文章目录
并发介绍
进程和线程
A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
C.一个进程可以创建和撤销多个线程;同一个进程中的多个线程之间可以并发执行。
并发和并行
A. 多线程程序在一个核的cpu上运行,就是并发。
B. 多线程程序在多个核的cpu上运行,就是并行。
并发
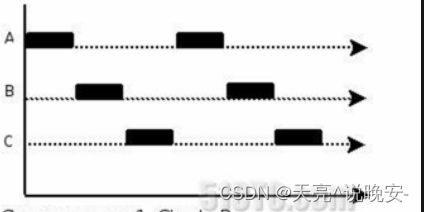
并行

并发编程
并发模型
任何语言的并行,到操作系统层面,都是内核线程的并行。同一个进程内的多个线程共享系统资源,进程的创建、销毁、切换比线程大很多。从进程到线程再到协程, 其实是一个不断共享, 不断减少切换成本的过程。

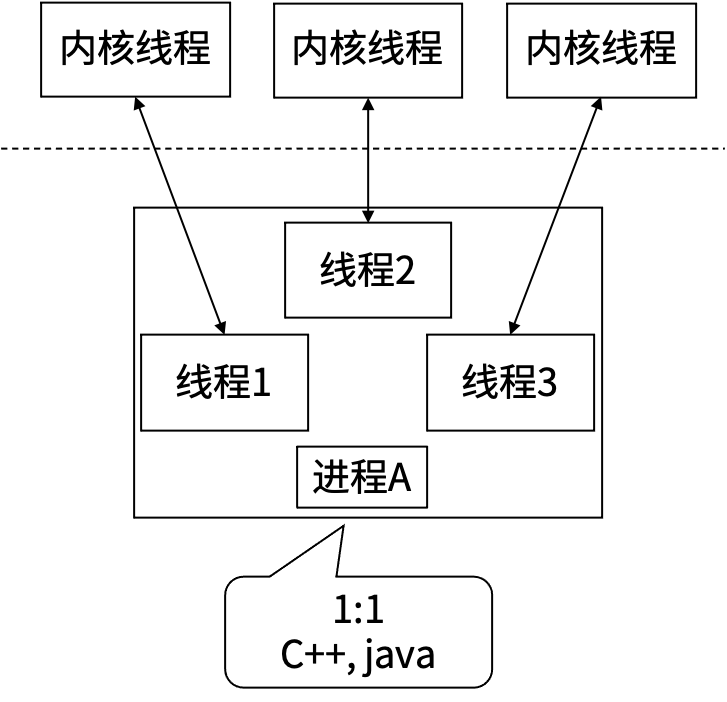
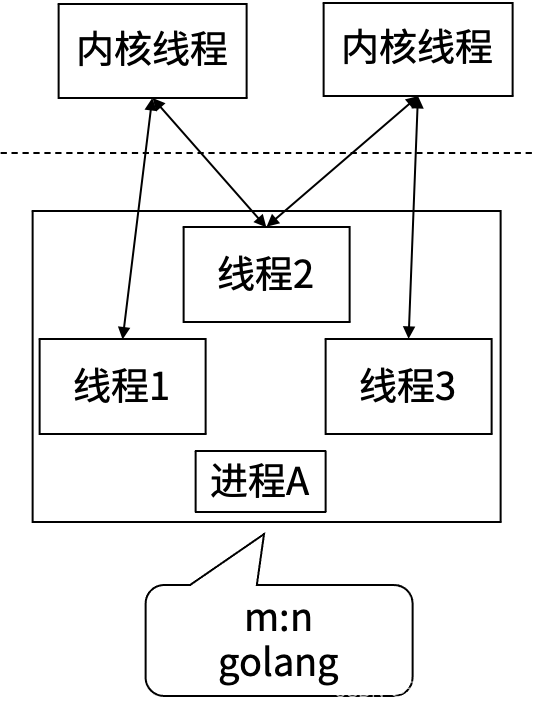
| 协程 | 线程 | |
|---|---|---|
| 创建数量 | 轻松创建上百万个协程而不会导致系统资源衰竭 | 通常最多不能超过1万个 |
| 内存占用 | 初始分配4k堆栈,随着程序的执行自动增长删除 | 创建线程时必须指定堆栈且是固定的,通常以M为单位 |
| 切换成本 | 协程切换只需保存三个寄存器,耗时约200纳秒 | 线程切换需要保存几十个寄存器,耗时约1000纳秒 |
