摘要:本文整理自上海数⽲信息科技有限公司⼤数据架构师杨涵冰,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为六个部分:
- 序
- 传统方案与流批⼀体
- 数据的流批一体方案
- 逻辑的流批一体方案
- 数据一致性方案
- 流、批、调用一体方案
一、序
1.1. 一些问题
我们在整个实时流模型开发的过程中,经常会遇到一些问题:
- 在对现有模型策略精耕细作之前,还有没有什么数据没有被使⽤?
- 离线特征逻辑是否已经⾜够完整,为什么实时特征逻辑需要重新梳理与补充逻辑?
- 不确定使⽤场景,⽆法区分点查和跑批,能不能同时覆盖?
- 流式处理逻辑难以理解,为什么要流 Join,不能直接“取数”吗?
- 实时模型策略空跑测试需要很⻓时间,能不能缩短?
- 模型策略开发训练很快,上线时开发所需的实时特征却需要很久,能不能加速?特别是当我们要进行一些深度学习模型开发的时候,我们需要的实时数据会很多,且结构复杂,这个时候就更加难以使用传统实时特征的方式来进行解决。那么我们要如何将它上线呢?
1.2. 一些方案
针对以上的问题,我们提出了一些方案:
- 数据上,存储所有状态变化数据,还原任意时刻的数据切片状态。
- 逻辑上,使用 Flink 流批一体,以流为主,逻辑一致,无需验证口径。
- 执行上,使用流、批、调用一体化方案,自适应不同的场景。
- 开发上,使用“取数”而不是流合并,封装实时流特有概念,降低实时开发门槛。
- 测试上,支持任意时间段回溯测试,增加实时开发测试速度。
- 上线上,自助式的流批一体模型开发上线,减少沟通环节,增加上线效率。
二、传统方案与流批一体
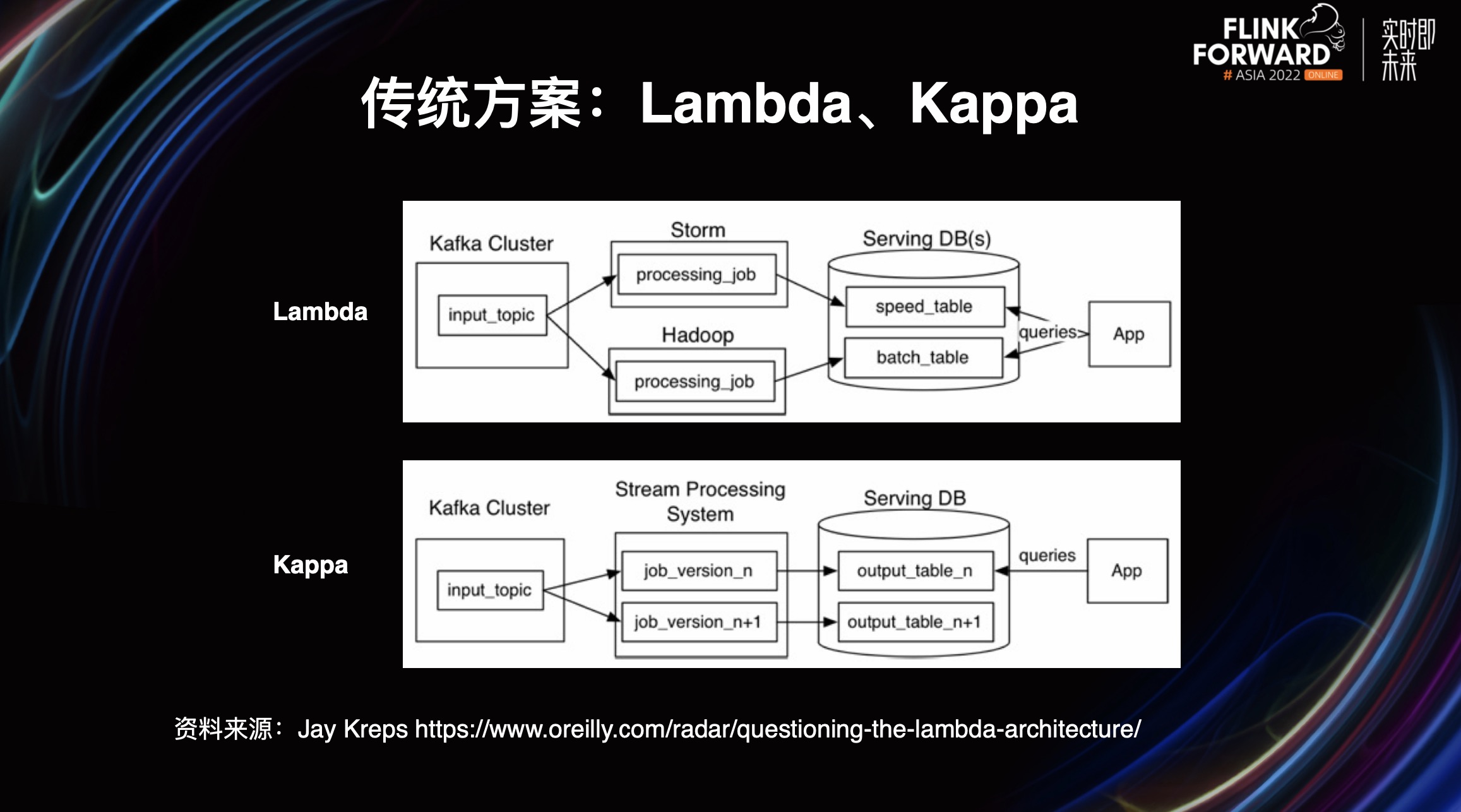
有两个很经典的传统方案分别是 Lambda 架构和 Kappa 架构。
Lambda 架构拥有实时链路和离线链路两个不同的数据链路。其中,实时链路是一个实时作业,它会将数据实时写入 Serving DB。离线链路则是一个离线作业,它会通过批处理的方式将数据写入 Serving DB。最后线上应用通过 Serving DB 进行访问。
Kappa 架构的实时链路和离线链路都使用了相同的流式处理系统,最后线上应用也是通过 Serving DB 进行访问。

那么 Lambda 和 Kappa 有什么优缺点呢?
Lambda 架构的优点包括架构简单;很好的结合了离线批处理和实时流处理的优点;稳定且实时计算成本可控;离线数据易于订正。缺点包括实时、离线数据难以保持一致结果,需要维护两套系统。
Kappa 架构的优点包括只需要维护实时处理模块;可以通过消息重放进行数据回溯;无需离线和实时数据合并。缺点包括强依赖于消息中间件缓存能力;实时数据处理时存在丢失数据可能。
Kappa 在抛弃了离线数据处理模块的时候,同时也抛弃了离线计算更稳定可靠的特点。Lambda 虽然保证了离线计算的稳定性,但双系统的维护成本高且两套代码的运维很困难。
在数据源来自于 Kafka 的场景下,Kappa 看上去没有什么太多问题。但在互联网金融场景下,我们主要的数据源都来自事务性数据,比如说 MySQL,它的实时流数据可以通过 Binlog 进行同步,但最终数据还是要以 MySQL 内存储的数据为准。如果使用 Kappa,整个链路就会变成一个纯增量链路,累积的误差将难以进行修正。此时我们需要 Lambda 架构的离线修正能力。

