文章目录

Flink高手之路4-Flink流批一体API开发
一、流批一体相关的概念
1.数据的时效性
在日常工作中,我们一般处理数据时先把数据存放在表中,然后进行加工和分析,这就产生数据的时效性问题。
如果以年、月、天为单位的级别处理数据,进行统计分析、个性化推荐等,这样的数据一般称为批数据。
如果以小时、分钟、秒这样的单位进行处理,这样的数据一般称之为流数据,比如对网站的实时监控、日志的处理等。在这样的场景下,如果还要收集数据存储到数据库中再进行处理,就不能满足高时效性的需求。
2.流处理和批处理
1)批处理
Batch Analytics,统一收集数据->存储数据->进行批处理,比如MapReduce、Hive、FlinkDataSet等,生成离线报表。
2)流处理
Streaming Analytics,对数据流进行实时处理,比如Storm、FlinkStream、Spark Streaming等,应用场景如实时大屏、实时报表。
3)两者对比
- 时效性不同:流处理实时低延迟,批处理非实时高延迟
- 数据的特征不同:流处理的数据一般是动态、没有边界,而批处理的数据一般静态、有边界
- 应用场景不同:流处理应用在实时场景,而批处理实时性要求不高
- 运行方式不同:流处理持续进行,批处理一次性完成
3.流批一体API
Flink的DataStream API既支持批处理,又支持流处理,可以把批处理当成是流处理的一种特例。
流批一体的优点:
- 可复用:作业可以在流、批两者模式之间自由切换,不用重写代码
- 维护简单:统一的api
4.流批一体的编程模型
数据源(Data Source)->数据处理(Transformations)->数据输出(Data Sink)。
二、Data Source
1.预定义的Source
1)基于集合的Sources
(1)API
env.fromElements(可变参数)
env.fromCollection(各种集合)
env.generateSequence(开始,结束)
env.fromSequence(开始,结束
(2)演示
fromElements
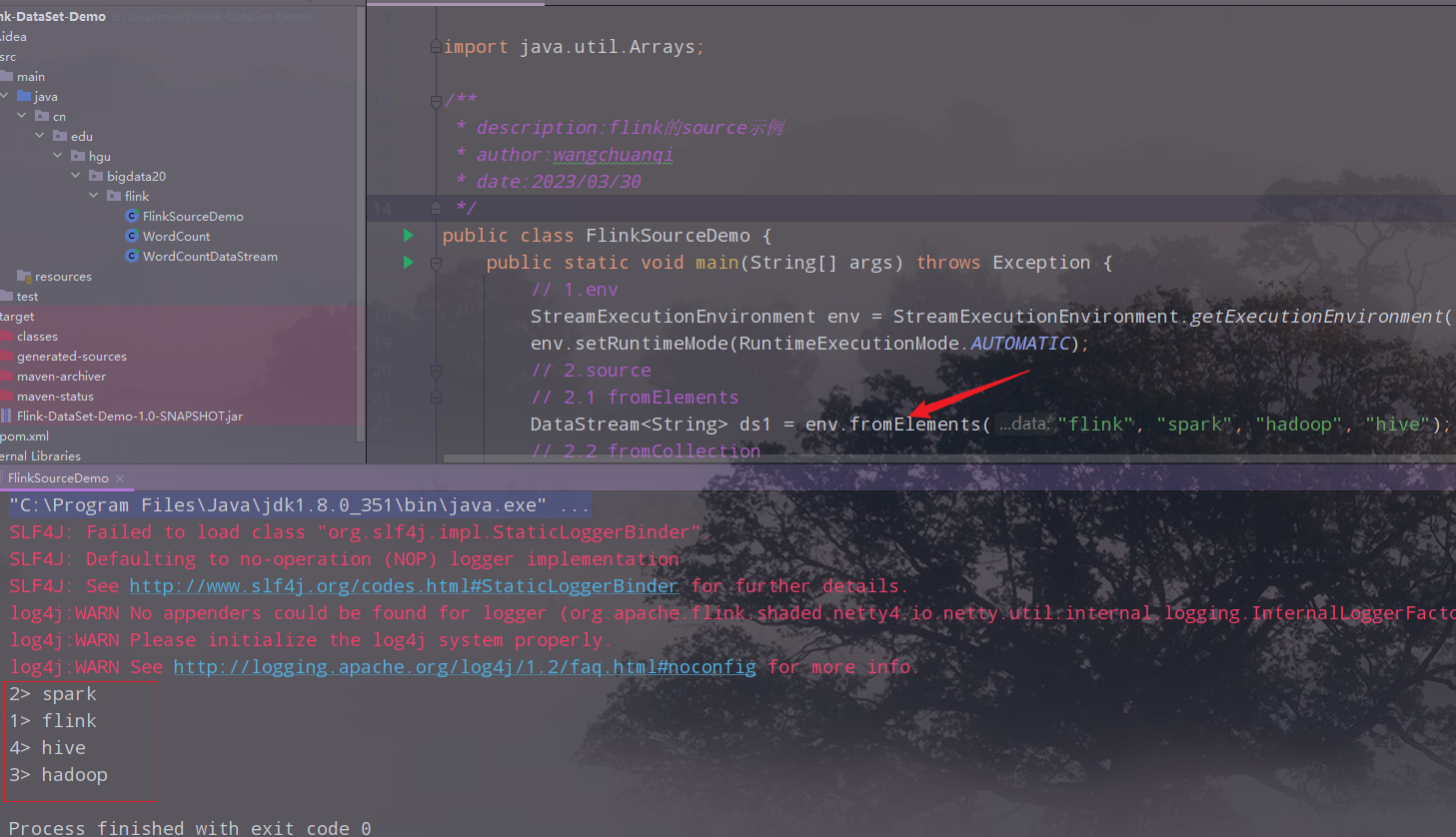
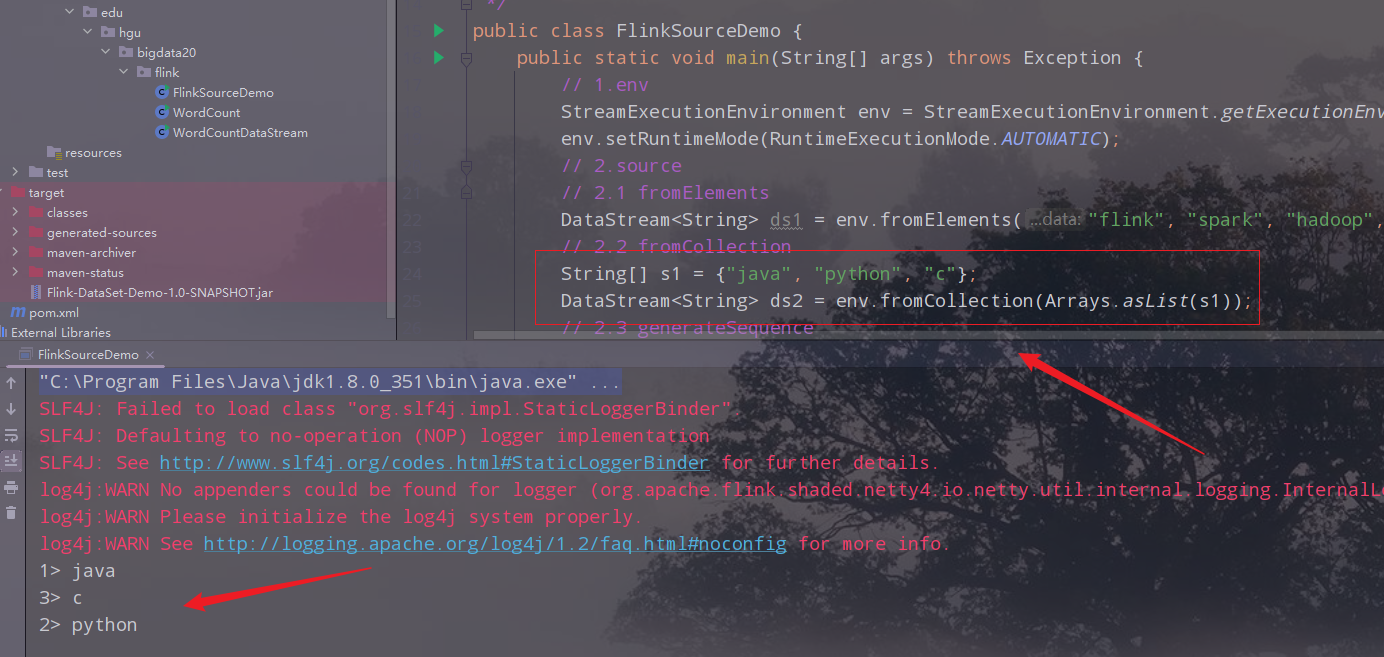
collection
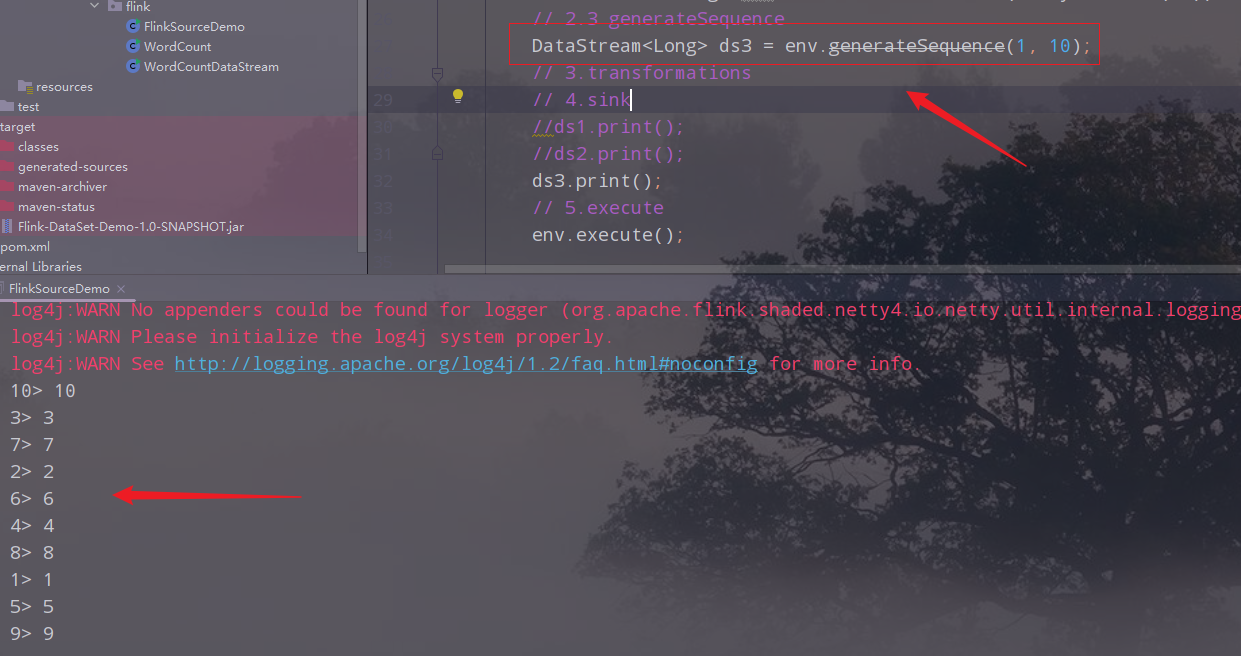
Sequence
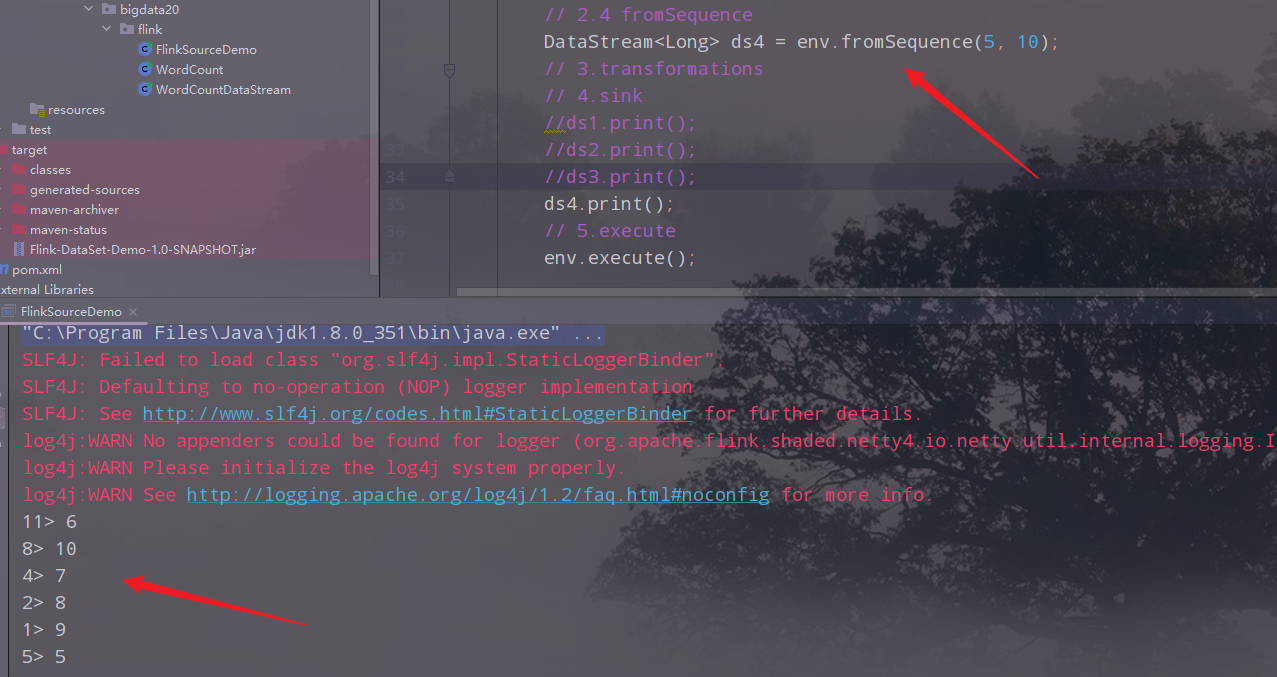
2)基于文件的Source
(1)API
env.readTextFile()
(2)演示
读取本地文件

