卷积层是所有深度卷积网络的基础。我们来讲讲padding方法和它会遇到的问题。
卷积层的各个参数的官方解释是这样的:
Arguments:
inputs: Tensor input.
filters: Integer, the dimensionality of the output space (i.e. the number of filters in the convolution).
kernel_size: An integer or tuple/list of 2 integers, specifying the height and width of the 2D convolution window. Can be a single integer to specify the same value for all spatial dimensions.
strides: An integer or tuple/list of 2 integers, specifying the strides of the convolution along the height and width. Can be a single integer to specify the same value for all spatial dimensions. Specifying any stride value != 1 is incompatible with specifying any dilation_rate value != 1.
padding: One of "valid" or "same" (case-insensitive).#我们要讲的
data_format: A string, one of channels_last (default) or channels_first. The ordering of the dimensions in the inputs. channels_last corresponds to inputs with shape (batch, height, width, channels) while channels_first corresponds to inputs with shape (batch, channels, height, width).
dilation_rate: An integer or tuple/list of 2 integers, specifying the dilation rate to use for dilated convolution. Can be a single integer to specify the same value for all spatial dimensions. Currently, specifying any dilation_rate value != 1 is incompatible with specifying any stride value != 1.
activation: Activation function. Set it to None to maintain a linear activation.
use_bias: Boolean, whether the layer uses a bias.
kernel_initializer: An initializer for the convolution kernel.
bias_initializer: An initializer for the bias vector. If None, the default initializer will be used.
kernel_regularizer: Optional regularizer for the convolution kernel.
bias_regularizer: Optional regularizer for the bias vector.
activity_regularizer: Optional regularizer function for the output.
kernel_constraint: Optional projection function to be applied to the kernel after being updated by an Optimizer (e.g. used to implement norm constraints or value constraints for layer weights). The function must take as input the unprojected variable and must return the projected variable (which must have the same shape). Constraints are not safe to use when doing asynchronous distributed training.
bias_constraint: Optional projection function to be applied to the bias after being updated by an Optimizer.
trainable: Boolean, if True also add variables to the graph collection GraphKeys.TRAINABLE_VARIABLES (see tf.Variable).
name: A string, the name of the layer.
reuse: Boolean, whether to reuse the weights of a previous layer by the same name.
Returns:
Output tensor.卷积层的作用不多赘述。我们讲讲上面介绍最少的padding参数。