我们提出的方案是 Lambda+Kappa,左边是 Lambda,右边是 Kappa。
左边的 Lambda 部分,我们以 MySQL 为例,MySQL 的 Binlog 会被同步到 Kafka,然后我们将 Kafka 的消息变化数据存入 HBase。同时它的全量数据会通过 Sqoop 抽取进入 EMR,通过 Spark 任务进行数据对比修正,然后将修正数据和切片数据存入 HBase。
右边的 Kappa 部分,也是我们交给用户书写 Flink 的部分。需要注意一下,Flink 流处理和 Flink 批处理的代码是一样的。在实时流处理的过程中,Flink 它会直接消费 Kafka 的实时流数据,可以得到最低延迟。在离线批处理的过程中,它的数据则来自于 HBase 的重放。
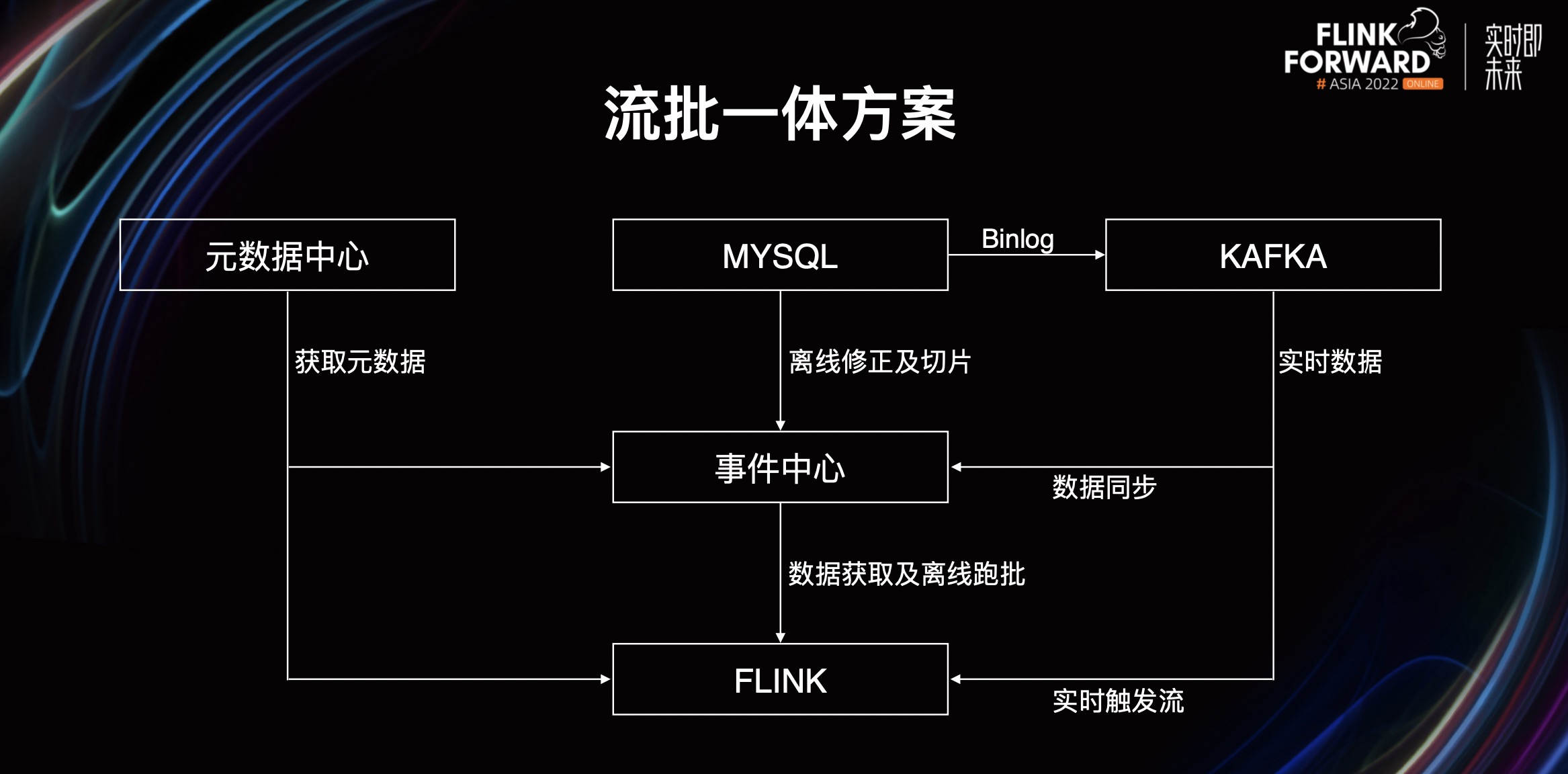
上图是流批一体方案的数据流。可以看到 MySQL 的 Binlog 进 Kafka,然后它的实时数据会通过数据同步进入事件中心,离线修正及切片也会每日同步进入事件中心。Flink 作业在实时触发过程中,通过 Kafka 来获取相关数据。在离线过程中,则通过事件中心获取相关数据,同时它也可以通过事件中心获取一些其他事件流的历史数据。最后由元数据中心进行统一的元数据服务。
三、数据的流批一体方案
实时运行时,我们可以获取当前时刻各数据源的流水数据及切片状态数据。在离线分析和回溯时,我们可以通过获取回溯时刻各数据源流水的数据以及切片状态数据。此时实时和离线获取的数据结构及数据内容是完全保持一致的。我们通过标准化的时序数据接入与获取,这样可以天然杜绝穿越问题。

我们用事件中心承载了整个数据存储方案。首先使用 Lambda 架构存储所有变化数据,实时写入,离线修正。由于我们存储的是所有变化数据,它的存储量会比较大,所以我们使用冷热混存与重加热机制来追求最佳性价比。然后我们仿造 Flink 的水印机制,在事件中心实现了一个特有的水印机制,确保当前值同步完成,从而可以以“取数”代替流 Join。
除此之外,我们还提供了消息转发机制。通过异步转同步支持触发消息接收及触发轮询式调用,并赋予该接口回溯能力。这样无论通过消息还是调用,我们就都可以支持,且使用模型的开发人员也无需再关心系统对接细节。

MySQL 的 Binlog 会同步进 Kafka;Kafka 的数据就会被直接使用;RabbitMQ 消息通过转发作业转发进 Kafka;消息转发服务的 API 请求也会转发成 Kafka。接着由一个 Flink 作业去消费这些 Kafka 数据,并将其存到 HBase 热存。
此时 MySQL 会有一个额外的离线链路,通过 Sqoop 抽取到 EMR,进行快照与修正,然后将数据存进 HBase 热存。HBase 热存通过 replica 机制将数据同步到 HBase 冷存。当访问到冷存数据时,会有一个重新加热的机制,把 HBase 冷存数据重新加热回热层。

从上图可以看到,HBase 热存里有四张表,其中第一张是主数据,下面三张是索引表,它用一个持续的结构进行存储。我们在 HBase 热存中仅存储 32 天内的数据,超过这个时间的数据需要通过冷存获取。
索引表里的第二张索引表(标记了 watermark 字样)就是我们的用于实现索引机制的表。