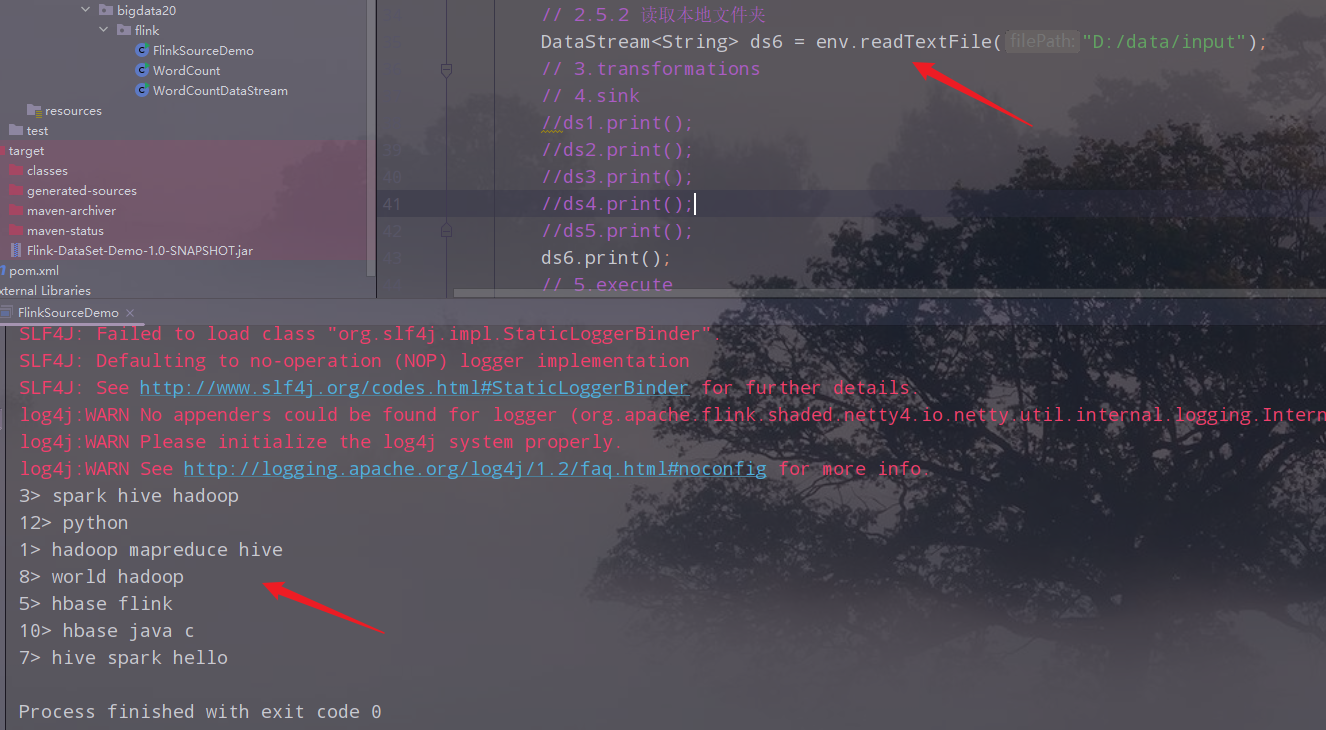
读取本地文件夹
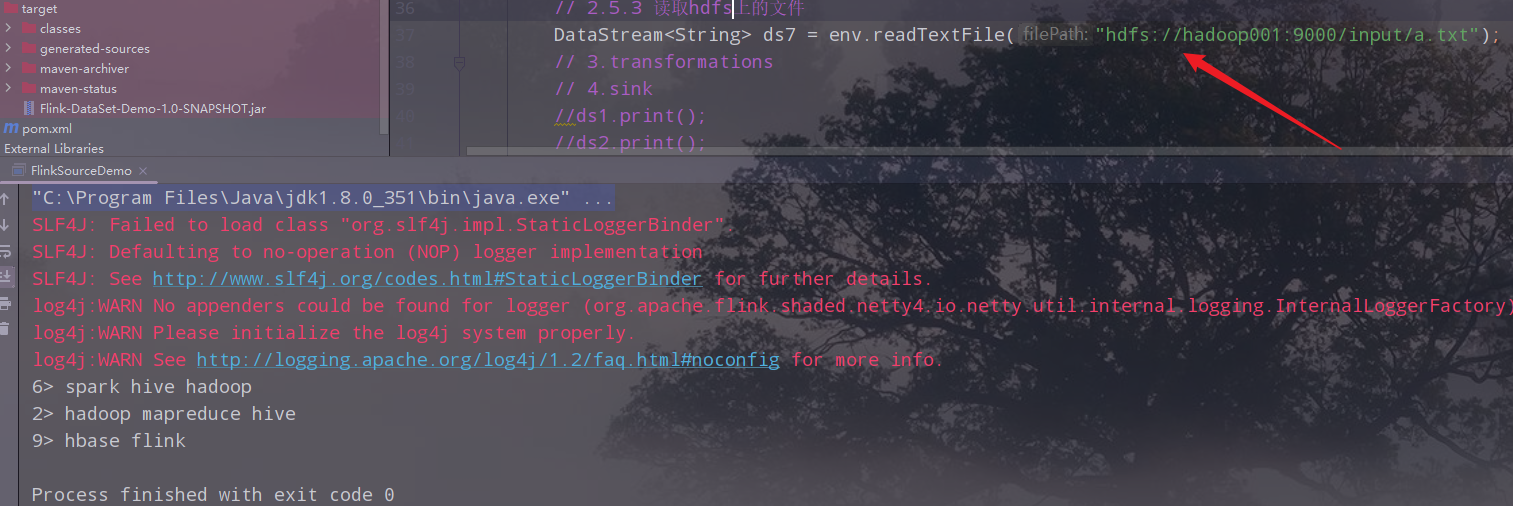
读取集群的文件
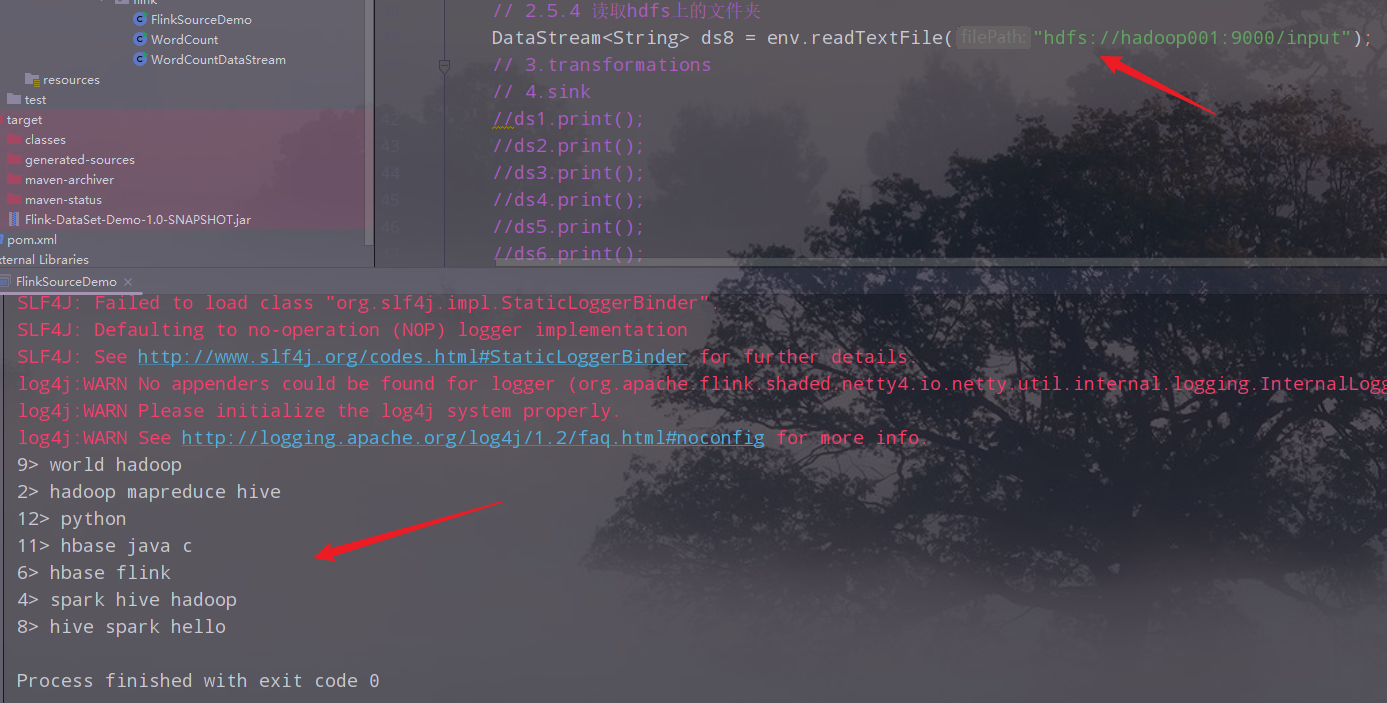
读取集群的文件夹
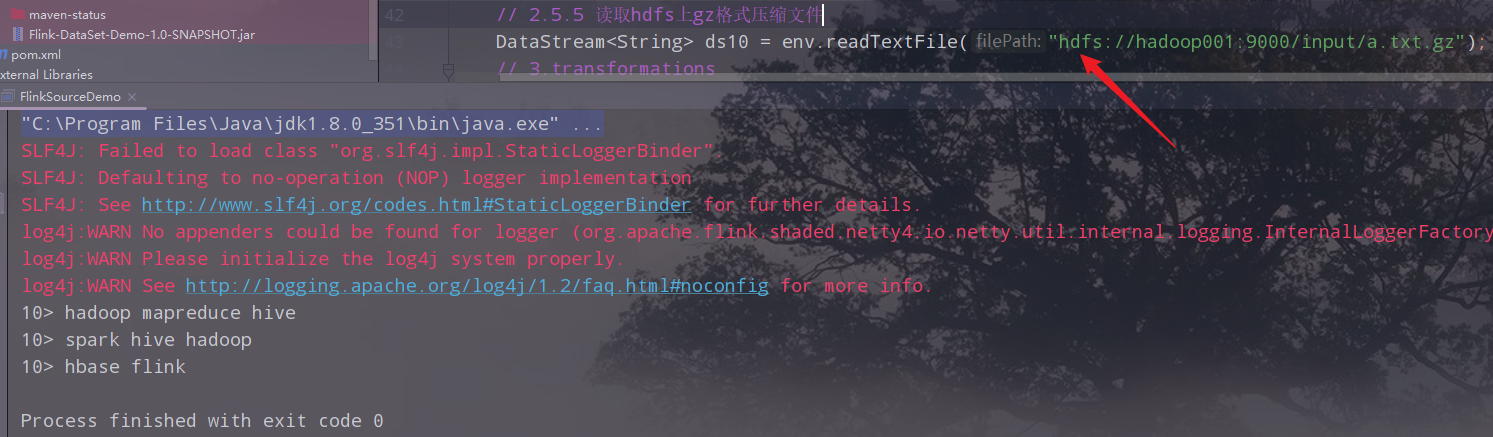
读取gz格式的压缩文件
准备好gz格式的压缩文件
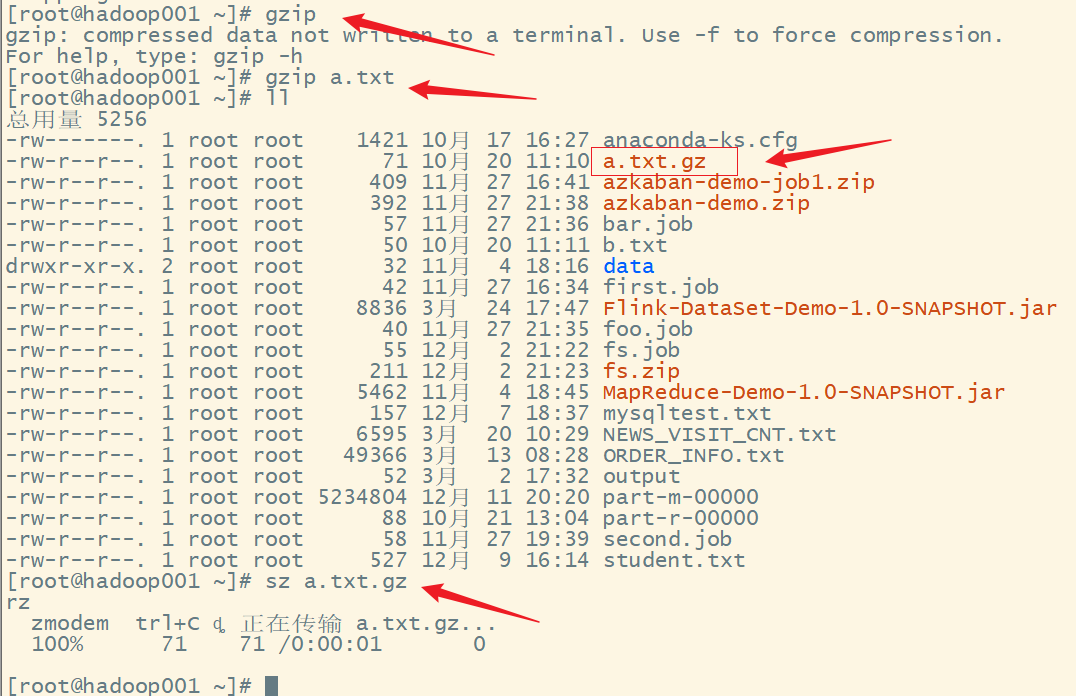
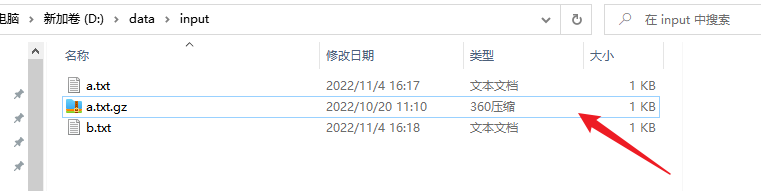
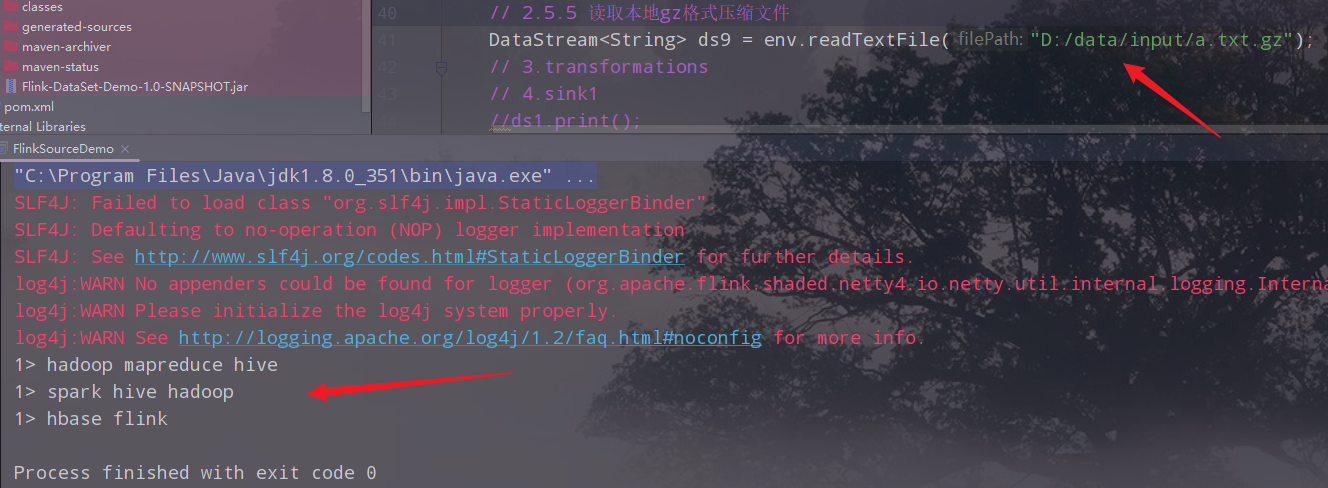
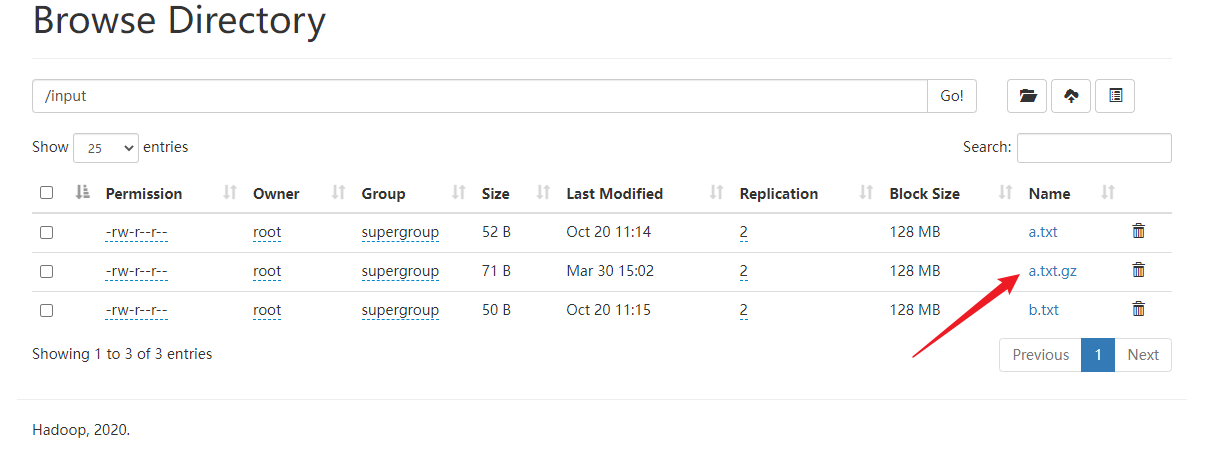
读取集群上gz格式的压缩文件