padding的作用
padding参数一共有两个值:
1.same代表卷积时如果原始数据边缘不足的卷积核大小的,就自动填0补齐。
2.valid代表卷积时如果原始数据边缘不足的卷积核大小的,相应缩小输出图像大小。
简单的说,一个
的图像,用核大小
的卷积核步长为1卷积时,”same”会输出
的图像,而”valid“会输出
大小的图像。StackOverflow的解释。
一般用法
在卷积网络里,为了对齐到输出大小,会采用‘same’进行卷积,这样卷积完的结果长度比较工整。而像resnet这种多次使用
卷积核的网络,则必须使用‘same’方式进行卷积,不然因为对齐的关系,输出的图像会越来越小。
我们来看一个例子:
def test():
os.environ["CUDA_VISIBLE_DEVICES"] = '-1'
src = tf.random_uniform((1, 6, 6, 1), 0, 5, tf.int32, seed=0)
src = tf.cast(src, tf.float32)
kernal = tf.random_uniform((3, 3, 1, 1), -1, 2, tf.int32, seed=0)
kernal = tf.cast(kernal, tf.float32)
conv1 = tf.nn.conv2d(src, kernal, [1, 1, 1, 1], padding='SAME')
conv2 = tf.nn.conv2d(src, kernal, [1, 1, 1, 1], padding='VALID')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
src, k, v1, v2 = sess.run([src, kernal, conv1, conv2])此时我们输出各个值看一下:
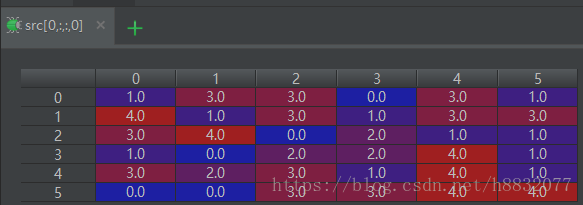
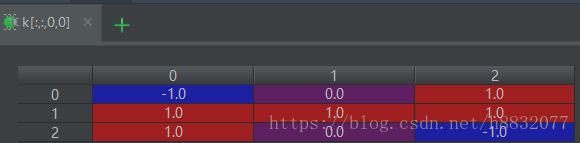
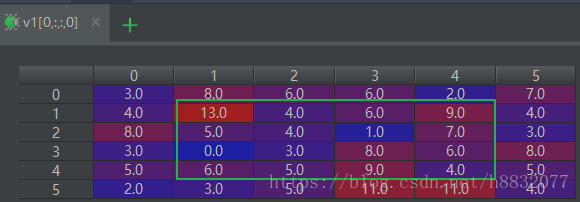
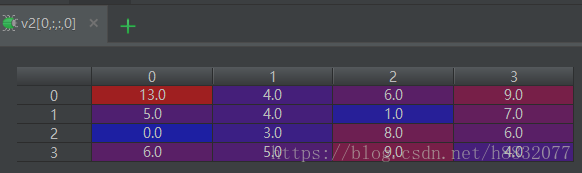
上图可以看到,对
大小的图像卷积,使用‘valid’的输出数组刚好是’same’的中间部分(绿框所示,最后两张图)。这里没有用偏置,所以
。
偶数时的Padding区别
到目前为止,我们没有发现任何‘same’方法的问题。为什么resnet等网络需要使用的conv2d方法呢?两者有什么区别?我们把步长stride设置为2看一下。
def conv2d_same(inputs, kernel, stride,rate=1):
if stride == 1:
return tf.nn.conv2d(inputs, kernel, [1, stride, stride, 1], padding='SAME')
else:
kernel_size_effective = kernel + (kernel - 1) * (rate - 1)
pad_total = kernel_size_effective - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs,
[[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return tf.nn.conv2d(inputs, kernel, [1, stride, stride, 1], padding='VALID')
def test():
os.environ["CUDA_VISIBLE_DEVICES"] = '-1'
src = tf.random_uniform((1, 8, 8, 1), 0, 5, tf.int32, seed=0)
src = tf.cast(src, tf.float32)
# src = src[:, 1:, :, :]
# src = tf.pad(src, [[0, 0], [0, 1], [0, 0], [0, 0]], constant_values=1)
kernal = tf.random_uniform((3, 3, 1, 1), -1, 2, tf.int32, seed=0)
kernal = tf.cast(kernal, tf.float32)
conv1 = conv2d_same(src, kernal, 2)
conv2 = tf.nn.conv2d(src, kernal, [1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.conv2d(src, kernal, [1, 2, 2, 1], padding='VALID')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
src, k, v1, v2,v3 = sess.run([src, kernal, conv1, conv2,conv3])输出结果如下:
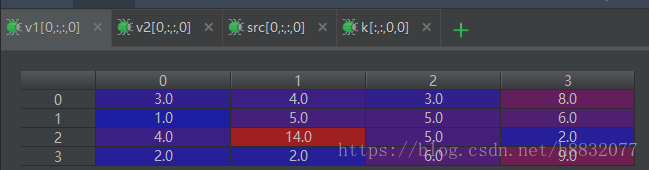
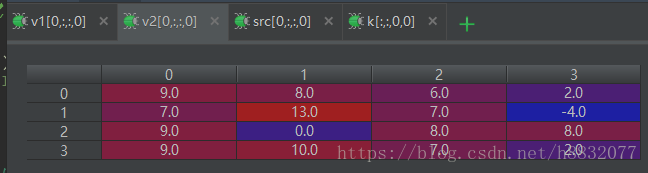
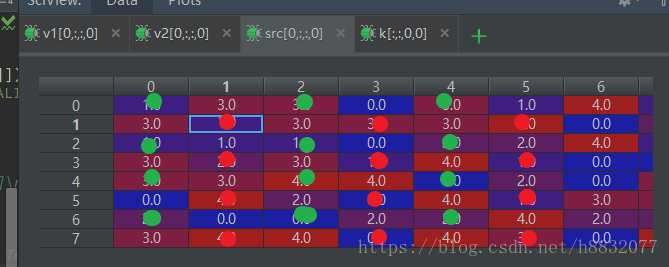
可以看到,在原始图像为偶数时,默认从第一个位置开始向外卷积(上图绿点),而普通的卷积方法,默认从第二个开始取值(上图红点)。而’valid’方法的卷积结果 如下:

和默认方法的起始位置一致。
结尾
从上面的结果可以看到,’valid’方法得到的结果就是’same’方法缩小一个卷积核的半径,两者保持一致。conv_same方法在stride=1时,和普通方法没有任何区别,stride!=1时,起点位置和默认方法不一样(可以通过rate参数控制)。一般情况下,推荐使用‘same’方法。
最后,祝您身体健康再见!