当一个 Flink 作业在实时触发的时候,它实际上是直接使用的 Kafka 流数据,只是我们通过元数据中心把相关的逻辑统一封装了。Flink 的使用者无需关心数据是来自 Kafka 还是 HBase,因为对他来说是一样的。
在回溯的时候会自动使用 HBase 热存,如果读到冷存数据,它也会自动触发一个重新加热的机制。除此之外,当你需要直接取其他数据流数据的时候,也可以直接在 HBase 中取数。

我们在实时流开发中经常比较头疼的就是多流 Join。这里我们以双流 Join 举个例子,多流 Join 是一样的,以此类推。
假设我们要对两个流进行 Join,也可以简单理解为两张表,通过某外键进行行关联。当任何一张表发生变更时,我们都需要至少触发一次最终完整 Join 后的记录。
我们将两个流分别记录为 A 和 B,并且假设 A 流先到。那么在打开事件中心水印机制的情况下,A 流触发时,A 流的当前事件已经被记录在事件中心中。此时分为两种情况:
- 在时间中心中可以取到 B 流的相关数据,那么说明 A 流当前事件记录进事件中心,到运行至读取 B 流相关数据的时间段内,B 流已经完成了事件中心的记录,此时的数据已经完整。
- 在事件中心中无法取到 B 流的相关数据,那么由于事件中心水印机制,说明此时 B 流相关事件尚未触发。而由于 A 流当前事件已经被写入事件中心,那么当 B 流相关事件被触发时,一定能获得 A 流的当前事件数据,此时数据也是完整的。
由此,通过事件中心水印机制,即可确保用“取数”取代流 Join 后至少会有一次拥有完整数据的计算。

转发机制主要是为了对一些传统系统进行兼容,它分为两种。第一种是触发消息接收式,比如外部系统发起一个请求,我们的消息转发系统接收到请求后,会把请求转发成一个 Kafka 消息,并且将消息存到事件中心中。
之后 Flink 作业接收到 Kafka 消息后会进行运算,并将结果发送到 RabbitMQ 等用户能够直接订阅的消息系统中,然后外部系统接收相关的消息结果进行后续的操作。

第二种是触发轮询式,外部系统会发起请求并轮询结果。这里需要注意一点,当处理时间小于单次请求超时时间的时候,轮询的动作就会退化为单次同步请求。这里和之前的方案是一样的,区别是 Flink 作业会将数据写入到一个 Kafka,然后由事件中心获取 Kafka 数据并进行存储,最后提供相关的服务。
通过这种方式我们还额外使我们的接口具备了数据回溯能力。
四、逻辑的流批一体方案

逻辑的流批一体是由 Flink 天生带来的,它可以使离线开发试运⾏与实时执⾏、离线回溯代码完全⼀致。另外,我们封装了实时流特有的概念,降低实时开发门槛。封装了复杂的触发逻辑和复杂的“取数”逻辑。
除此之外,我们可以提供自助式的开发上线,减少沟通环节,增加上线效率。最后我们额外提供了热更新的参数,并支持独立的参数变更流程。使模型策略人员和运营人员有更好的交互。