3)基于socket的source
socket是指网络通信,需要有一个发送端(服务端)和一个接收端(客户端),类似于插头和插座(socket),socket通信需要指定发送端的地址和端口。在实际应用中用于和一些智能硬件对接。比如门禁的人脸识别系统,每个人脸机都有一个ip地址和端口,可以与之进行通信。
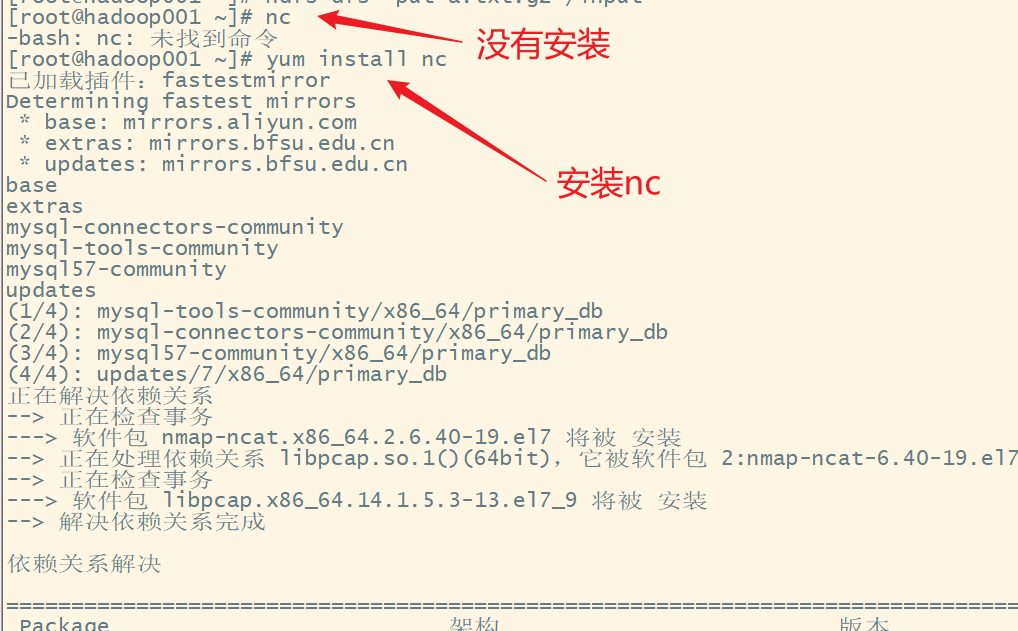
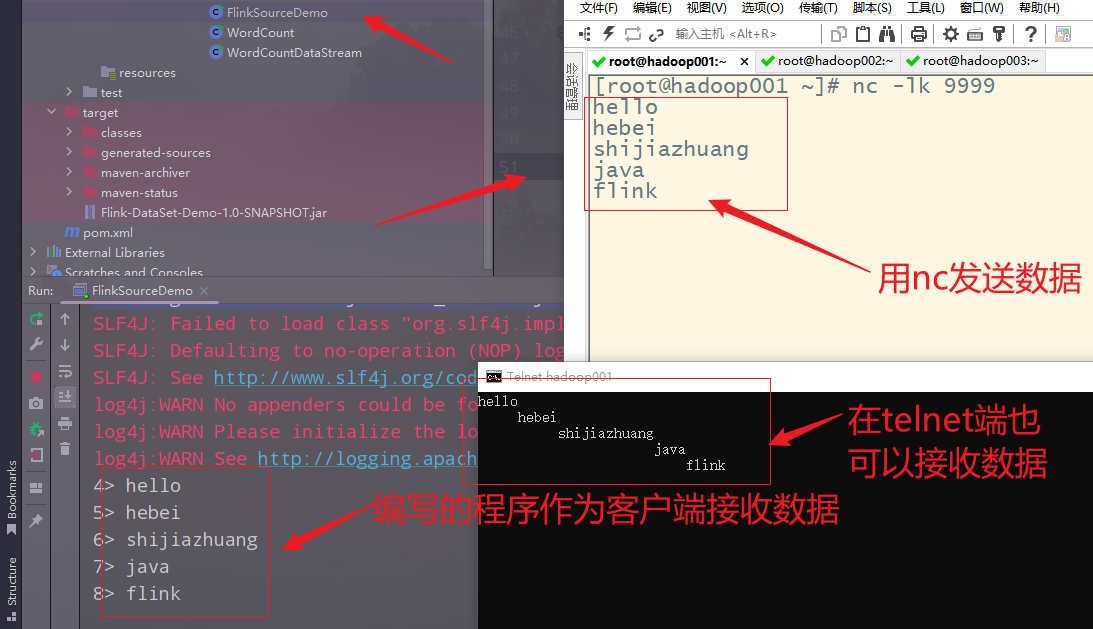
(1)模拟socket通信,安装nc工具
nc是netcat的简称,可以用它向某台主机的某个端口发送数据,模拟socket通信的发送端也就是服务端,作为source。
安装nc工具:
(2)启动nc发送数据

