将大模型应用于知识检索技术架构
原创 大模型 机器AI学习 数据AI挖掘 2023-08-06 17:17
概述
在大型语言模型(LLM)的几乎所有实际应用中,都存在一些情况,您希望语言模型根据特定数据生成答案,而不是基于模型的训练集提供一般性答案。例如,公司聊天机器人应该能够引用公司网站上的特定文章,律师分析工具应该能够引用同一案件之前的文件。引入这些外部数据的方式是一个关键的设计问题。
从高层次来看,有两种主要的方法来引用特定数据:
-
在模型提示中插入数据作为上下文,并指导响应利用该信息。
-
通过提供数百或数千个提示<>完成对模型进行微调。
现有大型语言模型的知识检索的缺点。
对于基于上下文的方法:
模型的上下文大小有限,最新的davinci-003模型一次请求只能处理最多4000个标记。许多文档无法适应此上下文。处理更多的标记等同于更长的处理时间。在面向客户的场景中,这会降低用户体验。处理更多的标记等同于更高的API成本,如果上下文中的信息没有针对性,则不一定能获得更准确的响应。
对于微调方法:
生成提示<>完成对是耗时且可能昂贵的。
您想要引用信息的许多存储库都非常大。例如,如果您的应用程序是为正在参加美国MLE的医学生的学习辅助工具,则需要提供跨多个学科的培训示例的完整模型。
一些外部数据源变化很快。例如,基于每天或每周清空的客户支持队列重新训练模型并不是最佳选择。
关于微调的最佳实践仍在开发中。LLM本身可以用于协助生成训练数据,但可能需要一些复杂性才能有效实现。
简化后的解决方案
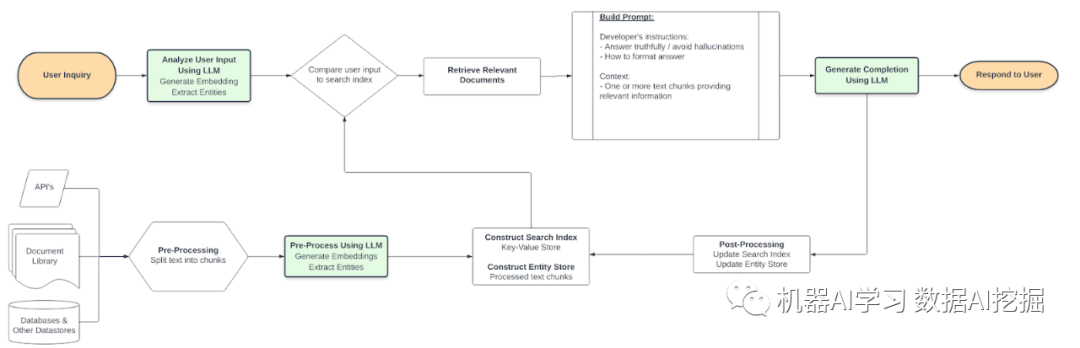
上述设计有多种名称,最常见的是“检索增强生成”(retrieval-augmented generation)RA或“RETRO”。相关链接和概念:
RAG:针对知识密集型自然语言处理任务的检索增强生成RETRO:通过从数万亿个标记中检索来改进语言模型REALM:检索增强语言模型预训练检索增强生成
(a)从语言模型之外检索相关信息(非参数方法),并使用提示中的上下文对LLM进行增强。该架构可以有效地绕过微调和仅基于上下文的方法的大部分限制。
检索
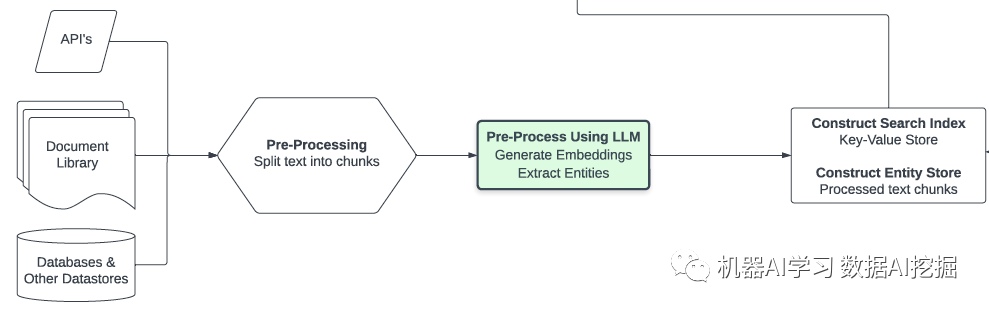
检索相关信息的值得进一步解释。如您所见,数据可能来自多个来源,具体取决于用例。为了使数据有用,它必须足够小,以便多个片段适合上下文,并且必须有一种方法来识别相关性。因此,一个典型的先决条件是将文本分成部分(例如,通过LangChain包中的实用程序),然后在这些块上计算嵌入。
语言模型嵌入是文本中概念的数值表示形式,似乎有无限的用途。这里是它们的工作原理:嵌入模型将文本转换为大型得分向量,可以与其他得分向量进行有效的比较,以协助推荐、分类和搜索等任务。我们将此计算结果存储到我将在下面通用地称为搜索索引和实体存储中-有关更高级讨论,请参阅下面的内容。