我们使用的 PyFlink,我们使用它是原因模型策略人员通常使用 Python 进行相关的逻辑开发。
从上图我们可以看到,整个代码被分为三个部分:触发、主逻辑、输出。触发部分我们可以引用一些已经封装好的触发逻辑,主逻辑部分我们也可以引用一些已经封装好取数,或者其他函数逻辑,输出部分我们也可以引用一些已经封装好的输出逻辑,同时我们也支持多路输出。
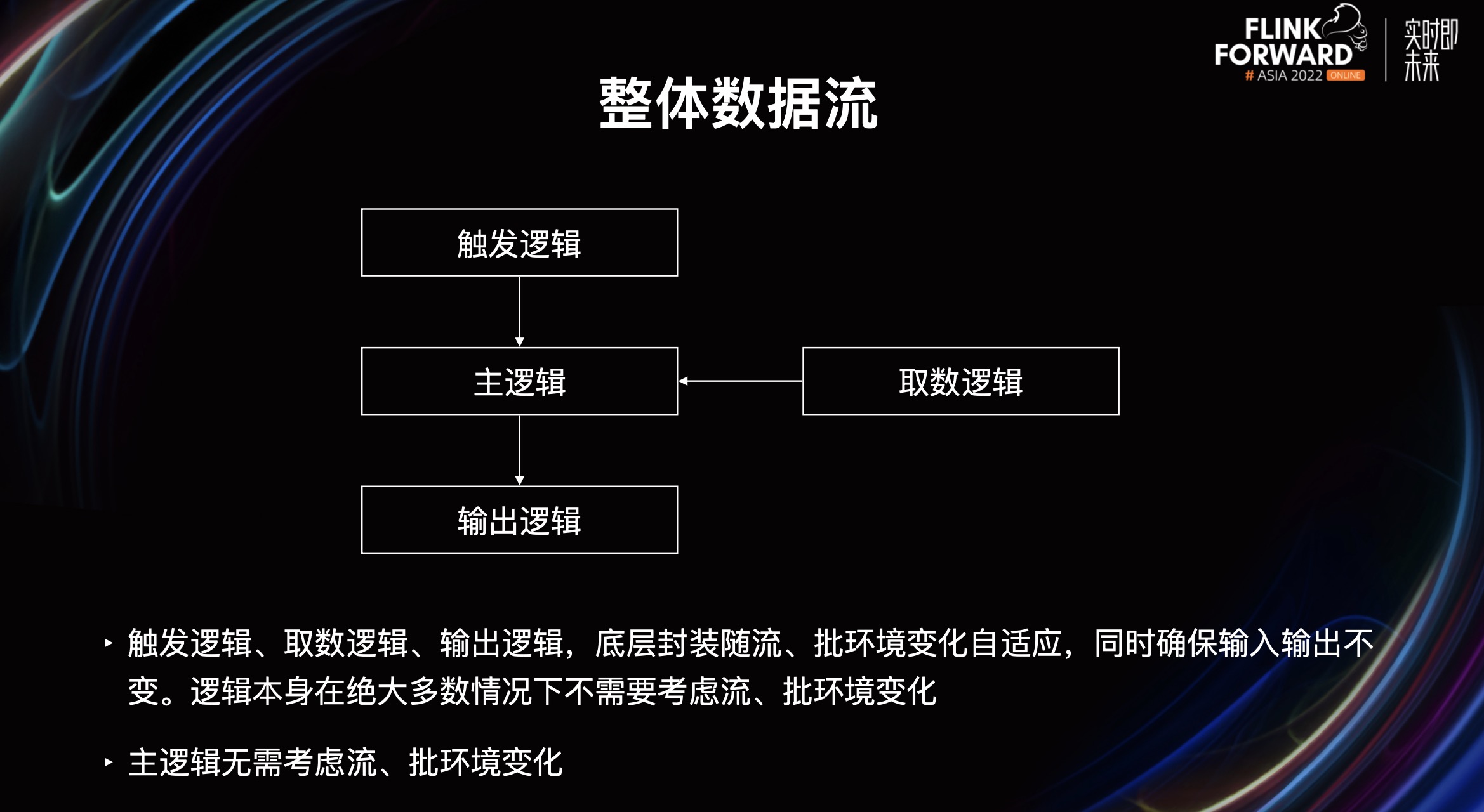
上图展示的是整体数据流,首先触发逻辑会触发到主逻辑,主逻辑可以引入一些取数逻辑,最后会有一个输出逻辑。模型策略人员主要开发的是主逻辑,对于触发逻辑、取数逻辑、输出逻辑一般直接选择就可以了。
触发逻辑、取数逻辑、输出逻辑,它的底层封装会随着流批环境自动变化,同时确保输入和输出不变。逻辑本身在绝大多数情况下不需要考虑流批环境的变化,当然在某些特殊情况也是需要考虑的。而由模型策略人员开发的主逻辑部分则完全无需考虑流批环境变化,已经被完全封装好了。
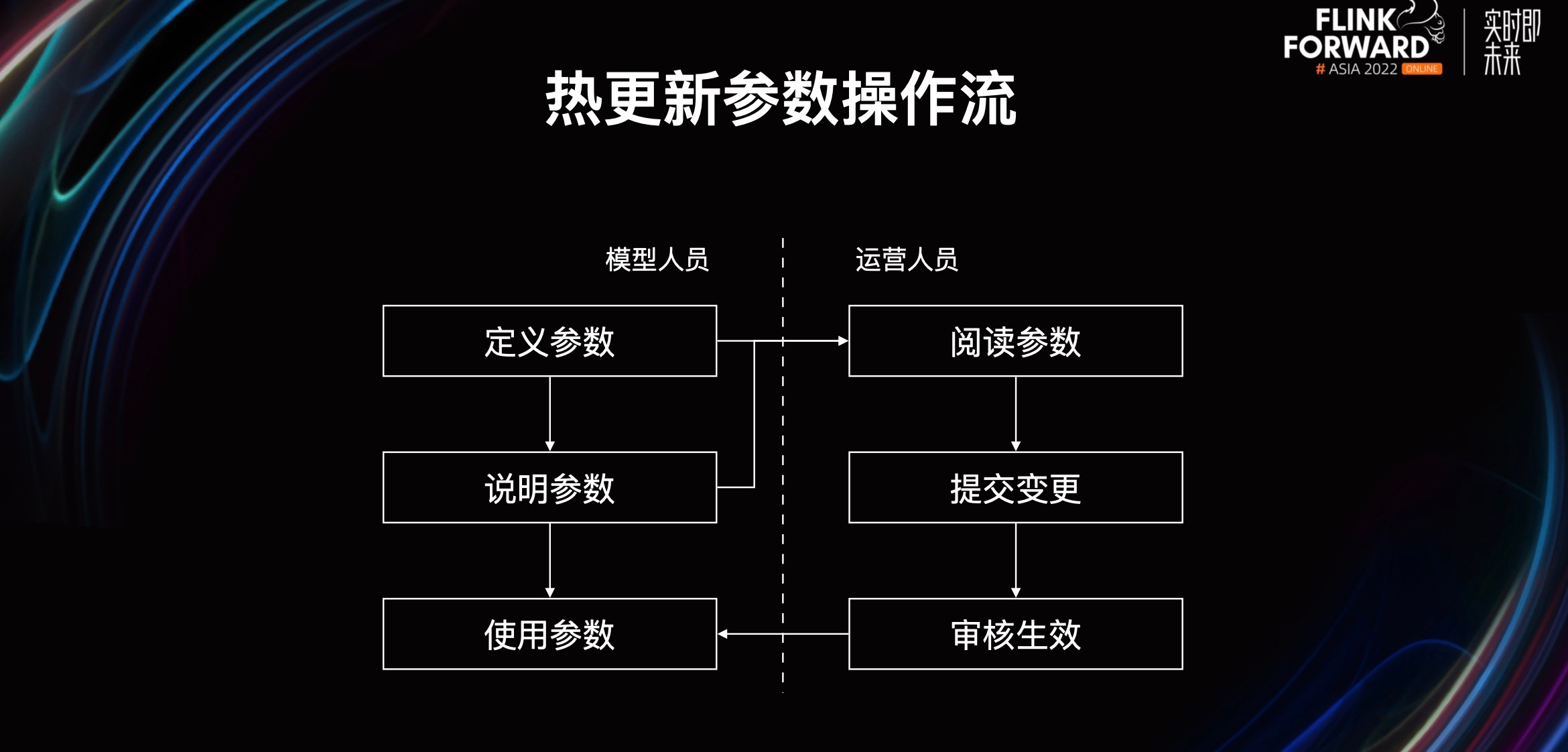
热更新参数操作流分为两个角色:模型人员、运营人员。模型人员需要定义一些参数,并对这些参数进行说明,最后在代码中使用这些参数。运营人员需要去阅读参数的定义及参数的说明,然后进行相关变更的提交,最后通过审核进行生效。

我们按照分工和职能可以把整个系统分为三类人:
- 第一类是平台管理人员,他可以规整化并接入数据源;封装触发事件和“取数”逻辑;封装输出链路;封装并标准化场景。
- 第二类是模型人员,他可以选择触发事件、“取数”逻辑或直接使用标准化场景;选择一种或多种输出链路,输出运行结果。
- 第三类是运营人员,他可以观测模型运行结果;热更新模型参数。

站在模型策略人员的视角,典型的使用流程为如下操作:
- 第一步,需要选择一个触发流。
- 第二步,编写取数和预处理逻辑,也可以直接引入已经发布的取数或处理逻辑代码。
- 第三步,设置回溯逻辑并试运行,它可以按照样本表或时间切片进行回溯。
- 第四步,获取试运行结果,在分析平台中进一步分析与训练。
- 第五步,训练完成后发布模型,在作业中选择训练完成的模型。如果有需要,可以设置热更新参数及初始化相关参数。
- 第六步,发布作业,上线完成。
整个过程自助化非常高,可以减少很多沟通环节,快速训练、测试、发布模型。
五、数据一致性方案

实时流处理是一种异步处理方式,如果没有特殊需求一致性级别一般均为最终一致,但也可以通过一些额外方案来实现更高的一致性要求。分为以下四种方案:
- 最终一致:经过一段时间后能访问到更新的数据。整个流批一体方案默认保证最终一致。
- 触发流强一致(可延迟):它会保障触发流重的当前数据及早于当前的数据,在对触发流的取数过程中能取到。使用水印方案,当水印不满足时进行延迟。
- 取数强一致(可延迟):它会保障取数时早于用户提出时间要求的数据均能取到。使用水印方案,水印不满足时进行延迟。
- 取数强一致(无延迟):它会保障取数时早于用户提出时间要求的数据均能取到。当水印不满足时,它会直接从数据源增量补足。这里需要注意,增量取数会对数据源带来压力,要谨慎。

从上图我们可以看到,数据源触发了一个事件。由于它是一个异步系统,它会同时触发事件中心的存储作业和 Flink 消费的作业,所以当 Flink 消费的时候它有可能读不到事件中心当次事件的存储。事件中心没有完成写入就取不到数据,只有当事件中心完成写入的时候,才能取到最新的数据。

整体的时序和最终一致时序一样,区别在于 Flink 作业会进行事件中心水印机制的判断。如果不满足,它会进行延迟,直至满足相关的水印机制,就能获得最新的数据了。

取数强一致(可延迟)时序和最终一致时序也很类似,只是因为是取数流,所以它触发的 Kafka 和数据的 Kafka 是分开的。他的处理方案也是通过事件中心的水印机制,如果不满足就延迟直至满足,才能获取相关的数据。