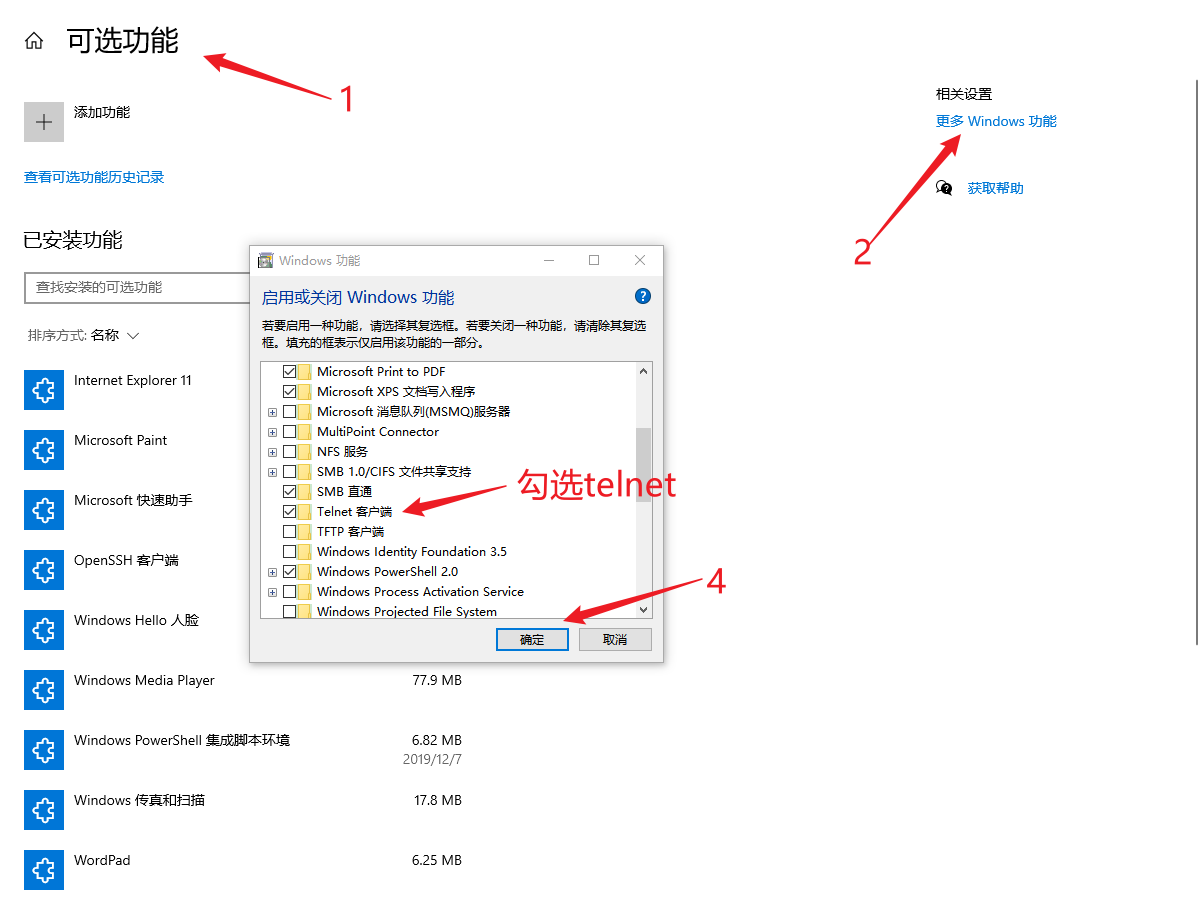
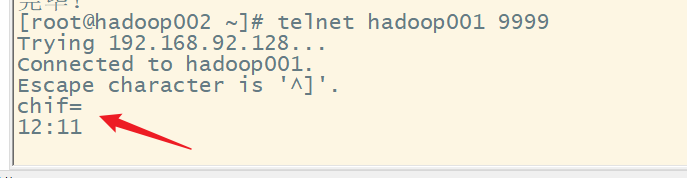
(3)使用telnet来接收数据,测试socket是否工作正常
windows主机安装telnet
执行telnet命令
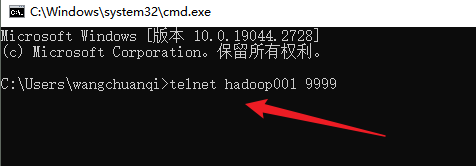
socket通信
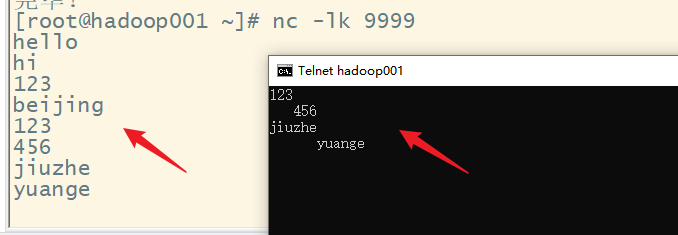
linux主机安装telnet
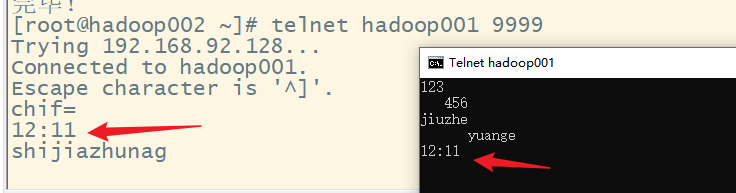
此时,发送端(服务器端)发送的数据,所有的接收端(客户端)都可以收到,但是接收端(客户端)发送的数据,只有发送端(服务器端)能收到

(4)编写Flink代码,作为Socker通信的接收端,接收nc发送的数据进行处理

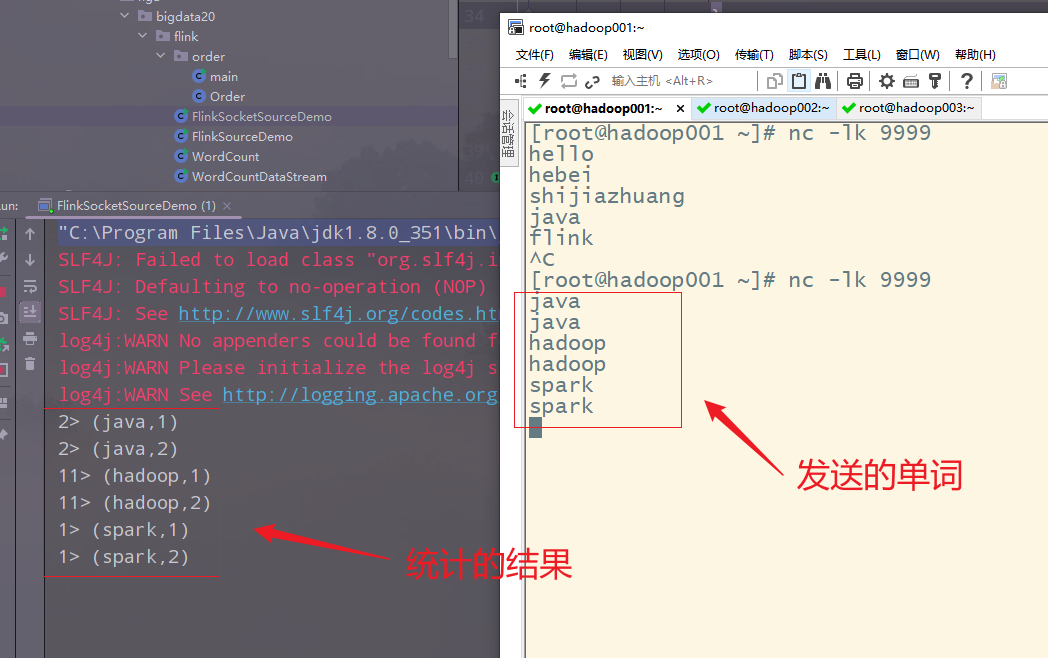
(5)案例-利用基于Socket的source实时统计单词数量
代码:
package cn.edu.hgu.bigdata20.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author 王
* @description 基于socket的实时统计
* @date 2023/04/06
*/
public class FlinkSocketSourceDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//单例模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.source
DataStream<String> ds = env.socketTextStream("hadoop001", 9999);
// 3.处理数据:transformations,使用匿名函数类
// 3.1 将每一行数据切分成一个个的单词组成一个集合
DataStream<String> wordDS = ds.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 参数s代表一行行的文本数据,将其切割为一个个的单词
String[] words = s.split(" ");
// 将切割的每一个单词收集起来成为一个集合
for (String word : words) {
collector.collect(word);
}
}
});
// 3.2 使集合中的每一个单词记为1,组成一个二元组
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
// 此处的s就是传过来的一个个单词,他跟1组成一个二元组
return Tuple2.of(s, 1);
}
});
// 3.3 对新的集合按照key,也就是单词进行分组
KeyedStream<Tuple2<String, Integer>, String> groupDS = wordAndOnesDS.keyBy(t -> t.f0);//lambda形式,fo表示二元组的第一个元素
// 3.4 对数据进行聚合
DataStream<Tuple2<String, Integer>> result = groupDS.sum(1);//此处的1表示二元组的第二个元素
// 4.输出结果:sink
result.print();
// 5.触发执行
// 对于DataSet如果有print,可以省略execute
env.execute();
}
}
执行,输入数据,查看查看结果
2.自定义的Source
1)随机生成数据
(1)api
- SourceFunction:非并行的随机数据源(并行度为1)
- RichSourceFunction:丰富的非并行的随机数据源(并行度为1)
- ParallelSourceFunction:并行的随机数据源(并行度可以大于等于1)
- RichParallelSourceFunction:丰富的并行的随机数据源(并行度可以大于等于1)
(2)需求
每隔1秒随机生成一条订单信息(订单ID,用户ID,订单金额,时间戳)
要求:
- 随机生成订单ID(UUID):UUID 是通用唯一识别码(Universally Unique Identifier)的缩写
- 随机生成用户ID(0-2)
- 随机生成订单金额(0-100)
- 时间戳为当前系统时间
(3)lombok插件
Lombok项目是一个java库,它可以自动插入到编辑器和构建工具中,增强java的性能。不需要再写getter、setter或equals方法,只要有一个注解,你的类就有一个功能齐全的构建器、自动记录变量等等。

使用lombok插件,新版的idea中已经自带,若使用旧版的idea,可以下载插件:
使用时引入lombok的依赖

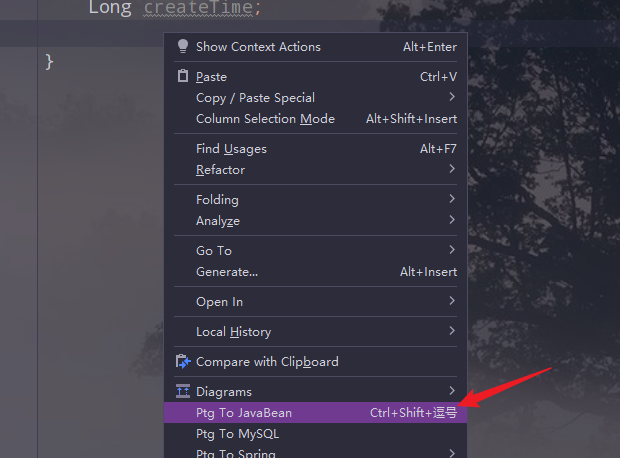
(4) ptg插件(可选)
在我们安装了lombox的基础上,如果不想使用注解,我们可以使用ptg插件,在实体类上右击鼠标就会弹出小窗口,点击Ptg To JavaBean就可以自动生成get、set、有参构造、无参构造和toString。
(5)编程实现
订单实体类
package cn.edu.hgu.bigdata20.flink.order;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 订单类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Order {
//订单id
String id;
// 用户id
Integer userId;
// 订单金额
Integer money;
// 订单时间
Long createTime;
}