回到流程-当用户提交一个问题时,LLM以多种方式处理消息,但关键步骤是计算另一个嵌入-这次是用户的文本。现在,我们可以通过将新的嵌入向量与预先计算的完整向量集进行比较来在搜索索引和实体存储中进行语义搜索。这种语义搜索基于语言模型的“学习”概念,并不仅限于仅搜索关键词。通过此搜索的结果,我们可以定量地确定一个或多个相关文本块,这些文本块可以帮助用户了解他们的问题。
增强
使用相关文本块构建提示是直截了当的。提示以一些基本的提示工程开始,指导模型避免“幻想”,即编造一个听起来合理但不真实的答案。如果适用,我们指示模型以特定格式回答问题,例如“高”、“中”或“低”的顺序排名。最后,我们提供语言模型可以使用特定数据回答的相关信息。在最简单的形式中,我们只是简单地附加(“文档1:”+文本块1 + “文档2:”+文本块2 + ...)直到上下文得到填充。
最终,将组合后的提示发送给大型语言模型。从完成中解析答案并传递给用户。
就是这样!虽然这是一个简单的设计版本,但它廉价、准确,适用于许多轻量级用例。我在行业原型中使用了这个设置,取得了巨大的成功。openai-cookbook存储库中的即插即用版本是一个方便的起点。
高级设计
我想花一点时间讨论一些可能进入检索增强生成架构的研究进展。我相信应用LLM产品将在6到9个月内实现其中的大多数功能。
生成-然后读取流程
这种方法涉及使用LLM处理用户输入,然后检索相关数据。
基本上,用户的问题的缺乏某些相关信息模式,这些信息模式将显示一个有意义的答案。例如,“Python中列表推导式的语法是什么?”与代码仓库中的示例(如“newlist = [x for x in tables if "customer" in x]”)有很大不同。一种建议的方法是使用“假想文档嵌入”(Hypothetical Document Embeddings)来生成一个假想的上下文文档,该文档可能包含虚假的细节,但模仿了一个真实的答案。将这个文档嵌入并在数据存储中搜索相关的(真实)例子可以检索到更相关的结果;使用这些相关结果生成实际的答案供用户查看。
类似地,名为“生成-然后读取”(GenRead)的另一种方法通过在多个上下文文档生成上实施聚类算法来建立实践基础。它有效地生成多个样本上下文,并确保它们以有意义的方式有所不同。这种方法使语言模型更倾向于返回更具多样性的假想上下文文档建议,这(在嵌入后)从数据存储中返回更多变的结果,并导致完成包括准确答案的机会更高。
改进的LLM索引和响应合成数据结构
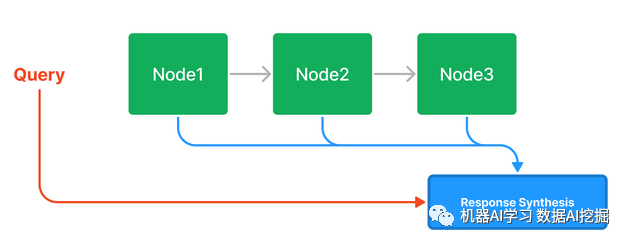
