tf.nn.conv2d函数 ,在tf技术解释与实践中解释的很清楚。尤其是参数。现在还是来总结一下。
tf.nn.conv2d是TensorFlow里面实现卷积的函数,参考文档对它的介绍并不是很详细,实际上这是搭建卷积神经网络比较核心的一个方法,非常重要
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一。假如不是第一个tensor,它代表的其实是从不同featuremap中取数据。
注意一个2通道的图像其实应该表示为:
[[[[1, 11],[2, 22],[3, 33]],
[[4, 44],[5, 55],[6, 66]],
[[7, 77],[8, 88],[9, 99]]]]
1,11是同一个点的两个通道。书中翻译为输入维度,其实是一个意思。
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数in_channels
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式(后面会介绍)
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map,shape仍然是[batch, height, width, channels]这种形式。
那么TensorFlow的卷积具体是怎样实现的呢,用一些例子去解释它:
1.考虑一种最简单的情况,现在有一张3×3单通道的图像(对应的shape:[1,3,3,1]),用一个1×1的卷积核(对应的shape:[1,1,1,1]
问题1 输入X的维度和参数W的输入维度需要一致吗?当然
2 W 一共有几个参数?几个featuremap?
一共是filter_height*filter_width*in_channels*out_channels那么多的参数
featuremap 个数为 out_channels个 ,表示有几个卷积。
3 in_channels是如何处理的?
其实是会把同一个点上几个通道的值相加
举例来说
import input_data
import tensorflow as tf
import numpy as np
x= np.array([1.0,2.0,3.0,1.,1.0,2.0,3.0,1.],dtype='float32')
x= np.array([2.0,2.0,3.0,3.,2.0,2.0,3.0,3.,],dtype='float32')
f=np.array([1.,2.,3.,2.,1.,2.,3.,2.],dtype='float32')
print (x.dtype)
input = tf.reshape(x,[-1,2,2,2])
filter = tf.reshape(f,[2,2,2,1])
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print("filter")
print("result")
result = sess.run(op)
print(result) X=[
[2,2],[3,3]
[2,2],[3,3]
]
W=[
[1,2],[3,2]
[1,2],[3,2]
]
conv2d(X,W)=[42,18],[21,9]
(2*1+3*3+2*1+3*3=22 ) + (2*2+2*3+2*2+2*3)=42。
其他维度不再赘述
为了更直观的理解,下面举个例子,图片使用自 吴恩达老师的深度学习课程 。
如下图,假设现有一个为 6×6×36×6×3 的图片样本,使用 3×3×33×3×3 的卷积核(filter)进行卷积操作。此时输入图片的 channels 为 33 ,而卷积核中的 in_channels 与 需要进行卷积操作的数据的 channels 一致(这里就是图片样本,为3)。
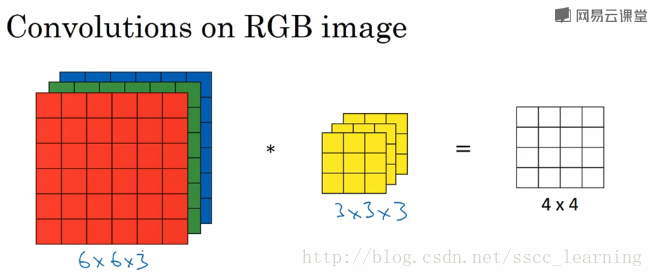
接下来,进行卷积操作,卷积核中的27个数字与分别与样本对应相乘后,再进行求和,得到第一个结果。依次进行,最终得到 4×44×4 的结果。
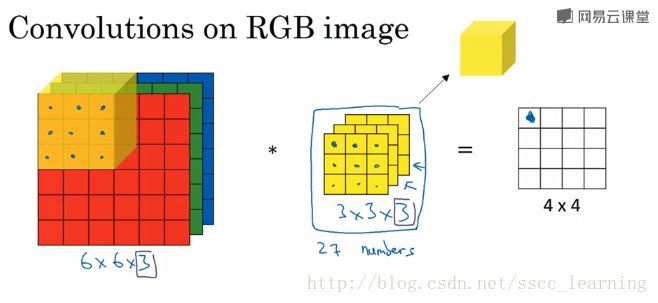
上面步骤完成后,由于只有一个卷积核,所以最终得到的结果为 4×4×14×4×1 , out_channels 为 11 。
