1. 常规卷积原理
3*3卷积核以滑动窗口方式在输入特征图上滑动,每一次滑动,都将卷积核权重与输入特征图对于位置进行乘加操作,得到输出特征图。
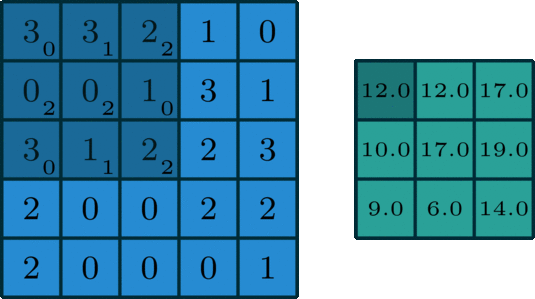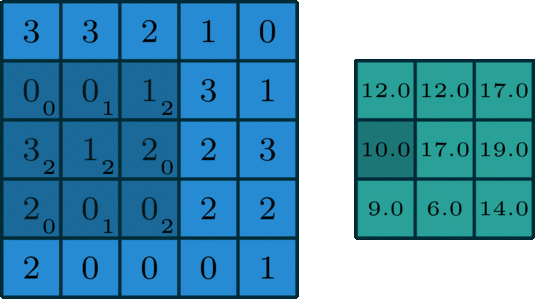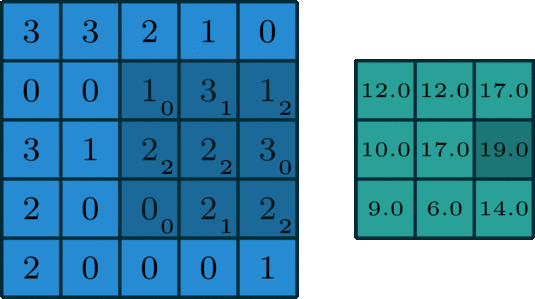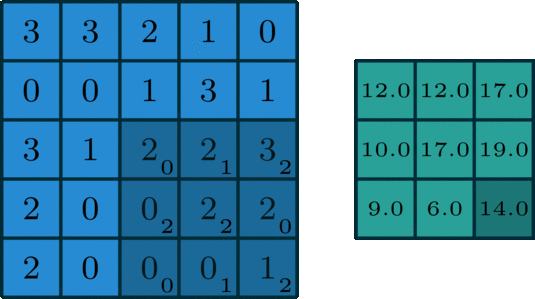
下图为示例:
输入特征图尺寸为5*5,通道为3;
卷积核尺寸为3*3*3,一共有2个卷积核;
其中,padding=1,stride=2。
首先将Input Volumn尺寸由5*5padding到7*7,卷积核Filter W0(3*3*3)如下图所示,将
3通道的卷积与3通道的输入进行stride=2的滑动窗口进行对应元素乘积相加操作,再加上偏置Bias b0,得到Output Volumn[:,:,0]上的每个元素,同理,最终生成Output Volumn。
input feature map:
filter:
output feature map:
2. pytorch官方卷积解读
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')其中:
in_channels参数代表输入特征矩阵的深度即channel,比如输入一张RGB彩色图像,那in_channels=3;
out_channels参数代表卷积核的个数,使用n个卷积核输出的特征矩阵深度即channel就是n;
kernel_size参数代表卷积核的尺寸,输入可以是int类型如3 代表卷积核的height=width=3,也可以是tuple类型如(3, 5)代表卷积核的height=3,width=5;
stride参数代表卷积核的步距默认为1,和kernel_size一样输入可以是int类型,也可以是tuple类型;
padding参数代表在输入特征矩阵四周补零的情况默认为0,同样输入可以为int型如1 代表上下方向各补一行,左右方向各补一列,如果输入为tuple型如(2, 1) 代表在上下方向补两行,左右方向补一列。padding[0]是在H高度方向两侧填充的,padding[1]是在W宽度方向两侧填充的;
bias参数表示是否使用偏置(默认True);
dilation(int or tuple) – 卷积核元素之间的间距;可参考空洞卷积;
groups(int) – 从输入通道到输出通道的阻塞连接数,可参考分组卷积,一般不用;
3.代码实现(循环)
3.1 代码
import torch
import torch.nn.functional as F
import torch.nn as nn
import time
def myconv2d(inputs, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, weights=None, bias=True):
if weights is None:
weights = torch.randn([out_channels, in_channels, kernel_size[0], kernel_size[1]])
if bias is None:
bias = torch.zeros(out_channels)
# padding
def _fixed_padding(inputs, kernel_size):
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
padded_inputs = F.pad(inputs, [pad_beg, pad_end, pad_beg, pad_end], mode='constant',value=0)
return padded_inputs
if padding:
padded_inputs = F.pad(inputs, [padding, padding, padding, padding], mode='constant',value=0)
else:
padded_inputs = _fixed_padding(inputs, kernel_size)
# conv
n,c,w,h = padded_inputs.shape
outputs = []
# 循环遍历batch
for i, imgs in enumerate(padded_inputs):
one_batch_out = []
# 循环遍历output_channels(feature map)
for j in range(out_channels):
feature_map = []
# 循环遍历imgs
row = 0
while row + kernel_size[0] <= h:
row_feature_map = []
col = 0
while col + kernel_size[1] <= w:
point = [0 for ch in range(c)]
for ch in range(c): # 通道
for y in range(kernel_size[0]):
for x in range(kernel_size[1]):
point[ch] += imgs[ch][row+y][col+x] * weights[j][ch][y][x]
point = sum(point) + bias[j]
row_feature_map.append(point)
col += stride[1] if isinstance(stride, (list,tuple)) else stride
feature_map.append(row_feature_map)
row += stride[0] if isinstance(stride, (list,tuple)) else stride
one_batch_out.append(feature_map)
outputs.append(one_batch_out)
return torch.Tensor(outputs)
3.2 测试
if __name__ == "__main__":
# 测试参数
image_w, image_h = 12,12
in_channels = 3
out_channels = 5
kernel_size = (3, 3)
stride = (1,1)
padding = 1
# 输入图片与网络权重
image = torch.rand(4, in_channels, image_w, image_h)
weights = torch.rand(out_channels, in_channels, kernel_size[0], kernel_size[1])
bias = torch.ones(out_channels)
# pytorch运算结果
net = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=True)
net.weight = nn.Parameter(weights)
net.bias = nn.Parameter(bias)
net.eval()
t1 = time.time()
output1 = net(image)
t2 = time.time()