主类
package cn.edu.hgu.bigdata20.flink.order;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.Random;
import java.util.UUID;
/**
* 主处理类
* SourceFunction:非并行的随机数据源(并行度为1)
* RichSourceFunction:丰富的非并行的随机数据源(并行度为1)
* ParallelSourceFunction:并行的随机数据源(并行度可以大于等于1)
* RichParallelSourceFunction:丰富的并行的随机数据源(并行度可以大于等于1)
*
* @author 王
* @date 2023/04/08
*/
public class RichParallelSourceFunctionDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.source
DataStream<Order> ds = env.addSource(new RichParallelSourceFunction<Order>() {
// 定义一个标识,是否需要生成数据
private Boolean flag = true;
@Override
public void run(SourceContext<Order> sourceContext) throws Exception {
//持续的生成模拟数据,知道flag为false,也就是执行了取消命令,不在生成数据
Random random = new Random();
while (flag) {
// 每隔1秒(1000毫秒)
Thread.sleep(1000);
// 生成订单id
String id = UUID.randomUUID().toString();
// 生成用户ID,0~2之间的随机数
int userID = random.nextInt(3);
// 生成金额
int money = random.nextInt(101);
// 生成时间戳
long createTime = System.currentTimeMillis();
// 通过Source的上下文返回创建的订单
sourceContext.collect(new Order(id, userID, money, createTime));
}
}
@Override
public void cancel() {
// 取消任务/执行cancel命令时执行
flag = false;
}
});
// 3.transformations
// 4.sink
ds.print();
// 5.execute
env.execute();
}
}
执行,查看结果
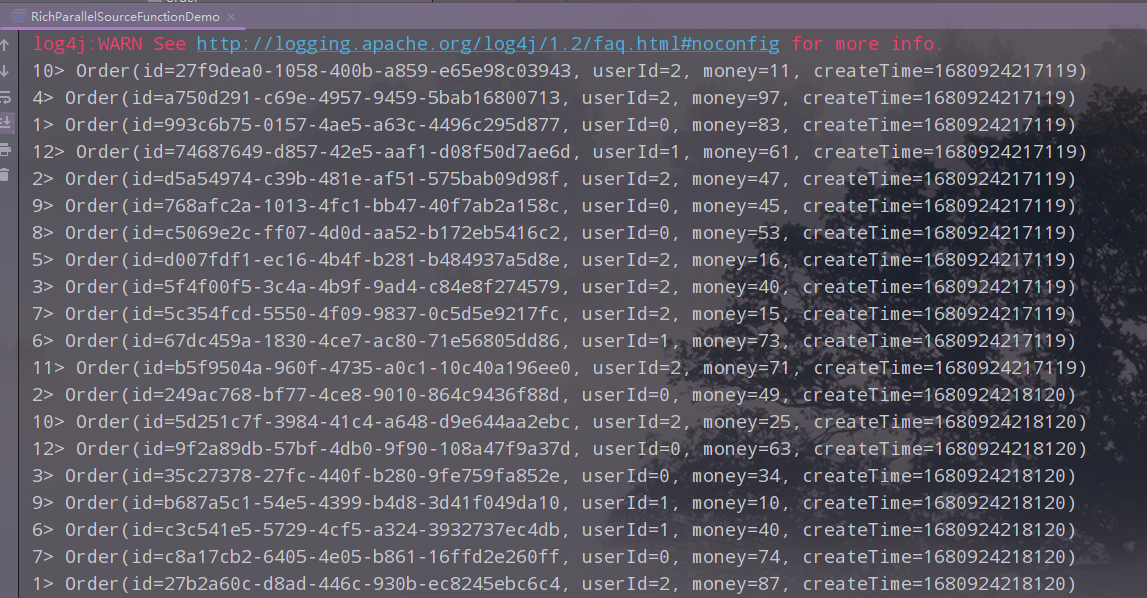
2)MySQL
(1)从mysql中抽取数据有多种方式
-
sqoop:数据迁移工具可以把mysql的数据迁移到hdfs、hive
-
kette:ETL的可视化工具
-
spark:api方式,读取mysql的数据并进行处理
-
flink:api方式,读取mysql的数据并进行处理
(2)需求
从mysql中实时的价值数据,显示出来
(3)启动mysql
本地mysql
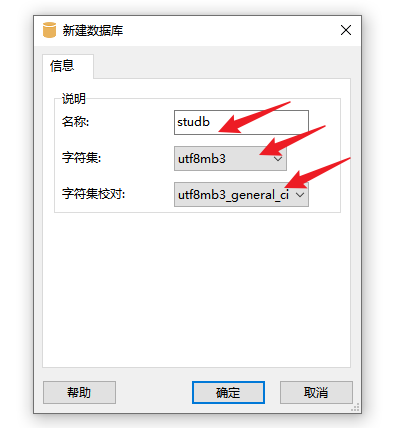
(4)准备数据
① 新建数据库
② 新建表
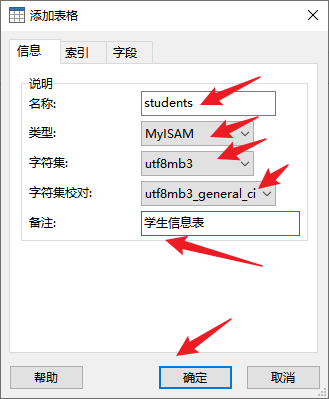
③ 设置字段
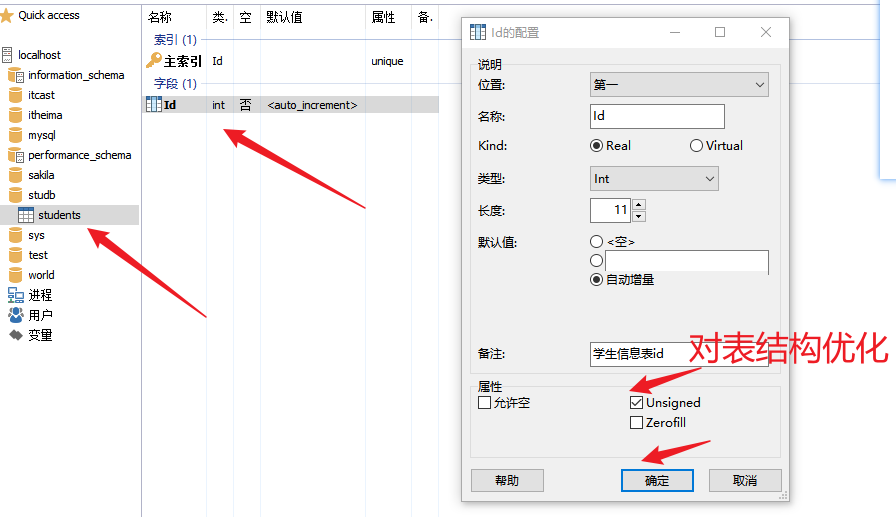
创建其他的字段
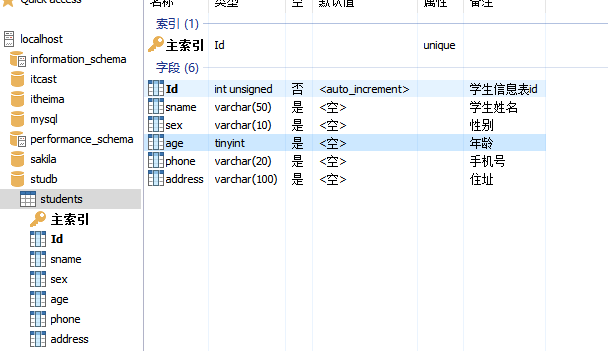
也可以使用SQL命令执行:
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`Id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '学生信息表id',
`sname` varchar(50) DEFAULT NULL COMMENT '学生姓名',
`sex` varchar(10) DEFAULT NULL COMMENT '性别',
`age` tinyint DEFAULT NULL COMMENT '年龄',
`phone` varchar(20) DEFAULT NULL COMMENT '手机号',
`address` varchar(100) DEFAULT NULL COMMENT '住址',
PRIMARY KEY (`Id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb3 COMMENT='学生信息表';
④ 添加纪录
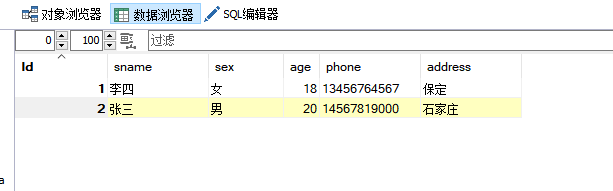
对应的sql语句:
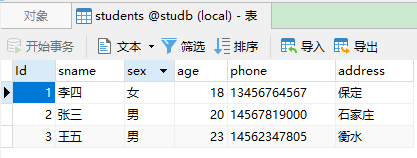
INSERT INTO `students` VALUES (1,'李四','女',18,'13456764567','保定'),(2,'张三','男',20,'14567819000','石家庄'),(3,'王五','男',23,'14562347805','衡水');
(5)pom文件中添加msyql依赖
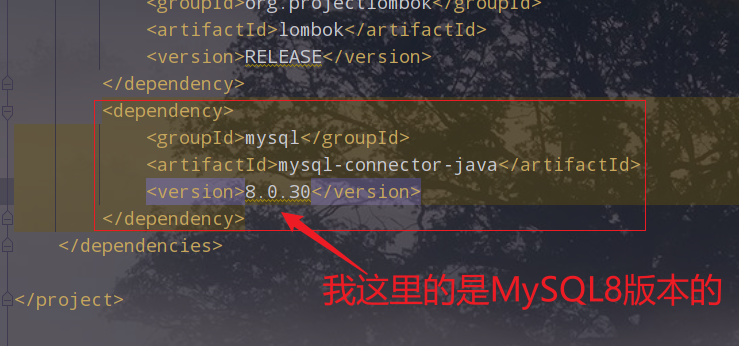
(6)代码实现
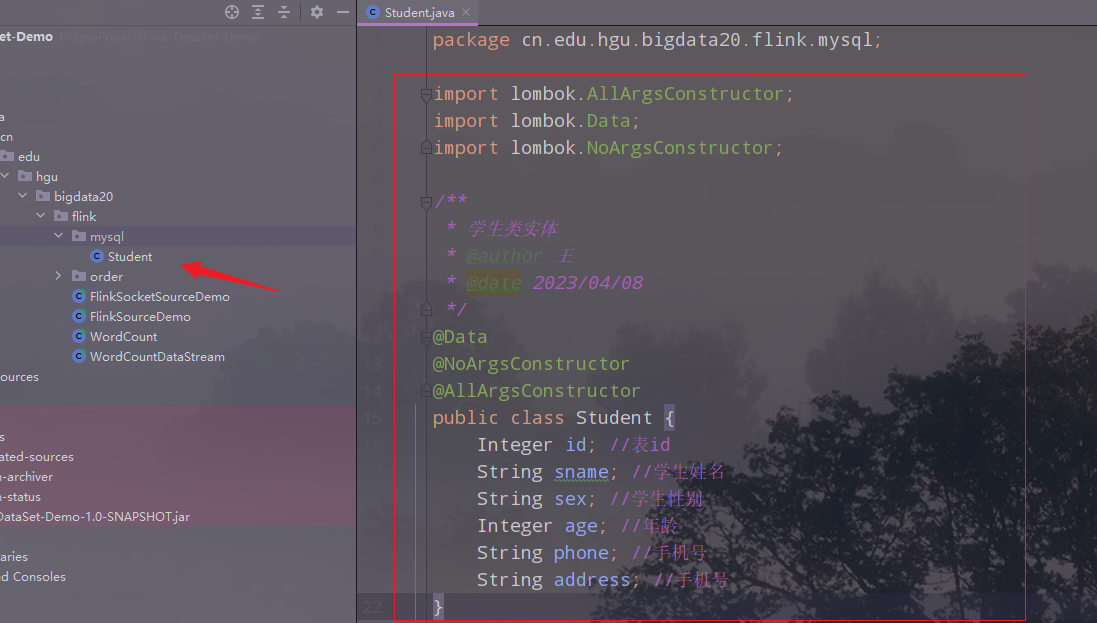
学生实体类
package cn.edu.hgu.bigdata20.flink.mysql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 学生类实体
* @author 王
* @date 2023/04/08
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
Integer id; //表id
String sname; //学生姓名
String sex; //学生性别
Integer age; //年龄
String phone; //手机号
String address; //手机号
}
主类
package cn.edu.hgu.bigdata20.flink.mysql;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* 演示MySQL作为数据源,每隔5秒从MySQL中读取数据
*
* @author 王
* @date 2023/04/08
*/
public class MySQLSourceDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.source
DataStream<Student> ds = env.addSource(new RichParallelSourceFunction<Student>() {
// 定义一个标识,是否需要生成数据
private Boolean flag = true;
// 定义连接对象
private Connection conn = null;
// 定义语句对象
private Statement st = null;
// 定义结果集对象
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
// 1.加载MySQL驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2.获取数据库连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/studb", "root", "****");
// 3.通过连接获取语句对象
st = conn.createStatement();
}
@Override
public void close() throws Exception {
// 6.关闭资源
rs.close();
st.close();
conn.close();
}
@Override
public void run(SourceContext<Student> sourceContext) throws Exception {
while (flag) {
// 每隔1秒(2000毫秒)
Thread.sleep(2000);
// 4.执行语句对象得到结果集
String sql = "Select * from students";
rs = st.executeQuery(sql);
// 5.操作结果集
while (rs.next()) {
// id
Integer id = rs.getInt("id");
// 姓名
String sname = rs.getString("sname");
// 性别
String sex = rs.getString("sex");
// 年龄
Integer age = rs.getInt("age");
// 手机号
String phone = rs.getString("phone");
// 住址
String address = rs.getString("address");
// 通过Source的上下文返回信息
sourceContext.collect(new Student(id, sname, sex, age, phone, address));
}
}
}
@Override
public void cancel() {
flag = false;
}
});
// 3.transformations
// 4.sink
ds.print();
// 5.execute
env.execute();
}
}
注意:
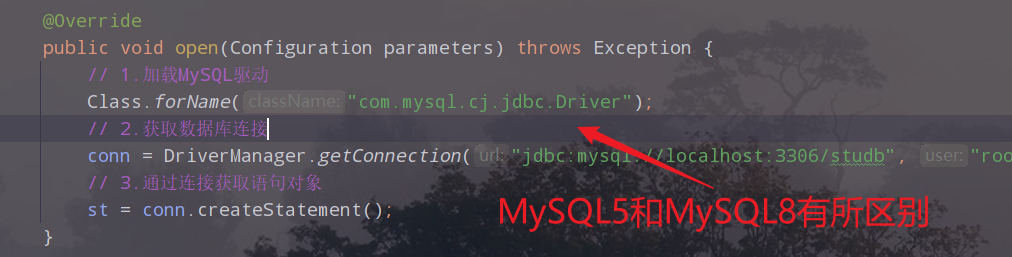
执行,查看结果
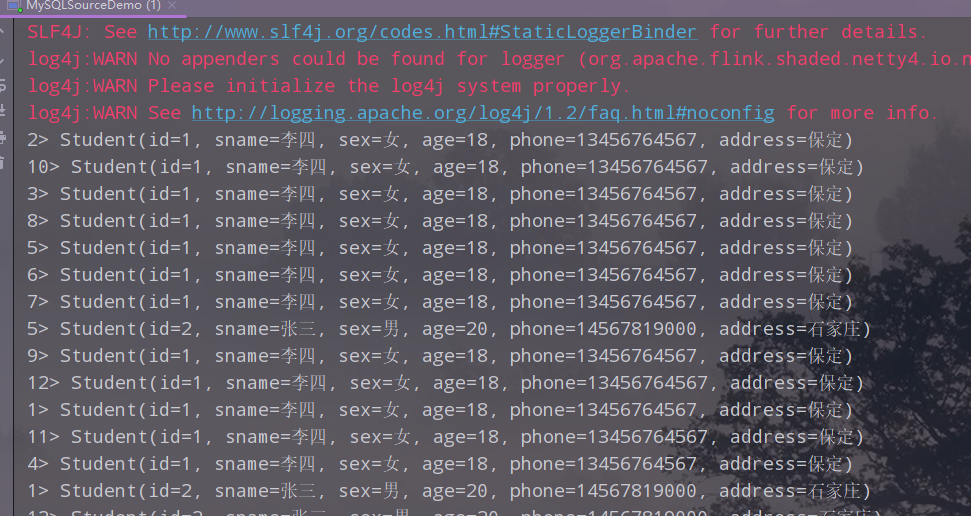
添加一条记录,再次查看结果
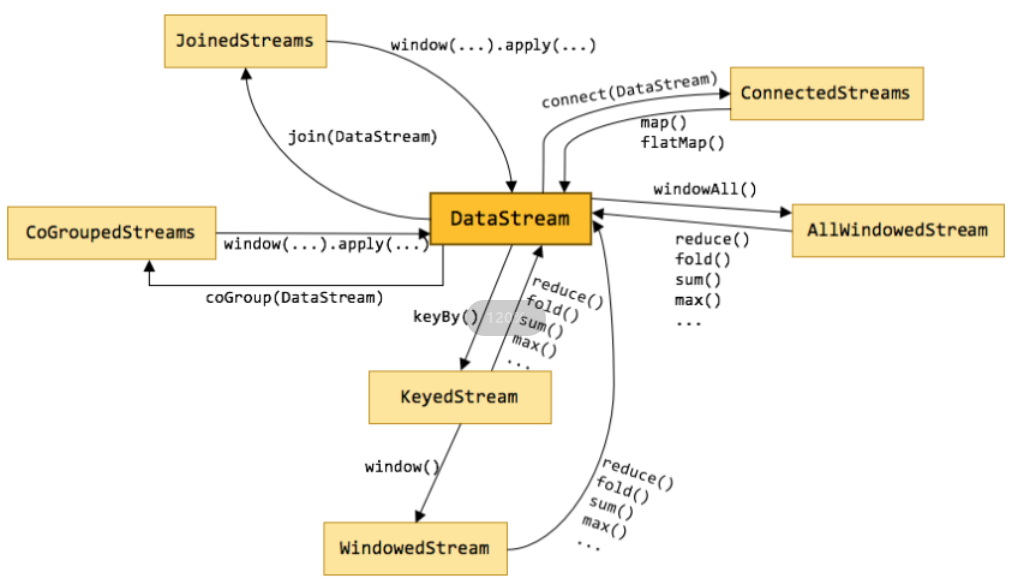
三、Transformations
1. 官网API列表
官网api网址:https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/operators/overview/
2. 整体分类
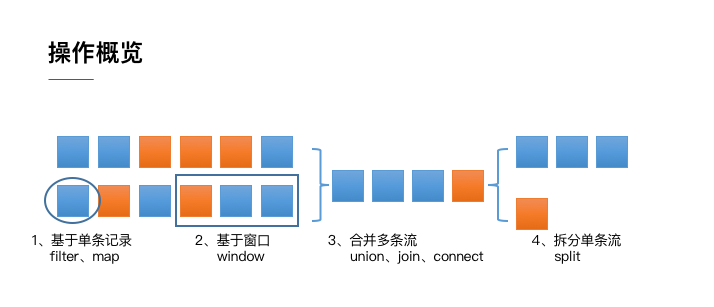
整体来说,流式数据上的操作可以分为四类。
1)对单条纪录的操作
比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)。
2)对多条记录的操作
比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理。
3)对多个流进行操作并转换为单个流(合并union)
例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作。
4)把一个流拆分成多个流(拆分)
DataStream 还支持与合并对称的拆分操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
3.基本操作
1)map
map:将函数作用在集合中的每一个元素上,并返回作用后的结果
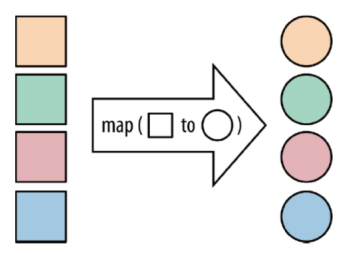
2)flatMap
flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果