在实际应用中,都会使用多个卷积核。这里如果再加一个卷积核,就会得到 4×4×24×4×2 的结果。
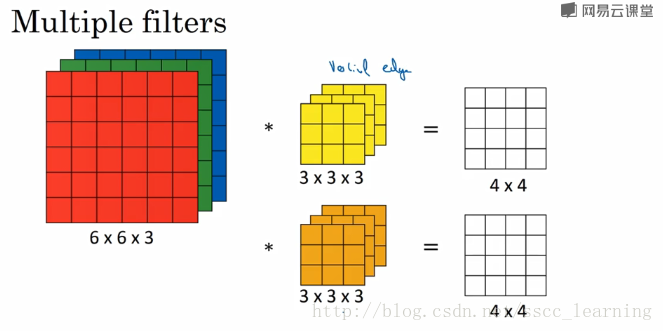
总结一下,我偏好把上面提到的 channels 分为三种:
- 最初输入的图片样本的
channels,取决于图片类型,比如RGB; - 卷积操作完成后输出的
out_channels,取决于卷积核的数量。此时的out_channels也会作为下一次卷积时的卷积核的in_channels; - 卷积核中的
in_channels,刚刚2中已经说了,就是上一次卷积的out_channels,如果是第一次做卷积,就是1中样本图片的channels。
说到这里,相信已经把 channels 讲的很清楚了。在CNN中,想搞清楚每一层的传递关系,主要就是 height,width 的变化情况,和 channels 的变化情况。
【TensorFlow】tf.nn.max_pool实现池化操作
2016年12月04日 14:28:39
阅读数:36944
max pooling是CNN当中的最大值池化操作,其实用法和卷积很类似
有些地方可以从卷积去参考【TensorFlow】tf.nn.conv2d是怎样实现卷积的?
tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数是四个,和卷积很类似:
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取'VALID' 或者'SAME'
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
示例源码:
假设有这样一张图,双通道
第一个通道:
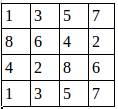
第二个通道:
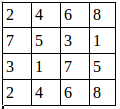
用程序去做最大值池化:
-
import tensorflow as tf -
a=tf.constant([ -
[[1.0,2.0,3.0,4.0], -
[5.0,6.0,7.0,8.0], -
[8.0,7.0,6.0,5.0], -
[4.0,3.0,2.0,1.0]], -
[[4.0,3.0,2.0,1.0], -
[8.0,7.0,6.0,5.0], -
[1.0,2.0,3.0,4.0], -
[5.0,6.0,7.0,8.0]] -
]) -
a=tf.reshape(a,[1,4,4,2]) -
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,1,1,1],padding='VALID') -
with tf.Session() as sess: -
print("image:") -
image=sess.run(a) -
print (image) -
print("reslut:") -
result=sess.run(pooling) -
print (result)
这里步长为1,窗口大小2×2,输出结果:
-
image: -
[[[[ 1. 2.] -
[ 3. 4.] -
[ 5. 6.] -
[ 7. 8.]] -
[[ 8. 7.] -
[ 6. 5.] -
[ 4. 3.] -
[ 2. 1.]] -
[[ 4. 3.] -
[ 2. 1.] -
[ 8. 7.] -
[ 6. 5.]] -
[[ 1. 2.] -
[ 3. 4.] -
[ 5. 6.] -
[ 7. 8.]]]] -
reslut: -
[[[[ 8. 7.] -
[ 6. 6.] -
[ 7. 8.]] -
[[ 8. 7.] -
[ 8. 7.] -
[ 8. 7.]] -
[[ 4. 4.] -
[ 8. 7.] -
[ 8. 8.]]]]
池化后的图就是:
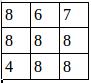
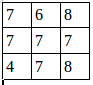
证明了程序的结果是正确的。
我们还可以改变步长
pooling=tf.nn.max_pool(a,[1,2,2,1],[1,2,2,1],padding='VALID')最后的result就变成:
-
reslut: -
[[[[ 8. 7.] -
[ 7. 8.]] -
[[ 4. 4.] -
[ 8. 8.]]]]