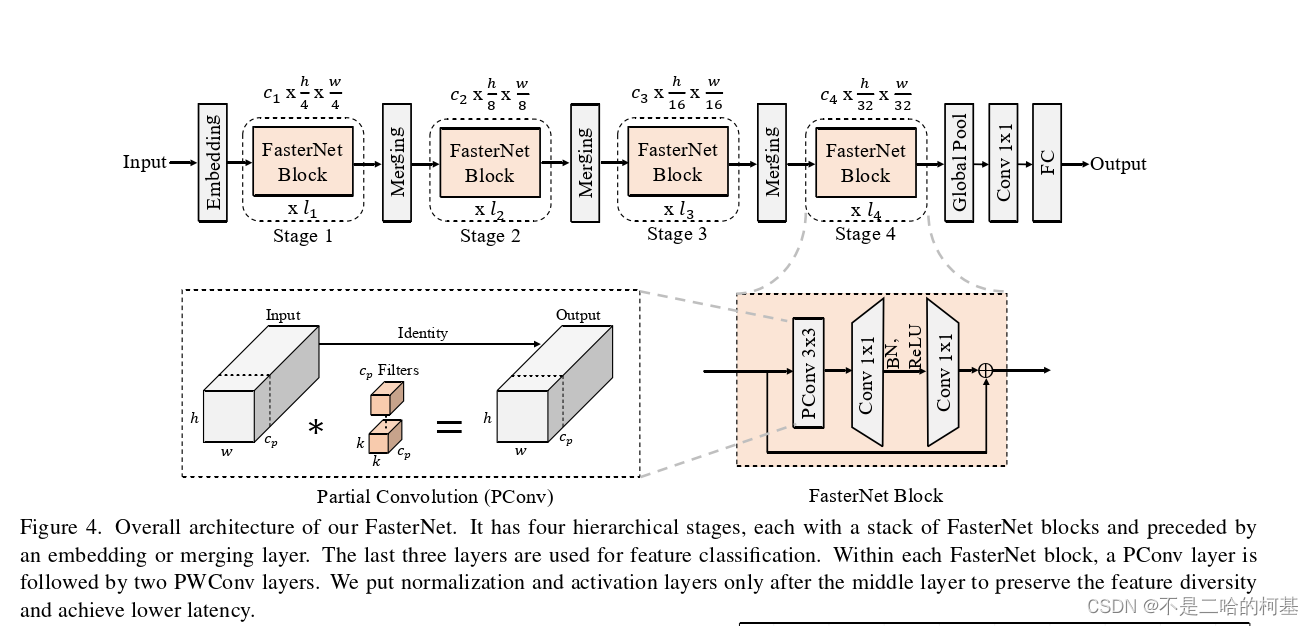
图4中的左下角说明了PConv的工作原理。它只需在输入通道的一部分上应用常规Conv进行空间特征提取,并保持其余通道不变。对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。因此,PConv的FLOPs仅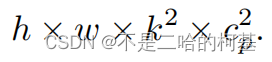
对于典型的r=1/4 ,PConv的FLOPs只有常规Conv的1/16。此外,PConv的内存访问量较小,即: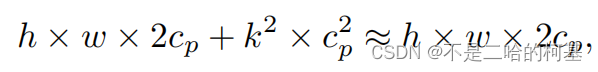
对于r=1/4,其仅为常规Conv的1/4。由于只有通道用于空间特征提取,人们可能会问是否可以简单地移除剩余的(c−)通道?如果是这样,PConv将退化为具有较少通道的常规Conv,这偏离了减少冗余的目标。