一、前述
上节我们讲解了xgboost的基本知识,本节我们通过实例进一步讲解。
二、具体
1、安装
默认可以通过pip安装,若是安装不上可以通过https://www.lfd.uci.edu/~gohlke/pythonlibs/网站下载相关安装包,将安装包拷贝到Anacoda3的安装目录的Scrripts目录下, 然后pip install 安装包安装。

2、代码实例
import xgboost
# First XGBoost model for Pima Indians dataset from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load data dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # split data into X and y X = dataset[:,0:8] Y = dataset[:,8] # split data into train and test sets seed = 7 test_size = 0.33 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # fit model no training data model = XGBClassifier() model.fit(X_train, y_train) # make predictions for test data y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # evaluate predictions accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0))
或者每次插入一颗树,看看效果
from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load data dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # split data into X and y X = dataset[:,0:8] Y = dataset[:,8] # split data into train and test sets seed = 7 test_size = 0.33 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # fit model no training data model = XGBClassifier() eval_set = [(X_test, y_test)] model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True) # make predictions for test data y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # evaluate predictions accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0))
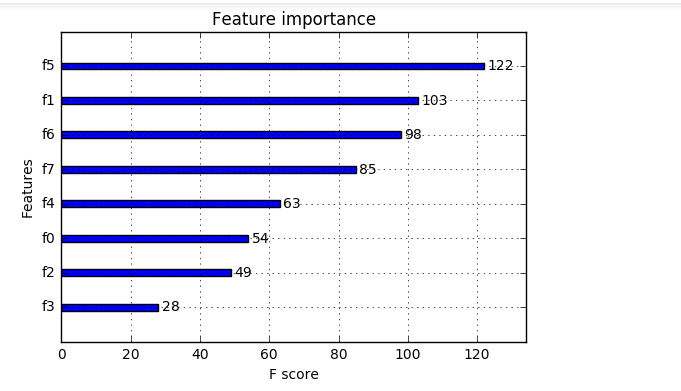
观看特征的重要程度:
from numpy import loadtxt from xgboost import XGBClassifier from xgboost import plot_importance from matplotlib import pyplot # load data dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # split data into X and y X = dataset[:,0:8] y = dataset[:,8] # fit model no training data model = XGBClassifier() model.fit(X, y) # plot feature importance plot_importance(model) pyplot.show()
xgboost参数:
- 'booster':'gbtree',
- 'objective': 'multi:softmax', 多分类的问题
- 'num_class':10, 类别数,与 multisoftmax 并用
- 'gamma':损失下降多少才进行分裂
- 'max_depth':12, 构建树的深度,越大越容易过拟合
- 'lambda':2, 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- 'subsample':0.7, 随机采样训练样本
- 'colsample_bytree':0.7, 生成树时进行的列采样
- 'min_child_weight':3, 孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束
- 'silent':0 ,设置成1则没有运行信息输出,最好是设置为0.
- 'eta': 0.007, 如同学习率
- 'seed':1000,
- 'nthread':7, cpu 线程数
xgb1 = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27)
交叉验证:
# Tune learning_rate from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold # load data dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # split data into X and y X = dataset[:,0:8] Y = dataset[:,8] # grid search model = XGBClassifier() learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3] param_grid = dict(learning_rate=learning_rate) kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold) grid_result = grid_search.fit(X, Y) # summarize results print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) means = grid_result.cv_results_['mean_test_score'] params = grid_result.cv_results_['params'] for mean, param in zip(means, params): print("%f with: %r" % (mean, param))