R-FCN,全称为“Region-based fully convolutional network”,该文章的发表时间可以参见下图:
R-FCN关注点并不是检测精度,而是检测速度。可以参见下面的图来理解这个问题:
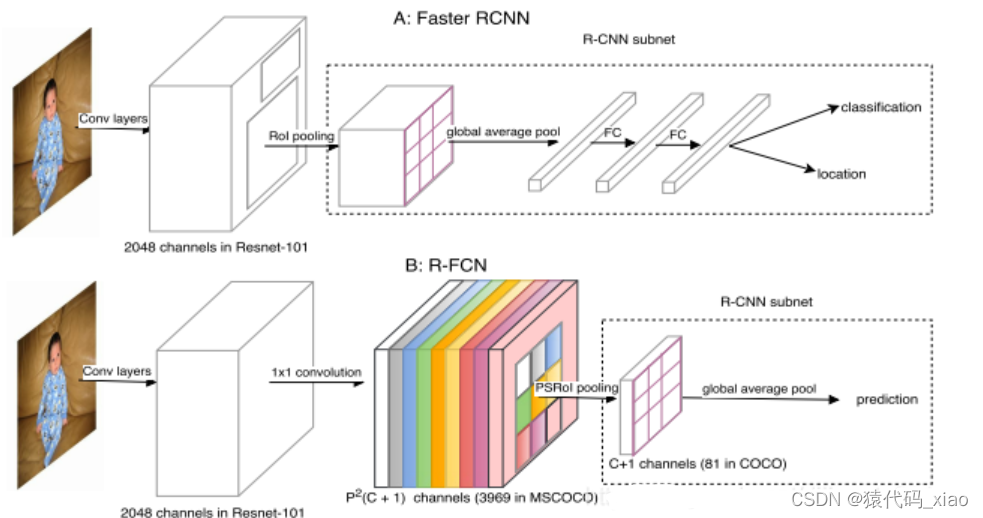
由图可见,Faster RCNN对每一个Roi区域,分别经过一个subnetwork,这个subnetwork包含了一次global average pool操作,两次FC操作。因为每一个Roi的计算并没有共享,所以这种网络结构是比较耗时的。
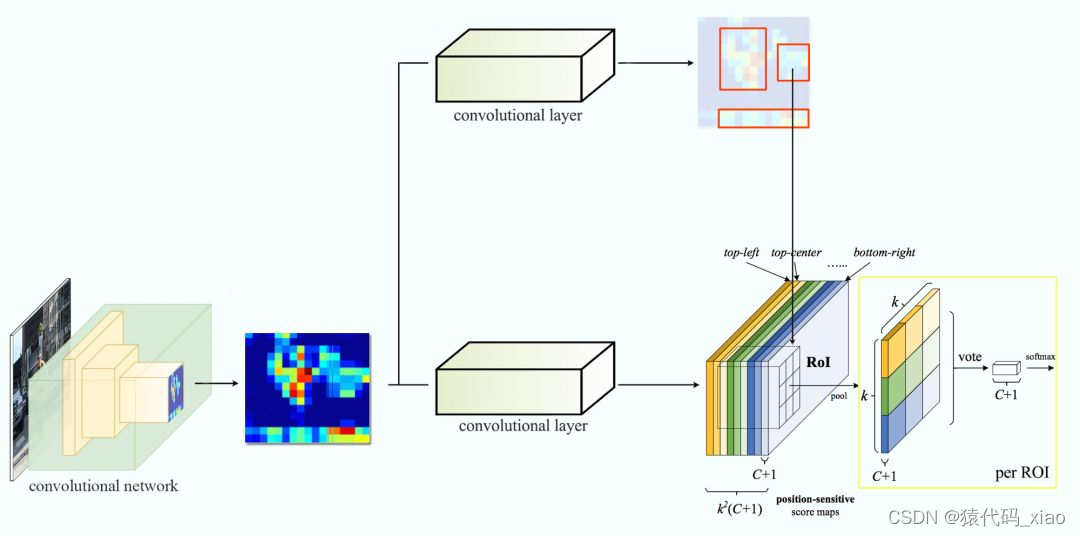
为了解决这个问题,比较直接的想法是,把这两层FC操作放到Roi pooling前面,这样的话,每一个Roi区域只需要经过global average pool操作即可,节约了计算量。但是,这样做带来了另外一个问题,由于global average pool操作得到的特征缺失了很多的空间域信息,如果直接用来回归坐标会导致定位精度不准。为了保留更多的空间域位置信息,R-FCN中提出了“position-sensitive score map”的概念。
假设我们只有一个特征图用来检测右眼。那么我们可以使用它定位人脸吗?应该可以。因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。

如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。
现在我们回顾一下所有问题。在 Faster R-CNN 中,检测器使用了多个全连接层进行预测。如果有 2000 个 ROI,那么成本非常高。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
class_scores, box = detector(patch) # Expensive!
class_probabilities = softmax(class_scores)```
R-FCN 通过减少每个 ROI 所需的工作量实现加速。上面基于区域的特征图与 ROI 是独立的,可以在每个 ROI 之外单独计算。剩下的工作就比较简单了,因此 R-FCN 的速度比 Faster R-CNN 快。
```c
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
score_maps = compute_score_map(feature_maps)
for ROI in ROIs
V = region_roi_pool(score_maps, ROI)
class_scores, box = average(V) # Much simpler!