GPT Index项目非常出色,值得一读。它利用了一系列由语言模型创建和优化的数据结构。GPT Index支持多种类型的索引,下面有更详细的描述。基本的响应合成是“选择前k个相关文档并将它们附加到上下文中”,但有多种实现策略可供选择。
列表索引 - 每个节点表示一个文本块,否则未更改。在默认设置中,所有节点都组合到上下文中(响应合成步骤)。
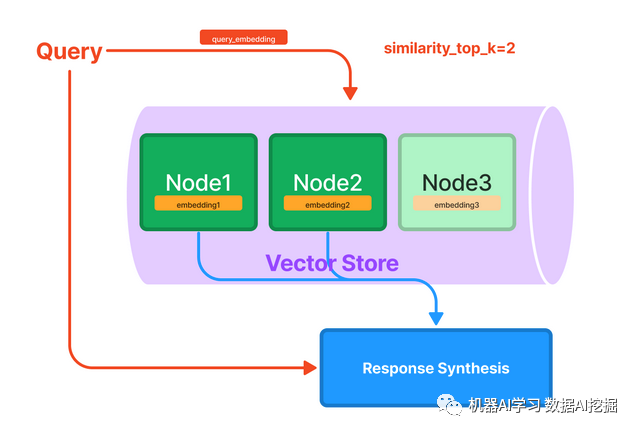
矢量存储索引 - 这相当于我在前一节中解释的简单设计。每个文本块都与一个嵌入一起存储;将查询嵌入与文档嵌入进行比较,返回k个最相似的文档以供输入到上下文中。
关键词索引 - 支持快速高效的特定字符串的词汇搜索。
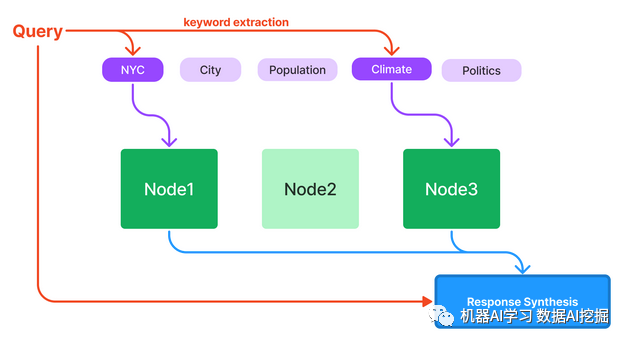
树索引 - 当您的数据组织成层次结构时,这非常有用。考虑一个临床文档应用程序:您可能希望文本包括高级指示("这里是改善心脏健康的一些一般方法"),以及低级文本(参考副作用和特定血压药物方案的说明)。有几种不同的遍历树的方式来生成响应,下面显示了两种方式。
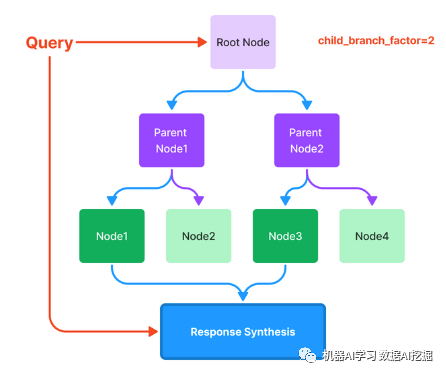
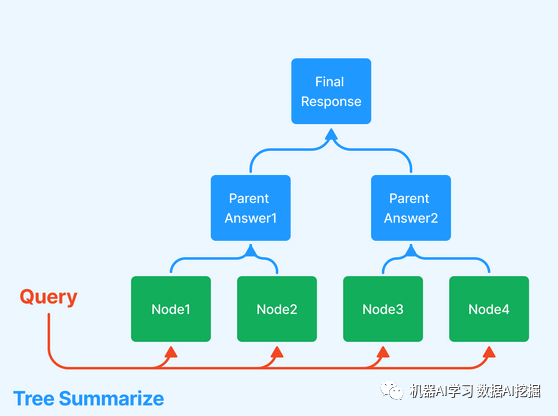
GPT Index提供索引的可组合性,这意味着您可以在其他索引之上构建索引。例如,在一个代码助手场景中,您可以在内部GitHub存储库上构建一个树索引,并在Wikipedia上构建另一个树索引。然后,您在树索引之上添加一个关键词索引。扩展上下文大小
本篇文章概述的一些方法听起来“hacky”,因为它们涉及到当前模型相对较小的上下文大小的解决方法。有大量的研究努力旨在扩大这一限制。
预计GPT-4将在接下来的1-3个月内推出。据传言,它具有更大的上下文大小。
来自Google AI团队的这篇论文包括许多工程权衡的探索。其中一个配置允许上下文长度高达43,000个标记。
一种新的状态空间模型架构以线性方式与上下文大小成比例增长,而不是像Transformer模型那样呈二次方增长。尽管该模型在其他方面的性能滞后,但它表明针对改善模型考虑因素(如上下文大小)的研究和开发正在取得进展。
在我看来,上下文大小的进步将随着对更多数据检索的需求而扩大;换句话说,可以安全地假设文本拆分和细化将继续需要,即使某些配置会演变。
持久化状态(例如对话历史记录)
当LLM呈现给用户时,主要挑战是保持对话历史记录在上下文中。
有关相关策略的概述超出了本文的范围;对于最近的一个涉及渐进式摘要和知识检索的代码演示示例,请参见此LangChain示例(https://github.com/langchain-ai/langchain/tree/master/libs/langchain)。