前半部分和最终一致时序一样,但它在水印机制不满足的时候,就不再等待和延迟了,它会直接从数据源增量获取数据。显然,这种情况会对数据源造成压力,因此这种情况要谨慎。

在绝大多数场景,比如反欺诈、经营等对时效性并没有那么敏感的场景下,最终一致已经足够满足需要了,这也是我们实践中绝大多数情况使用的方式。
触发流强制一致(可延迟)是在对触发流统计误差要求很高的场景下使用。一般除了状态初始化外,我们也可以直接使用 Flink 自带的 state 机制来解决。
取数强一致(可延迟),它在对取数流统计误差要求很高的情况下使用。比如一些金融场景下,需要对全历史订单进行统计,那么就要求不能有误差,所以就需要用这种方式。
取数强一致(无延迟),由于会对数据源造成外的压力,这个方案只会在极少情况下使用。一般对时效性要求有如此高的时候,我们会优先考虑直接在线上应用处理。只有在线上应用无法处理的大数据量情况下才会考虑使用,一般极少使用。
六、流、批、调用一体方案

在模型策略上线后,我们必然要通过某种方式才能为线上系统提供服务。对不同的调用方式进行封装,我们可以在模型策略代码不修改的前提下,自适应各类不同场景的调用需求。主要分为以下四种:
- 第一种,特征存储服务方案。在 Flink 作业进行预运算以后,将运算结果写入特征存储服务平台,并通过该数据服务平台对外服务。
- 第二种,接口触发--轮询方案。它调用并轮询事件中心的消息转发接口,直到 Flink 作业返回运算结果。
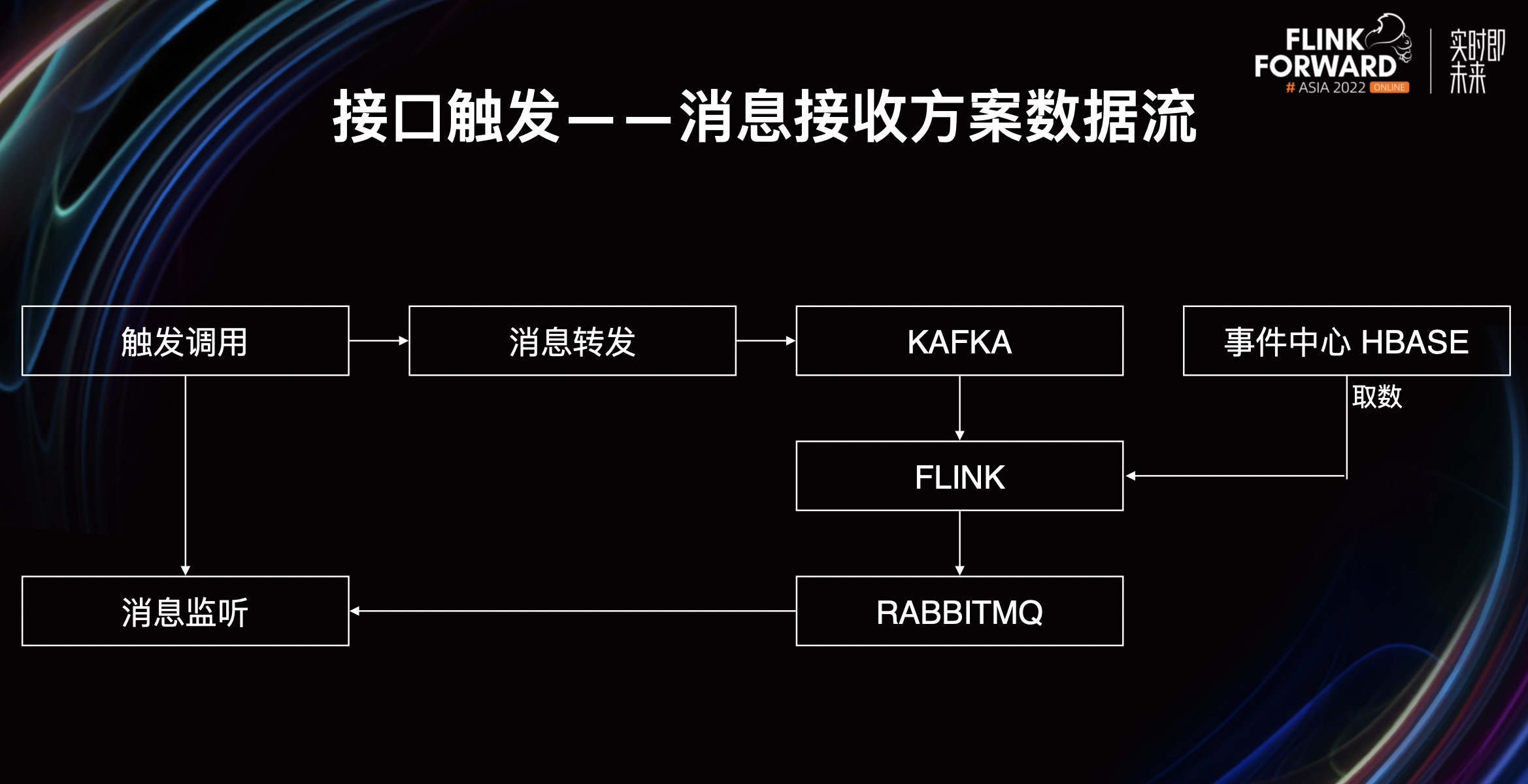
- 第三种,接口触发--消息接收方案。它调用事件中心的消息转发接口来触发 Flink 作业运算,接收 Flink 作业返回的运算结果消息。
- 第四种,直接消息接受方案。线上系统无需关心触发,直接使用 Flink 作业返回的运算结果消息进行相关的运算。
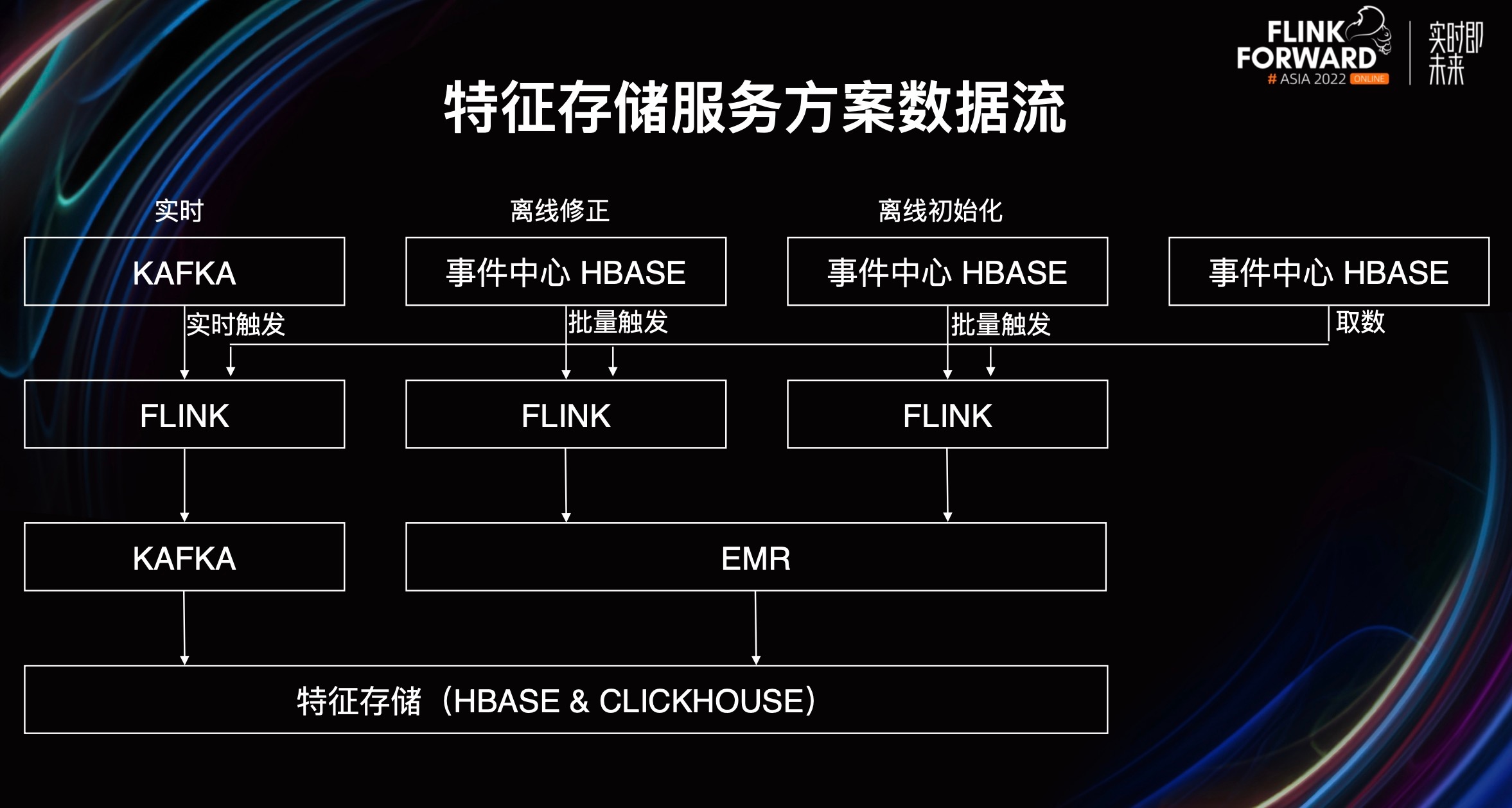
从上图中在中间可以看到有三个 Flink,这三个 Flink 节点的代码是一样的,不需要修改,就是同一个作业。
整个数据流竖着看我们分成三条线。
第一条是实时,它就是 Kafka 的实时触发。触发 Flink 代码,然后运算结果会存 Kafka,最后存储到特征存储。
第二条和第三条都是离线,分别是离线初始化和离线修正。它们都是通过事件中心 HBase 来批量触发 Flink 任务,然后将结果写入 EMR,EMR 将数据同步进特征存储。
除此之外,如果对其他流提出一些需求,不管是实时还是离线,都可以从事件中心的 HBase 中进行取数。