print('pytorch卷积运算耗时:', (t2-t1))
print(output1.shape)
# 自己实现的结果
t3 = time.time()
output = myconv2d(image, in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, weights=weights, bias=bias)
t4 = time.time()
print('自己实现的卷积运算耗时:', (t4-t3))
print(output.shape)
eps = (output - output1).abs().max()
print('误差:',eps) 3.3 结果:
pytorch卷积运算耗时: 0.015956878662109375
torch.Size([4, 5, 12, 12])
自己实现的卷积运算耗时: 1.6175706386566162
torch.Size([4, 5, 12, 12])
误差: tensor(2.8610e-06, grad_fn=<MaxBackward1>)耗时太长,未考虑dilation, groups参数在卷积中的使用,使用循环遍历时间复杂度太高。
4. 代码实现(使用unfold与fold)
4.1 unfold()与fold()原理解读
推荐一个博主的文章,写的很清楚:
「详解」torch.nn.Fold和torch.nn.Unfold操作
官网地址:链接
4.2 代码
import math
import torch
import torch.nn as nn
import time
def myconv2d(inputs, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, weights=None, bias=True) -> torch.Tensor:
assert len(inputs.shape) == 4,'Currently, only 4-D input tensors (batched image-like tensors) are supported.'
kernel_size = kernel_size if isinstance(kernel_size, (tuple,list)) else (kernel_size,kernel_size)
stride = stride if isinstance(stride, (tuple,list)) else (stride,stride)
padding = padding if isinstance(padding, (tuple,list)) else (padding,padding)
dilation = dilation if isinstance(dilation, (tuple,list)) else (dilation,dilation)
if weights is None:
weights = torch.randn([out_channels, in_channels, kernel_size[0], kernel_size[1]])
if bias is None:
bias = torch.zeros(out_channels)
x = torch.nn.functional.unfold(input=inputs, kernel_size=kernel_size, dilation=dilation, padding=padding, stride=stride)
y = x.transpose(1, 2).matmul(weights.view(weights.size(0), -1).t()).transpose(1, 2) # 乘加
output_size0 = math.floor((inputs.shape[-2] + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
output_size1 = math.floor((inputs.shape[-1] + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
out = torch.nn.functional.fold(y, output_size=(output_size0, output_size1), kernel_size=(1,1))
out = out + bias.reshape(-1,1,1)
return out
if __name__ == "__main__":
# 测试参数
image_w, image_h = 512,512
in_channels = 3
out_channels = 64
kernel_size = (3, 3)
stride = 2
padding = 1
# 输入图片与网络权重
image = torch.rand(4, in_channels, image_w, image_h)
weights = torch.rand(out_channels, in_channels, kernel_size[0], kernel_size[1])
bias = torch.ones(out_channels)
# pytorch运算结果
net = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=True)
net.weight = nn.Parameter(weights)
net.bias = nn.Parameter(bias)
net.eval()
t1 = time.time()
output1 = net(image)
t2 = time.time()
print('pytorch卷积运算耗时:', (t2-t1))
print(output1.shape)
print('-' * 64)
# 自己实现的结果
t3 = time.time()
output = myconv2d(image, in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, weights=weights, bias=bias)
t4 = time.time()
print('自己实现的卷积运算耗时:', (t4-t3))
print(output.shape)
print('-' * 64)
eps = (output - output1).abs().max()
print('误差:',eps)
4.3 结果:
pytorch卷积运算耗时: 0.03859138488769531
torch.Size([4, 64, 256, 256])
----------------------------------------------------------------
自己实现的卷积运算耗时: 0.17059946060180664
torch.Size([4, 64, 256, 256])
----------------------------------------------------------------
误差: tensor(4.7684e-06, grad_fn=<MaxBackward1>)依旧存在耗时较多的问题,未考虑groups参数在卷积中的实现,但相比于循环遍历时间大大减少。
仅为学习记录!