介绍
近些年来,深度学习技术已经彻底改变了计算机视觉领域。由于迁移学习和各种各样的学习资源的出现,任何人都可以通过使用预训练的模型,将其应用到自己的工作当中,以此获得非常好的结果。随着深度学习越来越商业化,希望它的创造性能应用在不同的领域上。
今天,计算机视觉领域中的深度学习在很大程度上解决了视觉对象的分类、目标检测和识别问题。在这些领域,深度神经网络(Deep Neural Network,DNN)的表现要胜过人类。
即使数据不是可视化的,但你仍然可以利用这些视觉深度学习模型的力量,主要是卷积神经网络(Convolutional Neural Network,CNN)。要做到这一点,你必须将数据从非视觉领域迁移到视觉领域(图像)里,然后使用一个经过在图像和数据上训练过的模型。你将会感叹这种方法是多么的强大。
在本文中,我将介绍3个案例,这是关于公司如何进行创造性地深度学习应用,将视觉深度学习模型应用于非视觉领域。在每一个案例中,都会对一个非计算机视觉的问题进行转换和描述,以便更好地利用适合图像分类的深度学习模型的能力。
案例1:石油工业
在石油工业中,游梁式抽油机(Beam pumps)常常用于从地下开采石油和天然气。它们由连接在移动梁上的发动机来提供动力。移动梁将发动机的旋转运动传递给抽油杆的垂直往复运动,抽油杆作为一个动力泵,再将油输送到地面上。

游梁式抽油机
游梁式抽油机作为一种复杂的机械系统,很容易发生故障。为了方便诊断排查,在抽油机上安装了一个测功机,用于测量杆上的负载。测量后,绘制出一张测功机的动力泵卡片,图上显示了发动机在旋转循环过程中每个部分的负载。
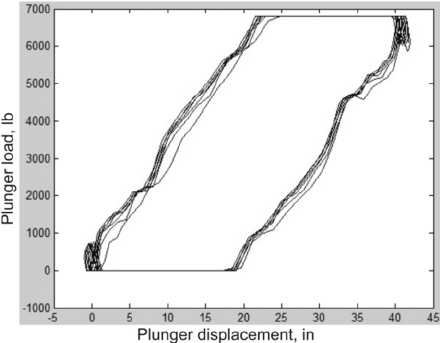
测功机卡片示例
当游梁式抽油机出故障的时候,测功机卡片上的形状会改变。这个时候,通常会邀请专业的技术人员过来检查卡片,并根据抽油机出现故障的部分来判断需要采取什么措施和方法来进行维修。这个过程不仅非常耗时,而且还需要非常深入的专业知识才能有效地解决问题。
另一方面,这个过程看起来有可能是可以自动化完成的,这就是为什么尝试过典型的机器学习系统而并没有取得很好效果的原因,准确率大约为60%。
将深度学习应用到这个领域的一个公司是Baker Hughes。在这种情况下,测功机卡片被转变为图像,然后作为输入到Imagenet的预训练模型中。这个结果非常令人印象深刻,精度从60%上升到93%,只需采用预训练的模型并用新的数据对其进行一下微调。经过模型训练的进一步优化,其精度达到了97%。
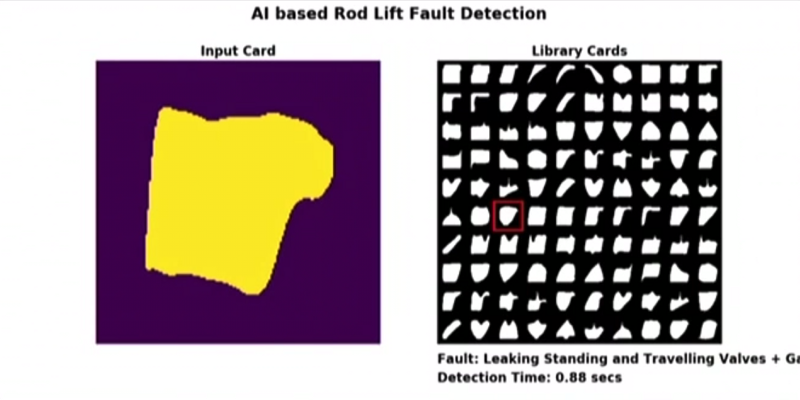
上图是Baker Hughes部署的系统示例。在左侧,你可以看到输入图像,在右侧是故障模式的实时分类。
它不仅击败了以前的基于机器学习的传统方法,而且公司不再需要抽油机的技术人员花费大量的时间来排查故障,他们过来就可以立即进行机械故障修复,从而大大提高了效率。
案例2:在线欺诈检测
计算机用户在使用计算机的时候有独特的模式和习惯。当你在浏览一个网站或在键盘上键入电子邮件内容的时候,你使用鼠标的习惯是独一无二的。
在这种特殊的情况下,Splunk解决了一个问题,即通过使用计算机鼠标的方式来对用户进行分类。如果你的系统能够根据鼠标使用的方式来识别用户,那么这种方法可以用于欺诈检测。假设这样一个情况:某些人在窃取了别人的用户名和登录密码之后在网上消费。他们使用电脑鼠标的方式是独一无二的,系统将很容易检测到这种异常操作,并进一步防止发生欺诈交易,同时也会通知真正的账户所有者。
使用特殊的Javascript代码,可以收集所有鼠标的行为活动。软件每5-10毫秒记录一次鼠标的行为。因此,每个用户在每个网页的行为数据可以是5000–10000个数据点。数据代表了两个挑战:第一个挑战是对于每个用户来说都是海量的数据,第二个挑战是每个用户的数据集都将包含不同多个数据点,这不太方便,因为,通常来说,不同长度的序列需要更复杂的深度学习架构。