我们需要注意一下,特征存储服务方案因为是一个预运算的异步方案,所以它的时效性和一致性需求也是最终一致。从上图我们可以看到,Kafka 触发以后会进行运算,然后写入到特征存储。如果外部调用太早,Flink 作业还没完成运算以及写入特征存储,就无法获取更新的数据,只有等到 Flink 作业运行完毕,并写入了特征存储系统,才能得到更新的数据。

这是通过一种异步转同步的方式将一个异步的 Flink 作业变成同步的请求。外部系统通过请求触发来调用我们的消息转发机制,消息转发机制会将消息转发到 Kafka 触发 Flink 的运算,Flink 运算完毕会将数据写进写进 Kafka,最后写进事件中心 HBase。
需要注意一下,如果整个过程没有超过单次请求的超时时间,那么此时触发轮询会退化为单次触发的同步调用,即变成一个简单的同步调用。如果超过了,就需要触发方进行轮询,通过事件查询查询事件中心的 HBase 是否有结果。

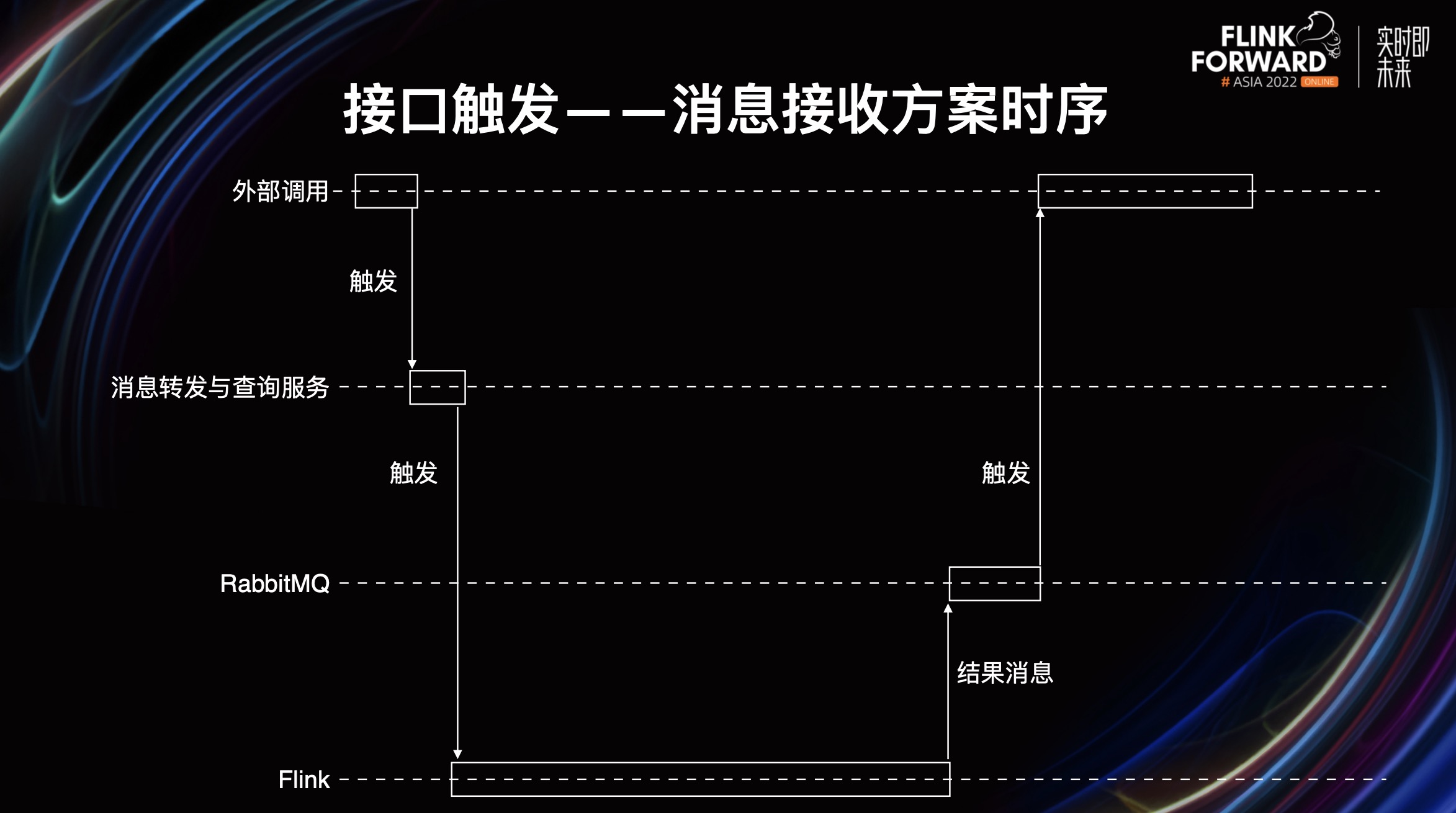
