目录
Flink功能架构
Flink是分层架构的分布式计算引擎,每层的实现依赖下层提供的服务,同时提供抽象的接口和服务供上层使用。
Flink 架构可以分为4层,包括Deploy部署层、Core核心层、API层和Library层

- 部署层:主要涉及Flink的部署模式。Flink支持多种部署模式,如本地(local)、集群(Standalone/YARN)、云服务器(GCE/EC2)。
可以启动单个JVM,让Flink以local模式运行Flink,也可以以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行,Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
- 核心层:提供了支持Flink计算的全部核心实现,如支持分布式流式处理、JobGraph到ExecutionGraph的映射、调度等,为上层API提供基础服务。
Core层(Runtime)在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)

有状态的流式处理层:最底层的抽象仅仅提供有状态的数据流,它通过处理函数嵌入数据流API(DataStream API)中。用户可以通过它自由处理单流或者多流,并保持一致性和容错性。同时,用户可以进行注册事件时间和处理时间的回调,以实现复杂的计算逻辑
- API层:主要实现了面向无界Stream的流式处理和面向Batch的批量处理API,其中,面向流式处理对应DataStream API,面向批量处理对应DataSet API。
- 库层:该层也可以称为“应用框架层”,它是根据API层的划分,在API层之上构建的满足特定应用的计算实现框架,也分别对应于面向流式处理和面向批量处理两类。面向流式处理支持复杂事件处理(Complex Event Processing,CEP)、基于SQL-like的操作(基于Table的关系操作);面向批量处理支持FlinkML(机器学习库)、Gelly(图处理)。
SQL 既可以运行在DataStreamAPI上,又可以运行在DataSet API上。
Flink输入输出
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
Flink作为大数据生态的一员,除了本身外,可以很好地与生态中的其他组件进行结合使用,大的概况方面来讲,就有输入方面和输出方面。
如下图左右两侧框图,其中绿色背景是流处理方式的场景,蓝色背景是批处理方式的场景。
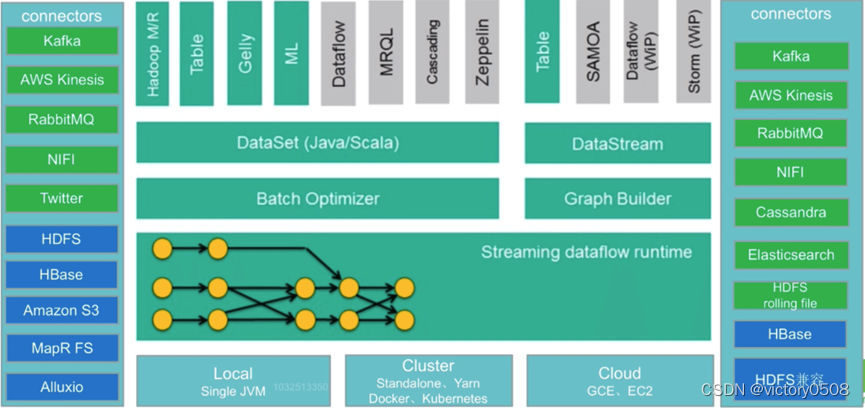
左侧输入Connectors
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Twitter(API)
批处理方式:包含HDFS(分布式文件系统)、HBase(分布式列式数据库)、Amazon S3(文件系统)、 MapR FS(文件系统)、ALLuxio(基于内存分布式文件系统)
右侧输出Connectors
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Cassandra(NOSQL数据库)、ElasticSearch(全文检索)、HDFS rolling file(滚动文件)
批处理方式:包含HBase(分布式列式数据库)、HDFS(分布式文件系统)