这个方案是将每个用户在每个网页上的鼠标活动转换为一个单个图像。在每幅图像中,鼠标的移动是一条由不同的颜色来表示鼠标移动速度的线来表示的,而点击左键和点击右键则是由绿色和红色的圆圈来表示的。这种处理初始数据的方法解决了上述的两个问题:首先,所有图像的大小都相同;其次,现在基于图像的深度学习模型可以用于此类数据了。

在每幅图像中,鼠标的移动是一条由不同的颜色来表示鼠标移动速度的线来表示的,而点击左键和点击右键则是由绿色和红色的圆圈来表示的
Splunk使用TensorFlow和Keras为用户分类创建了一个深度学习的系统。他们做了2个实验:
1. 当访问相类似的页面时,金融服务网站的用户组分类:正常客户与非客户用户。一个由2000张图片组成的相对较小的训练数据集。在对基于VGG16网络的一个已修改结构进行了2分钟的训练之后,系统能够以80%以上的准确度识别出这两个类;
2. 用户的个人分类。该任务是为一个给定的用户预测出是真实用户还是一个模拟者。提供了一个只有360张图片的非常小的训练数据集。基于VGG16网络,但是由于考虑到小数据集和减少过度拟合(有可能放弃和批量标准化)而进行了修改。经过了3分钟的训练,准确率达到了78%左右,考虑到任务具有的挑战性,那么这一点很令人印象深刻;
要了解更多相关内容,请参阅描述了系统和实验过程的完整内容。
案例3:鲸鱼的声音检测
在这个例子中,谷歌使用卷积神经网络来分析录音并检测出其中的座头鲸。这对于科学研究来说很有帮助,例如跟踪单个鲸鱼的活动、叫声的特性、鲸鱼的数量等等。有趣不是目的,而是如何通过需要利用图像的卷积神经网络来处理数据。
将音频数据转换成图像的方法是通过使用光谱图来实现的。光谱图是音频数据基于频率特征的视觉来表示的。
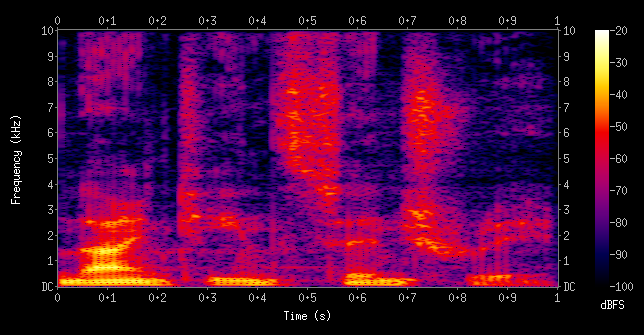
一个男性说“十九世纪” 的声音光谱图例子
在将音频数据转换成光谱图之后,谷歌的研究人员使用了ResNet-50网络结构来训练这个模型。他们能够达到以下的性能表现:
·90%的准确度:90%的音频剪辑被归类为鲸鱼叫声的分类;
·90%的敏感度:如果给一个鲸鱼叫声的录音,那么就会有90%的机会被打上敏感度的标签;
让我们把焦点从鲸鱼叫声转移到处理音频数据时可以做些什么。当你创建光谱图的时候,可以选择要使用的频率,这取决于你所拥有的音频数据的类型。你将需要给人类的说话声、座头鲸的叫声、或工业设备的录音设置不同的频率,因为在所有的这些情况下,最重要的信息是包含在了不同的频段里。你不得不使用自己的专业领域知识来选择相关的参数。例如,如果你使用的是人类声音数据,那么你的第一选择应该是梅尔频率倒谱图。
目前有一些有比较好的软件包可用于音频。Librosa是一个免费的音频分析Python库,可以使用CPU生成光谱图。如果你在TensorFlow中开发并且想在GPU上做光谱计算,那也是支持的。
请参考一下这篇文章,了解更多的关于谷歌如何处理座头鲸数据的内容。
综上所述,本文所阐述的一般方法都遵循了两个步骤。首先,找到一种将数据转换成图像的方法;其次,使用一个经过预训练的卷积网络或者从头开始进行训练。第一步要比第二步更难,这是需要你必须有创造力的地方,要考虑到如果你的数据可以转换成图像。我希望提供的实例对解决你的问题有所帮助。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Deep Learning Vision for Non-Vision Tasks》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文