
让我们先描述我们的购物问题:在用户图像中识别时尚商品并在网上商店中找到它。您是否曾经在街上看到某人,并想过:“哇,这是一件漂亮的衣服,我想知道在哪里可以买到它?”对我而言,尝试距离度量学习技术是一项很酷的任务。我希望您也会发现它有趣。
数据集
首先,我们需要一个数据集。实际上,当我发现Aliexpress上的用户拍摄了大量图像后,便想到了这个想法。我想“哇,我当然可以用这些数据来按图像搜索”。为了简单起见,我决定专注于女士上装。
以下是我使用的类别列表:
- 洋装
- 衬衫和衬衣
- 帽衫和针织衫
- 毛衣
- 外套和大衣
我使用python的requests包和BeautifulSoup包进行了收集数据。卖家图像可以从商品的主页获取,但是对于用户的图像,我们需要浏览反馈页面。商品页面上有一个叫做“颜色”的东西。颜色可以只是商品相同样式的不同颜色,甚至可以完全是其他商品。因此,我们将不同的颜色视为不同的商品。

您可以通过以下链接找到我用来获取关于一个商品的所有信息的代码(它甚至比我们的任务所需的还要多)
https://github.com/movchan74/streettoshopexperiments/blob/master/getitem_info.py
我们所需要的是通过每个类别的搜索页面,获取所有商品的url,并使用上面的函数来获取每个商品的信息。
最后,我们将为每个商品提供两组图像:来自销售者的图像(每个元素item['colors']的字段url)和来自用户的图像(每个元素item['feedbacks']的字段imgs)。
对于每种颜色,我们只有一个来自卖方的图像,但是对于每种颜色,我们可以有多个来自用户的图像(有时根本没有用于颜色的图像)。
太棒了!我们得到了数据。但是,收集到的数据集是有噪声的:
- 有来自用户的噪声图像(包装盒的照片,纹理的照片或只是一个商品的一部分,未包装的商品,不相关的照片)。



为了解决这个问题,我把5000张图片分成两类:好图片和噪声图片。一开始,我的计划是训练两个类别的分类器并使用它来清理数据集。但是后来我决定把这个想法留到以后的工作中,只是把清理过的图像添加到测试和验证集中。
- 第二个问题是有些商品是由几个卖家出售的。卖家有时甚至会有相同的图片(或稍微编辑过的图片)。但是如何处理呢?最简单的方法是什么也不做,使用一个健壮的算法来学习距离度量。但是它会影响验证,因为我们可以在验证和训练数据中有相同的商品。这就导致了不正确。另一种方法是使用一些东西来寻找相似(甚至相同的图像)并将它们合并到一个商品中。我们可以使用感知哈希来寻找相同的图像(如phash或whash),或者我们可以在有噪声的数据上训练一个模型,并应用该模型来寻找相似的图像。我选择了第二个选项,因为它允许合并稍微编辑过的图像。
距离度量学习
最流行的距离度量学习方法之一是三元组损失:

其中max(x,0)是铰链函数,d(x,y)是x与y之间的距离函数,F(x)是深层神经网络,M是间隔,a是锚点,p是正样本,n是负样本。
F(a),F(p),F(n)是由深层神经网络产生的高维空间(嵌入)中的点。值得一提的是,通常需要将embedding标准化为具有单位长度,即 ||x|| = 1,以便对照明和对比度变化具有鲁棒性,并具有训练稳定性。锚和正样本属于同一个类,负样本是另一个类的样本。
但如何选择(a, p, n)呢?我们可以随机选择样本作为三元组,但这会导致以下问题。首先,可能有N³三元组。这意味着我们需要很多时间来研究所有可能的三元组。但实际上,我们不需要这样做,因为经过几次反复的训练后,会有许多三元组不违反三元组约束(零损失)。这意味着这些三元组对于训练来说是无用的。
三元组选择的最常见方式之一是难负样本挖掘(hard negative mining):
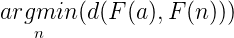
在实践中,选择最困难的负样本会在训练的早期导致糟糕的局部最小值。具体来说,它可以导致一个崩溃的模型(即F(x) = 0)。
半难负样本(Semi-hard negative samples)比阳性样本离锚点更远,但它们仍然是难的(违反约束),因为它们位于间隔M之内。

