文章目录
原子操作(atomic包)
原子操作
代码中的加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作由内置的标准库sync/atomic提供。
atomic包
http://doc.golang.ltd/
| 方法 | 解释 |
|---|---|
func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr*uint32) (val uint32) func LoadUint64(addr*uint64) (val uint64) func LoadUintptr(addr*uintptr) (val uintptr) func LoadPointer(addr*unsafe.Pointer) (val unsafe.Pointer) |
读取操作 |
func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) |
写入操作 |
func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
修改操作 |
func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
交换操作 |
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
比较并交换操作 |
示例
我们填写一个示例来比较下互斥锁和原子操作的性能。
var x int64
var l sync.Mutex
var wg sync.WaitGroup
// 普通版加函数
func add() {
// x = x + 1
x++ // 等价于上面的操作
wg.Done()
}
// 互斥锁版加函数
func mutexAdd() {
l.Lock()
x++
l.Unlock()
wg.Done()
}
// 原子操作版加函数
func atomicAdd() {
atomic.AddInt64(&x, 1)
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10000; i++ {
wg.Add(1)
// go add() // 普通版add函数 不是并发安全的
// go mutexAdd() // 加锁版add函数 是并发安全的,但是加锁性能开销大
go atomicAdd() // 原子操作版add函数 是并发安全,性能优于加锁版
}
wg.Wait()
end := time.Now()
fmt.Println(x)
fmt.Println(end.Sub(start))
}
atomic包提供了底层的原子级内存操作,对于同步算法的实现很有用。这些函数必须谨慎地保证正确使用。除了某些特殊的底层应用,使用通道或者sync包的函数/类型实现同步更好。
并发安全性
多协程并发修改同一块内存,产生资源竞争。go run或go build时添加-race参数检查资源竞争情况。
n++不是原子操作,并发执行时会存在脏写。n++分为3步:取出n,加1,结果赋给n。测试时需要开1000个并发协程才能观察到脏写。
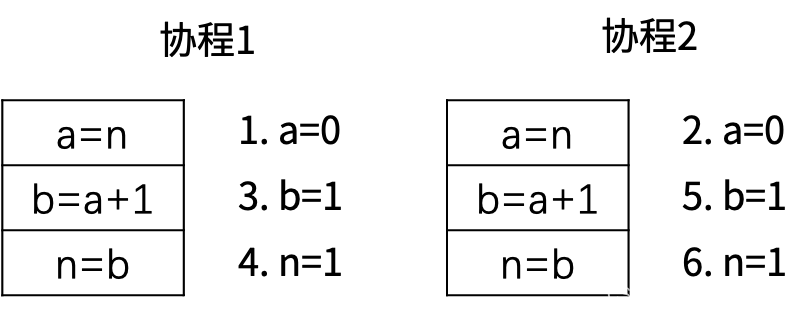
func atomic.AddInt32(addr *int32, delta int32) (new int32)
func atomic.LoadInt32(addr *int32) (val int32)
把n++封装成原子操作,解除资源竞争,避免脏写。
var lock sync.RWMutex //声明读写锁,无需初始化
lock.Lock() lock.Unlock() //加写锁和释放写锁
lock.RLock() lock.RUnlock() //加读锁和释放读锁
任意时刻只可以加一把写锁,且不能加读锁。没加写锁时,可以同时加多把读锁,读锁加上之后不能再加写锁。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var n int32 = 0
var lock sync.RWMutex
func inc1() {
n++ //n++不是原子操作,它分为3步:取出n,加1,结果赋给n
}
func inc2() {
atomic.AddInt32(&n, 1) //封装成原子操作
}
func inc3() {
lock.Lock() //加写锁
n++ //任一时刻,只有一个协程能进入临界区域
lock.Unlock() //释放写锁
}
func main() {
const P = 1000 //开大量协程才能把脏写问题测出来
wg := sync.WaitGroup{
}
wg.Add(P)
for i := 0; i < P; i++ {
go func() {
defer wg.Done()
inc1()
}()
}
wg.Wait()
fmt.Printf("finally n=%d\n", n) //多运行几次,n经常不等于1000
fmt.Println("===========================")
n = 0 //重置n
wg = sync.WaitGroup{
}
wg.Add(P)
for i := 0; i < P; i++ {
go func() {
defer wg.Done()
inc2()
}()
}
wg.Wait()
fmt.Printf("finally n=%d\n", atomic.LoadInt32(&n))
fmt.Println("===========================")
n = 0 //重置n
wg = sync.WaitGroup{
}
wg.Add(P)
for i := 0; i < P; i++ {
go func() {
defer wg.Done()
inc3()
}()
}
wg.Wait()
lock.RLock() //加读锁。当写锁被其他协程持有时,加读锁操作将被阻塞;否则,如果其他协程持有读锁,加读锁操作不会被阻塞
fmt.Printf("finally n=%d\n", n)
lock.RUnlock() //释放读锁
fmt.Println("===========================")
}
数组、slice、struct允许并发修改(可能会脏写),并发修改map有时会发生panic。如果需要并发修改map请使用sync.Map。
package main
import (
"fmt"
"sync"
)
type Student struct {
Name string
Age int32
}
var arr = [10]int{
}
var m = sync.Map{
}
func main() {
wg := sync.WaitGroup{
}
wg.Add(2)
go func() {
//写偶数位
defer wg.Done()
for i := 0; i < len(arr); i += 2 {
arr[i] = 0
}
}()
go func() {
//写奇数位
defer wg.Done()
for i := 1; i < len(arr); i += 2 {
arr[i] = 1
}
}()
wg.Wait()
fmt.Println(arr) //输出[0 1 0 1 0 1 0 1 0 1]
fmt.Println("=======================")
wg.Add(2)
var stu Student
go func() {
defer wg.Done()
stu.Name = "Fred"
}()
go func() {
defer wg.Done()
stu.Age = 20
}()
wg.Wait()
fmt.Printf("%s %d\n", stu.Name, stu.Age)//Fred 20
fmt.Println("=======================")
wg.Add(2)
go func() {
defer wg.Done()
m.Store("k1", "v1")// 往map写数据
}()
go func() {
defer wg.Done()
m.Store("k1", "v2")
}()
wg.Wait()
fmt.Println(m.Load("k1"))//从map读数据--》v1 true
}