从上图可以看到,外部调用会触发消息转发与查询服务,然后消息转发与查询服务会触发一个事件,Flink 会消费这个事件并进行相关计算,最后写进事件中心。同时消息转发与查询服务会不断尝试从事件中心获取运算结果,如果一直获取失败,第一次的调用就会超时,需要你第二次轮询,直到轮询到计算结果。这是一种异步转同步的方式。
前面是一样的,消息转发转发到 Flink 作业,但 Flink 就不再写进 Kafka 了,会直接写到外部系统能够使用的消息系统中。然后外部系统进行相应的事件监听,获取运行结果。
整个数据流就会变得比前面的时序简单很多,它就是一个非常传统的异步调用时序,只是中间会有一个消息转发服务会帮你把同步请求转发成消息来触发计算。
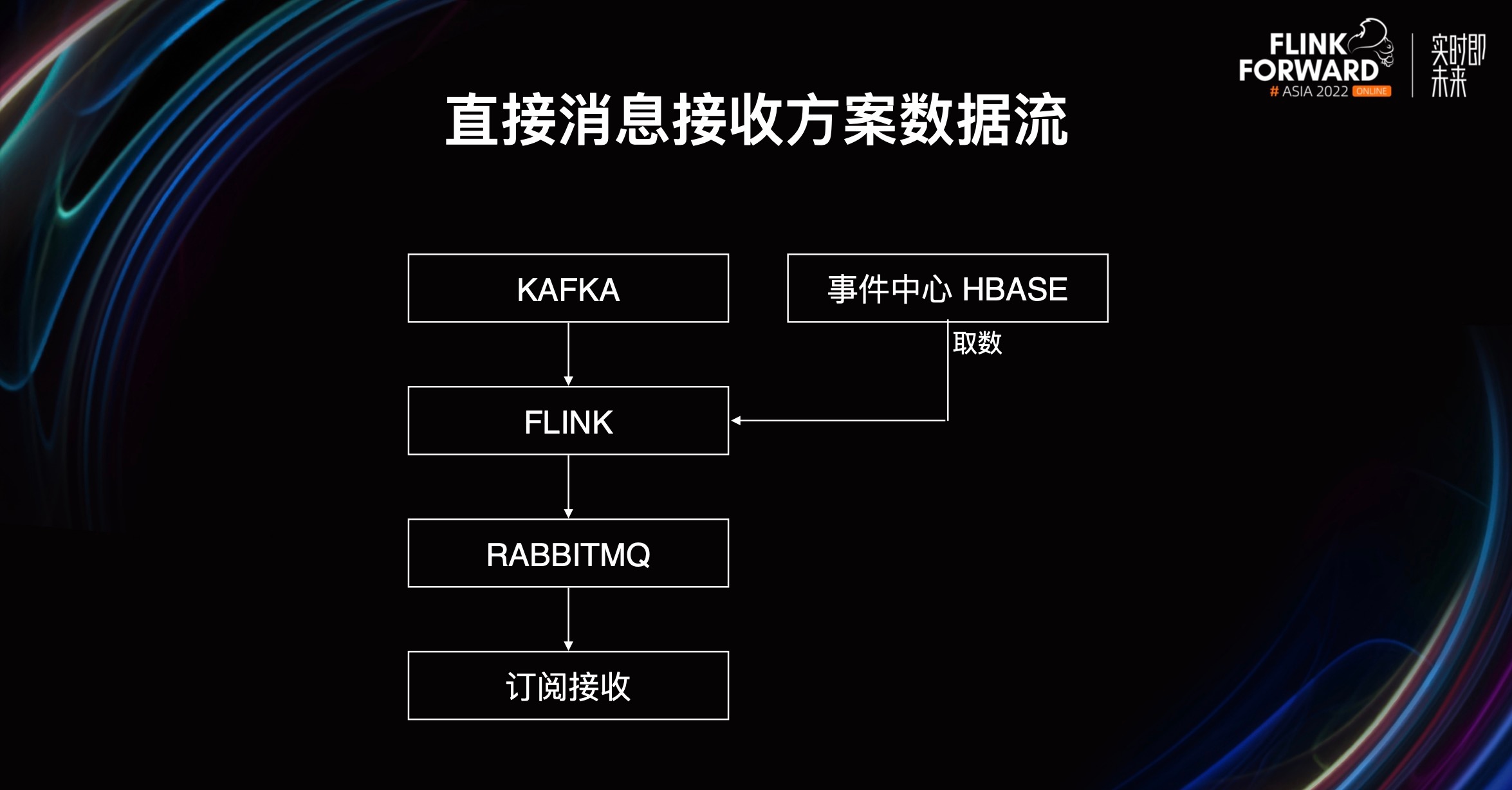
这个就比较传统,外部系统无需关心触发流,触发流会由作业自行使用。Flink 作业接收触发并运算完毕后,将结果直接写到 RabbitMQ 等外部系统能够接收的消息队列,然后外部系统会直接消费消息并进行订阅接收,进行后续操作。
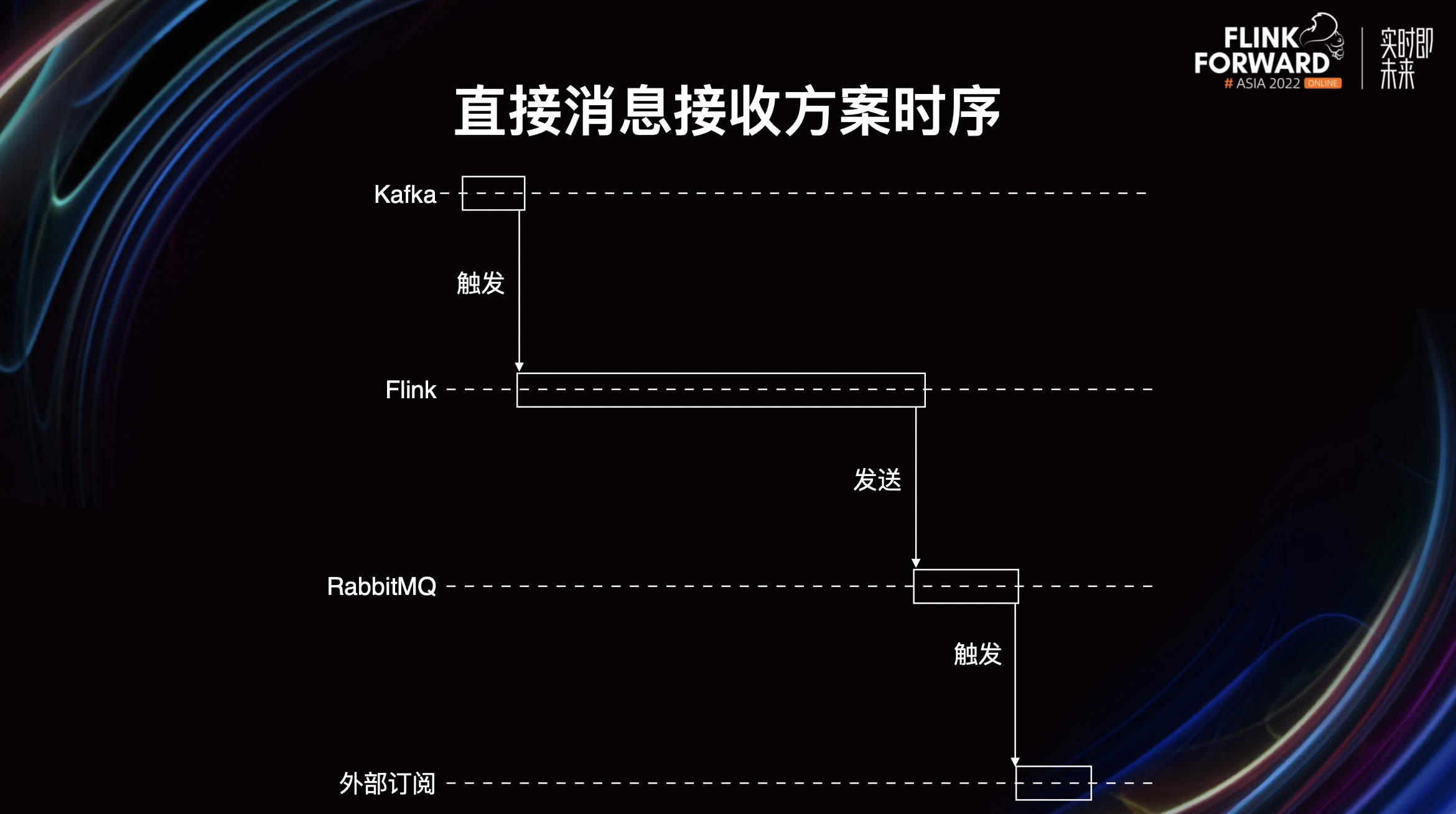
这是一个非常典型的异步时序,全程异步,数据流从 Kafka 到 Flink 到 RabbitMQ 最后到外部订阅。