class_probabilities = softmax(class_scores)
现在我们来看一下 5 × 5 的特征图 M,内部包含一个蓝色方块。我们将方块平均分成 3 × 3 个区域。现在,我们在 M 中创建了一个新的特征图,来检测方块的左上角(TL)。这个新的特征图如下图(右)所示。只有黄色的网格单元 [2, 2] 处于激活状态。
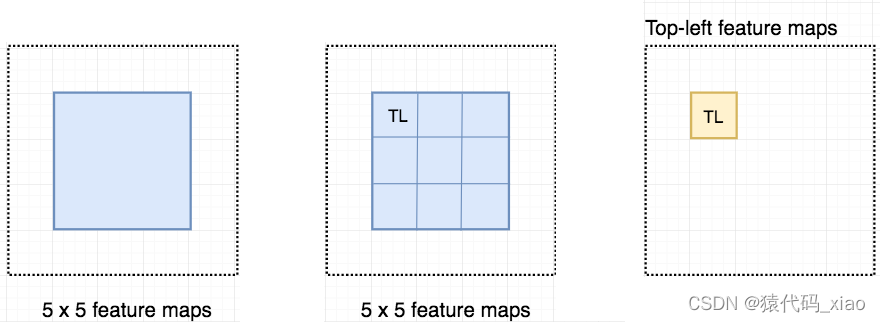
我们将方块分成 9 个部分,由此创建了 9 个特征图,每个用来检测对应的目标区域。这些特征图叫作位置敏感得分图(position-sensitive score map),因为每个图检测目标的子区域(计算其得分)。

下图中红色虚线矩形是建议的 ROI。我们将其分割成 3 × 3 个区域,并询问每个区域包含目标对应部分的概率是多少。例如,左上角 ROI 区域包含左眼的概率。我们将结果存储成 3 × 3 vote 数组,如下图(右)所示。例如,vote_array[0][0] 包含左上角区域是否包含目标对应部分的得分。
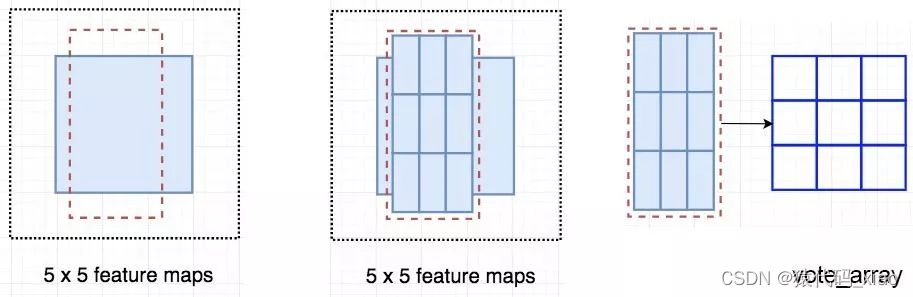
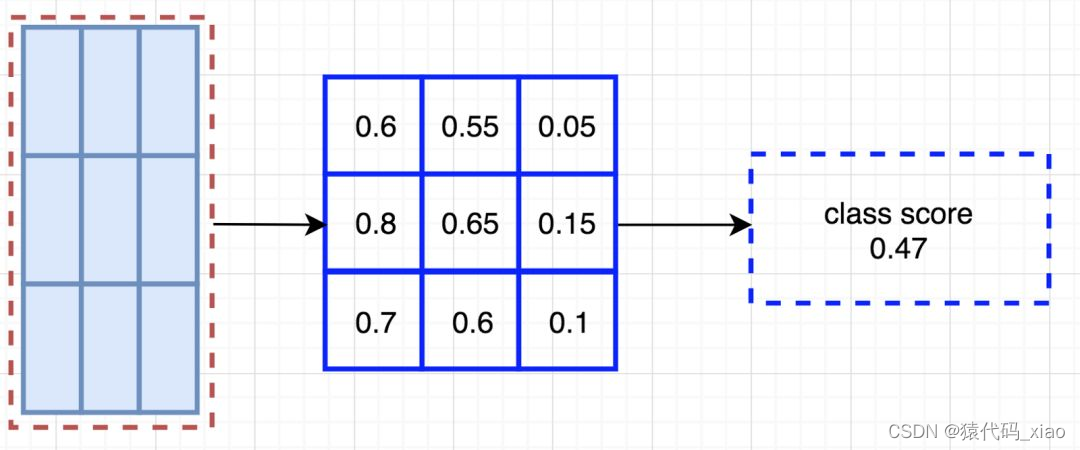
将得分图和 ROI 映射到 vote 数组的过程叫作位置敏感 ROI 池化(position-sensitive ROI-pool)。该过程与前面讨论过的 ROI 池化非常接近。
![将 ROI 的一部分叠加到对应的得分图上,计算 V[i][j]。](https://img-blog.csdnimg.cn/91587c4b58654945b65df3bee80bea95.png)
在计算出位置敏感 ROI 池化的所有值后,类别得分是其所有元素得分的平均值。
假如我们有 C 个类别要检测。我们将其扩展为 C + 1 个类别,这样就为背景(非目标)增加了一个新的类别。每个类别有 3 × 3 个得分图,因此一共有 (C+1) × 3 × 3 个得分图。使用每个类别的得分图可以预测出该类别的类别得分。然后我们对这些得分应用 softmax 函数,计算出每个类别的概率。
以下是数据流图,在我们的案例中,k=3。