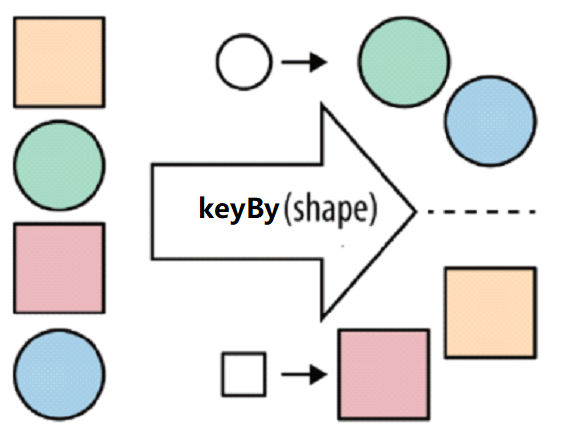
3)keyBy
按照指定的key来对流中的数据进行分组,要注意的是,流处理中没有groupBy,而是keyBy
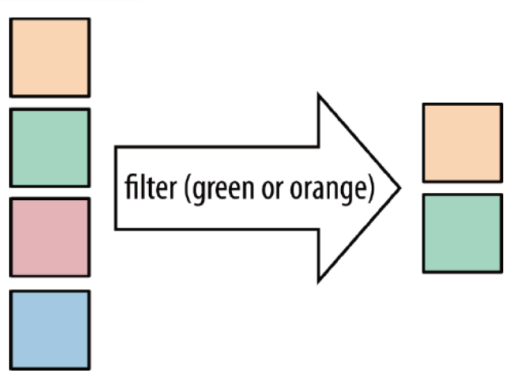
4)filter
filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
5)sum
sum:按照指定的字段对集合中的元素进行求和
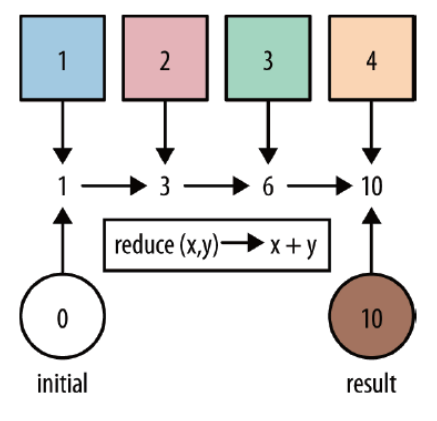
6)reduce
reduce:对集合中的元素进行聚合
4.合并
1)union和connect
union:
union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。