有两种方法可以生成半难(和难)负样本:在线和离线。
- 在线意味着我们从训练数据集中随机选择一个大batch,并从其中的样本中选择三元组。然而,我们需要一个大的batch。这在我的情况下是不可能的,因为我只有一个带有8Gb RAM的GTX 1070。
- 在离线方法中,我们需要在一段时间后停止训练,预测一定数量样本的嵌入,选择三个一组,用这些三个一组训练模型。这意味着我们需要向前传递两次,但这是离线方法的代价。
好!我们已经可以用triple损失和离线半难负样本挖掘来训练模型。但是,我们还需要一个技巧来成功地解决我们原本的问题。我们的任务是找到最接近用户形象的卖家形象。然而,通常卖方的图像比用户的图像有更好的质量(在照明,相机,位置),所以我们有两个域:卖方的图像和用户的图像。为了得到有效的模型,我们需要缩小这两个域之间的差距。这个问题称为域适应。


上:用户的图像,下:卖方的图像
我提出了一种非常简单的技术来缩小域差距:让我们从卖方的图像中选择锚点,从用户的图像中选择正样本和负样本。就这样!简单而有效。
实现
为了实现我的想法和做实验我已经使用Tensorflow后端的Keras库。
我选择了Inception V3模型作为模型的基础CNN。和往常一样,我使用ImageNet权重初始化了CNN。在网络末端使用L2标准化进行全局池化之后,我添加了两个完全连接的层。嵌入的大小为128。
def get_model():
no_top_model = InceptionV3(include_top=False, weights='imagenet', pooling='avg')
x = no_top_model.output
x = Dense(512, activation='elu', name='fc1')(x)
x = Dense(128, name='fc2')(x)
x = Lambda(lambda x: K.l2_normalize(x, axis=1), name='l2_norm')(x)
return Model(no_top_model.inputs, x)我们还需要实现triple损失功能。我们将锚点,正/负样本作为单个小批量传递,并将其分为损失函数内的3个张量。距离函数是欧几里德距离的平方。
def margin_triplet_loss(y_true, y_pred, margin, batch_size):
out_a = tf.gather(y_pred, tf.range(0, batch_size, 3))
out_p = tf.gather(y_pred, tf.range(1, batch_size, 3))
out_n = tf.gather(y_pred, tf.range(2, batch_size, 3))
loss = K.maximum(margin
K.sum(K.square(out_a-out_p), axis=1)
- K.sum(K.square(out_a-out_n), axis=1),
0.0)
return K.mean(loss)编译模型:
from functools import partial, update_wrapper
def wrapped_partial(func, *args, **kwargs):
partial_func = partial(func, *args, **kwargs)
update_wrapper(partial_func, func)
return partial_func
opt = keras.optimizers.Adam(lr=0.0001)
model.compile(loss=wrapped_partial(margin_triplet_loss, margin=margin, batch_size=batch_size), optimizer=opt)实验结果

绩效以召回率K(R@K)进行衡量。让我们看一下如何计算R@K。每个用户的图像验证集作为一个查询,我们需要找到相应的卖家的图像。我们取一个查询图像,计算嵌入向量,并在所有卖方图像的向量中搜索该向量的最近邻居。我们不仅使用来自验证集的卖方图像,还使用来自训练集的图像,因为它允许增加干扰物,使我们的任务更具挑战性。
我们有一个查询图像和一个最相似的卖家图像列表。如果在K个最相似的图像中有对应的销售者图像,那么我们为这个查询返回1,否则返回0。现在,我们需要为验证集中的每个用户的图像创建它,并从每个查询中找到平均得分为R@K。
正如我之前所说的,我已经从有噪声的图像中清除了少量的用户图像。因此,我在两个验证数据集上测量了模型的性能,分别是完整的验证集和只有干净图像的子集。

结果远非理想,有很多事情要做:
- 清除用户图像中的噪声。我已经在这个方向上迈出了第一步,清理了一小部分。
- 更准确地合并项目(至少在验证集中)。
- 减少域差距。我认为可以通过特定领域的增强(例如灯光增强)和使用专门的方法(比如https://arxiv.org/abs/1409.7495)来实现。
- 应用另一种距离度量学习技术。我试过这个https://arxiv.org/abs/1703.07464,但在我的情况下效果更差。
- 收集更多的数据。
Demo,代码和训练好的模型
我已经对该模型进行了演示。您可以在这里查看:http://vps389544.ovh.net:5555/
您可以上传自己的图片进行搜索,也可以使用验证集中的随机图片。
代码和训练好的模型:http://vps389544.ovh.net:5555/.
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/
OpenCV中文官方文档:http://woshicver.com/