流、批、调用一体化提供的服务方案:
- 特征存储服务方案。通过特征存储服务提供持久化的特征存储,提供 API 点查及特征圈选服务。
- 接口触发—轮询方案。通过事件中心的消息转发与消息查询服务,将同步调用转换成异步消息处理,最后对外封装的时候就是一个简单的同步请求。
- 接口触发—消息接收方案。通过事件中心的消息转发服务,与接口触发—轮询方案的区别是最终提供的是消息,将消息发回相关的应用系统。
- 直接消息接收方案。支持复杂的事件触发,提供事件消息服务。
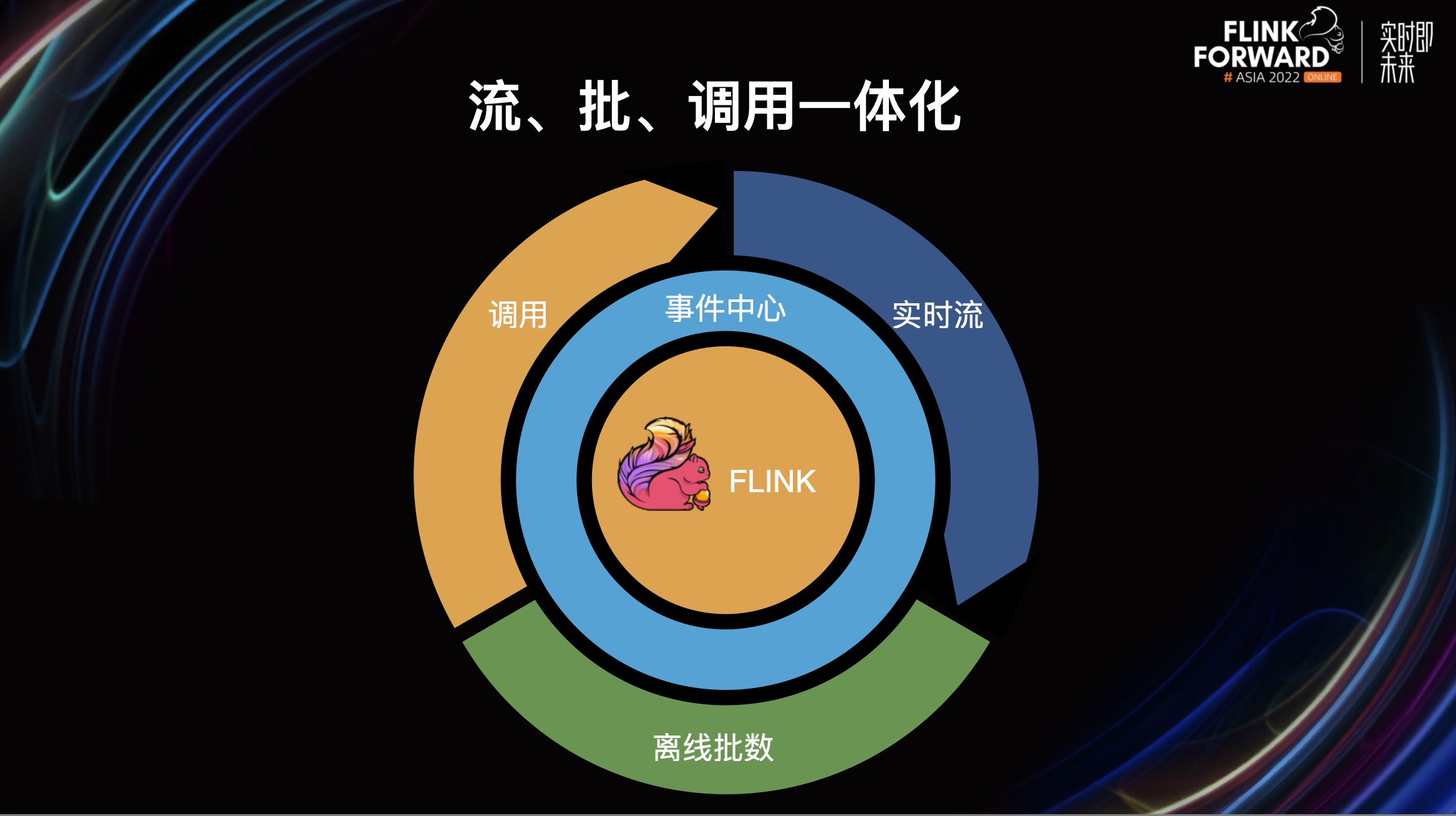
我们以 Flink 作为核心引擎,以事件中心作为中间层以及存储,使调用、实时流、离线跑批都可以用相同的方式来进行处理。这样模型、策略无论被如何使用,都无需修改即可执行。