connect:
connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
connect只能连接两个数据流,union可以连接多个数据流。
connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。
两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
2)需求
- 将两个String类型的流进行union
- 将一个String类型和一个Long类型的流进行connect
3)代码实现
package cn.edu.hgu.bigdata20.flink.union;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.Arrays;
/**
* 演示Flink的Union和connect的使用
*
* @author 王
* @date 2023/04/08
*/
public class FlinkUnionAndConnectDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink", "hive");
String[] text = {
"java", "flume", "azkaban", "sqoop"};
DataStream<String> ds2 = env.fromCollection(Arrays.asList(text));
DataStream<Long> ds3 = env.fromSequence(5, 10);
//3.Transformation
// union
DataStream<String> unionResult = ds1.union(ds2);
// connection
ConnectedStreams<String, Long> connectResult = ds1.connect(ds3);
//interface CoMapFunction<IN1, IN2, OUT>
DataStream<String> result = connectResult.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String s) throws Exception {
return s;
}
@Override
public String map2(Long aLong) throws Exception {
return aLong.toString();
}
});
//4.Sink
// unionResult.print();
result.print();
//5.execute
env.execute();
}
}
4)执行,查看结果
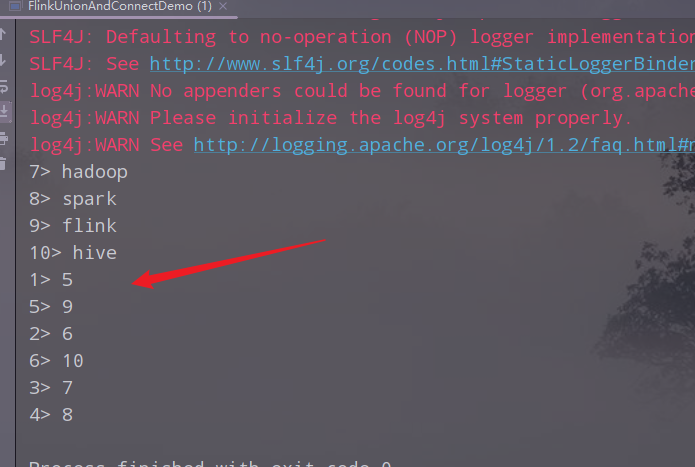
5. 拆分
1) select和Side Outputs
Select就是获取分流后对应的数据
Side Outputs:可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中
2) 需求:
对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
3)代码实现
package cn.edu.hgu.bigdata20.flink.select;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* 演示Flink的Select和Side的使用
*
* @author 王
* @date 2023/04/08
*/
public class FlinkSelectAndSideDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStreamSource<Long> ds = env.fromSequence(1, 10);
//3.Transformation
// 定义偶数标签
OutputTag<Long> tag_even = new OutputTag<>("偶数", TypeInformation.of(Long.class));
// 定义奇数标签
OutputTag<Long> tag_odd = new OutputTag<>("奇数", TypeInformation.of(Long.class));
//对流中的数据进行处理
SingleOutputStreamOperator<Long> tagResult = ds.process(new ProcessFunction<Long, Long>() {
@Override
public void processElement(Long aLong, ProcessFunction<Long, Long>.Context context, Collector<Long> collector) throws Exception {
// 判断奇偶性
if (aLong % 2 == 0) {
context.output(tag_even, aLong);
} else {
context.output(tag_odd, aLong);
}
}
});
// 偶数流
DataStream<Long> evenResult = tagResult.getSideOutput(tag_even);
// 偶数流
DataStream<Long> oddResult = tagResult.getSideOutput(tag_odd);
//4.Sink
evenResult.print("偶数");
oddResult.print("奇数");
//5.execute
env.execute();
}
}
4)执行,查看结果
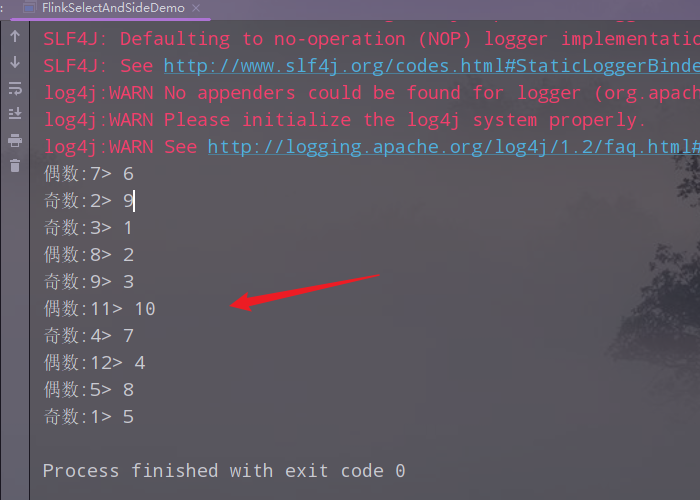
6.分区
1)rebalance重平衡分区
类似与spark中的repartition,但是功能更强大,可以直接解决数据倾斜问题。
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;
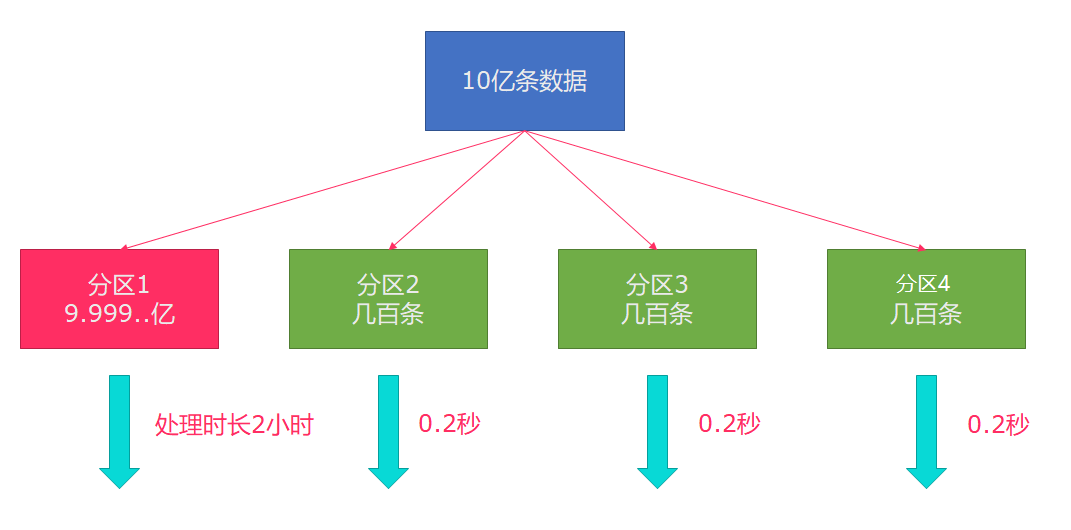
所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)

2)代码实现
package cn.edu.hgu.bigdata20.flink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 王
* @description flink的Rebalance重平衡示例
* @date 2023/04/20
*/
public class TransformationRebalanceDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.source
DataStream<Long> ds = env.fromSequence(0, 100);
// 3.Transformation
// 3.1 过滤操作,有可能出现数据倾斜
DataStream<Long> filterDS = ds.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
// 3.2 map操作,将数据转为(分区编号/子任务编号, 数据) 二元组
// Rich表示多功能的,比MapFunction要多一些API可以供我们使用
DataStream<Tuple2<Integer, Integer>> result1 = filterDS.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//获取分区编号/子任务编号
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
// 3.3 rebalance操作,对数据进行重平衡,然后再进行转换
DataStream<Tuple2<Integer, Integer>> result2 = filterDS.rebalance().map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//获取分区编号/子任务编号
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
//4.sink
//result1.print();//有可能出现数据倾斜
result2.print();//在输出前进行了rebalance重分区平衡,解决了数据倾斜
//5.execute
env.execute();
}
}
3)输出结果
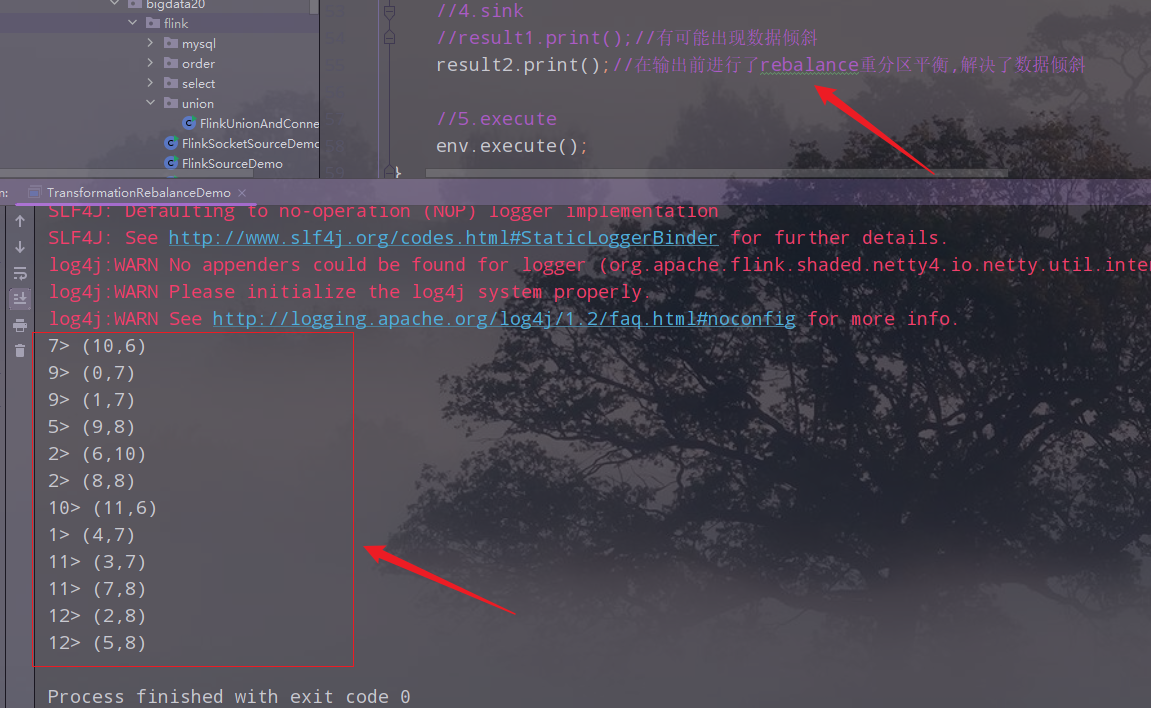
4)其他分区
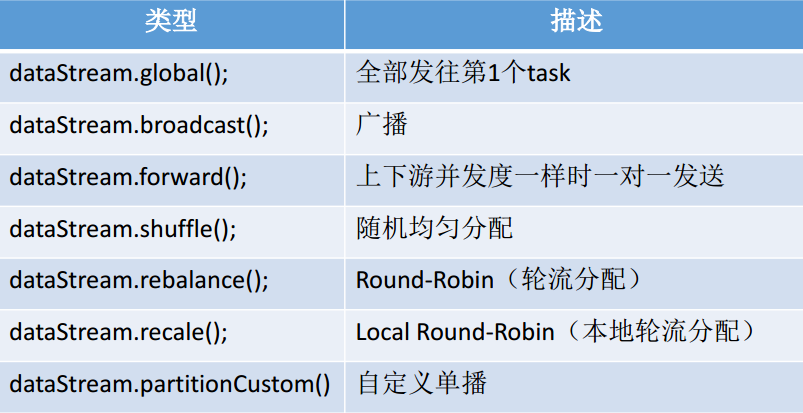
说明:
recale分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。
举例:
上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
四、Data Sink
1.预定义Sink
1)基于控制台和文件的Sink
- print:直接输出到控制台
- printToErr:直接输出到控制台,用红色
- writeAsText(本地/HDFS):输出到本地或者hdfs上,说明:如果并行度为1输出为文件,如果并行度>1,输出为文件夹,如果不加并行度,则使用默认的并行度(cpu核数),输出也为文件夹
// 4.输出结果:sink
// aggResult.print(); // 直接输出到控制台
// aggResult.printToErr(); // 直接输出到控制台,用红色
// 把结果储存到hdfs上
// System.setProperty("HADOOP_USER_NAME", "root");
// aggResult.writeAsText("hdfs://hadoop001:9000/output/wordcount")
// 默认的并行度12(根据自己的核数),输出文件夹
// aggResult.writeAsText("E:\\wordcount\\output\\count1", FileSystem.WriteMode.OVERWRITE);
// 并行度>1,输出文件夹
// aggResult.writeAsText("E:\\wordcount\\output\\count2", FileSystem.WriteMode.OVERWRITE).setParallelism(2);
// 并行度为1,输出为文件
aggResult.writeAsText("E:\\wordcount\\output\\count3", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
print:
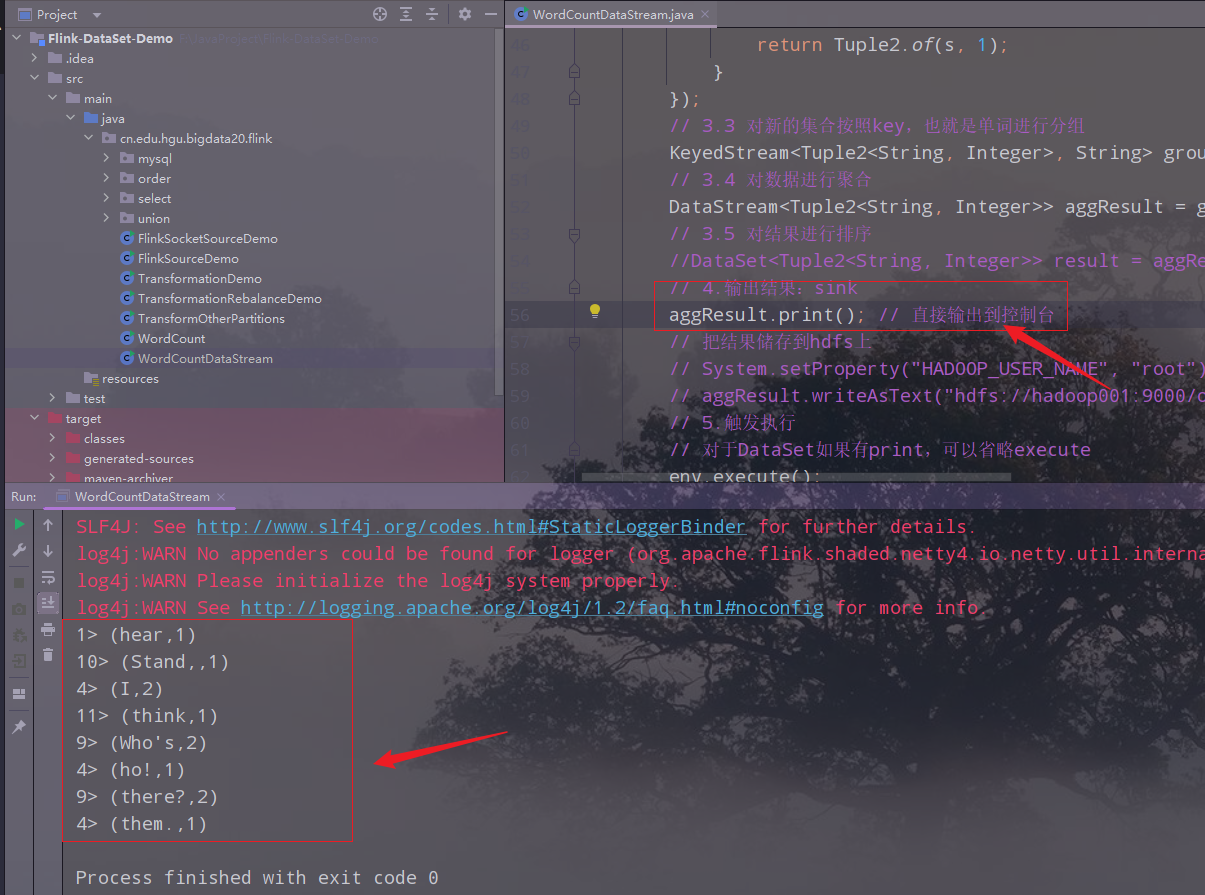
printToErr
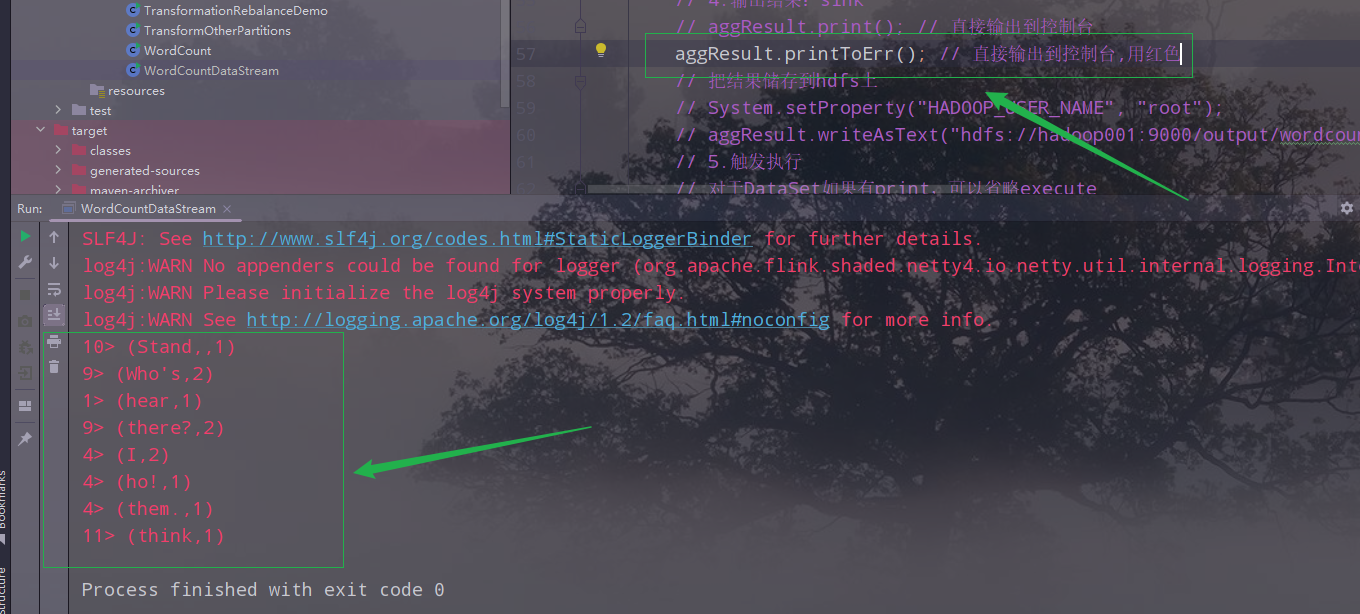
默认的并行度12(根据自己的核数),输出文件夹:

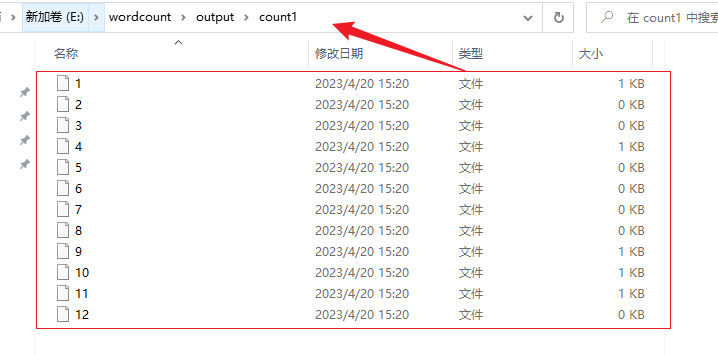
并行度>1,输出文件夹:

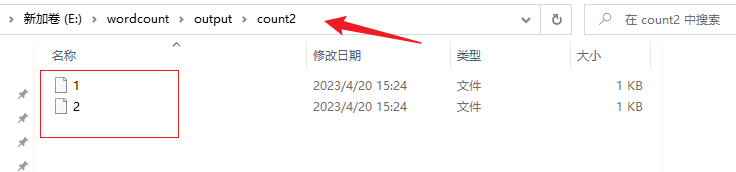
并行度为1,输出为文件

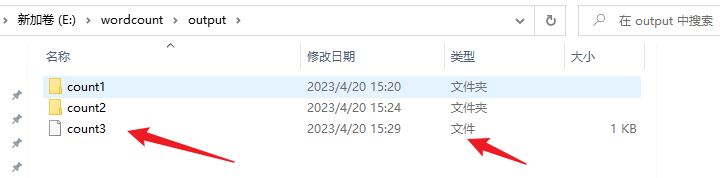
2.自定义Sink
1)MySQL
可以把经过Flink处理的数据保存到MySQL中
2)主程序
package cn.edu.hgu.bigdata20.flink;
import cn.edu.hgu.bigdata20.flink.mysql.Student;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* description:使用Flink的流处理进行单词计数
* author:王
* date:2023/04/20
*/
public class SinkMySQLDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.Source
// 2.1 添加自定义的source,连接mysql,设置并行度为2
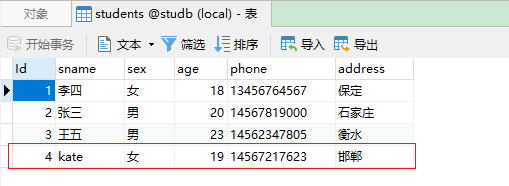
DataStream<Student> ds = env.fromElements(new Student(null, "kate", "女", 19, "14567217623", "邯郸"));
// 3.Transformation
// 4.Sink
ds.addSink(new MySQLSink());
//5.execute
env.execute();
}
}
3)实体类
package cn.edu.hgu.bigdata20.flink.mysql;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* description:学生类实体
* author 王
* date 2023/04/08
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
Integer id; //表id
String sname; //学生姓名
String sex; //学生性别
Integer age; //年龄
String phone; //手机号
String address; //手机号
}
4)自定义数据下沉工具类
package cn.edu.hgu.bigdata20.flink;
import cn.edu.hgu.bigdata20.flink.mysql.Student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* description:自定义数据下沉工具类
* author 王
* date 2023/04/20
*/
public class MySQLSink extends RichSinkFunction<Student> {
private Connection conn = null;
private PreparedStatement st = null;
@Override
public void open(Configuration parameters) throws Exception {
// 从mysql中读取数据,创建Student对象,添加到上下文,作为source
// 1.加载mysql驱动,开启连接
// Class.forName("com.mysql.jdbc.Driver"); // mysql5
Class.forName("com.mysql.cj.jdbc.Driver"); // mysql8
// 2.获取连接Connection
String url = "jdbc:mysql://localhost:3306/studb";
String user = "root";
String password = "123456";
conn = DriverManager.getConnection(url, user, password);
// 3.获取执行语句对象PreparedStatement(参数化的执行对象)
String sql = "insert into `students` values (null, ?, ?, ?, ?, ?)";
st = conn.prepareStatement(sql);
}
@Override
public void invoke(Student value, Context context) throws Exception {
//给st中的?设置具体值
st.setString(1, value.getSname());
st.setString(2, value.getSex());
st.setInt(3, value.getAge());
st.setString(4, value.getPhone());
st.setString(5, value.getAddress());
//执行sql
st.executeUpdate();
}
@Override
public void close() throws Exception {
if (conn != null) conn.close();
if (st != null) st.close();
}
}
5)输出结果
原始数据:
执行后数据:
五、Connector
1. JDBC
官网API:https://ci.apache.org/projects/flink/flink-docs-release-1.17/dev/connectors/jdbc.html
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env
.fromElements(...)
.addSink(JdbcSink.exactlyOnceSink(
"insert into books (id, title, author, price, qty) values (?,?,?,?,?)",
(ps, t) -> {
ps.setInt(1, t.id);
ps.setString(2, t.title);
ps.setString(3, t.author);
ps.setDouble(4, t.price);
ps.setInt(5, t.qty);
},
JdbcExecutionOptions.builder()
.withMaxRetries(0)
.build(),
JdbcExactlyOnceOptions.defaults(),
() -> {
// create a driver-specific XA DataSource
// The following example is for derby
EmbeddedXADataSource ds = new EmbeddedXADataSource();
ds.setDatabaseName("my_db");
return ds;
});
env.execute();
参考文章:
【MySql】Navicat 连接数据库出现1251 - Client does not support authentication protocol … 问题的解决方法
"insert into books (id, title, author, price, qty) values (?,?,?,?,?)",
(ps, t) -> {
ps.setInt(1, t.id);
ps.setString(2, t.title);
ps.setString(3, t.author);
ps.setDouble(4, t.price);
ps.setInt(5, t.qty);
},
JdbcExecutionOptions.builder()
.withMaxRetries(0)
.build(),
JdbcExactlyOnceOptions.defaults(),
() -> {
// create a driver-specific XA DataSource
// The following example is for derby
EmbeddedXADataSource ds = new EmbeddedXADataSource();
ds.setDatabaseName("my_db");
return ds;
});
env.execute();
参考文章:
[Lombok](https://baike.baidu.com/item/Lombok/23780246?fr=aladdin)
[JavaBean](http://t.csdn.cn/ix8FK)
[【MySql】Navicat 连接数据库出现1251 - Client does not support authentication protocol ...... 问题的解决方法](http://t.csdn.cn/Y2Gzz)
[Flink 实时去重方案](http://t.csdn.cn/Av7KH)