| 调度方式 | 非抢占式,由Go runtime主动交出控制权(对于开发者而言是抢占式) | 在时间片用完后,由 CPU 中断任务强行将其调度走,这时必须保存很多信息 |
| 创建销毁 | goroutine因为是由Go runtime负责管理的,创建和销毁的消耗非常小,是用户级的 | 创建和销毁开销巨大,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池 |
查看逻辑核心数
fmt.Println(runtime.NumCPU())
Go语言的MPG并发模型
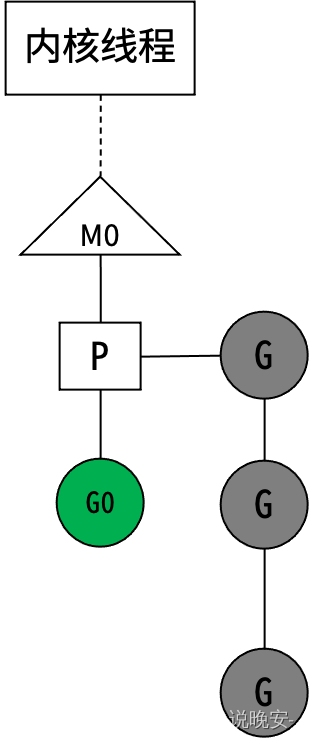
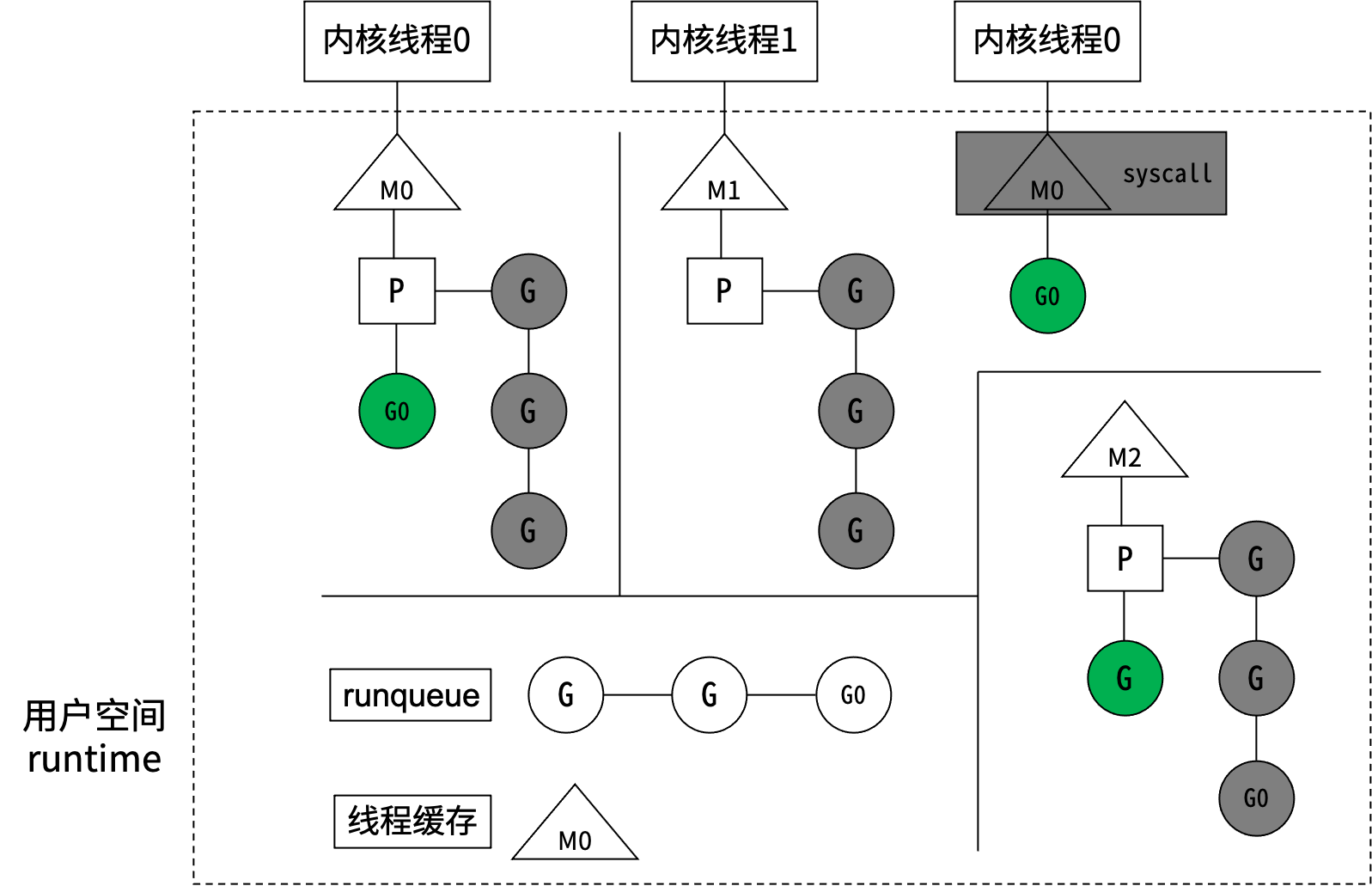
M(Machine)对应一个内核线程。P(Processor)虚拟处理器,代表M所需的上下文环境,是处理用户级代码逻辑的处理器。P的数量由环境变量中的GOMAXPROCS决定,默认情况下就是核数。G(Goroutine)本质上是轻量级的线程,G0正在执行,其他G在等待。M和内核线程的对应关系是确定的。G0阻塞(如系统调用)时,P与G0、M0解绑,P被挂到其他M上,然后继续执行G队列。G0解除阻塞后,如果有空闲的P,就绑定M0并执行G0;否则G0进入全局可运行队列(runqueue)。P会周期性扫描全局runqueue,使上面的G得到执行;如果全局runqueue为空,就从其他P的等待队列里偷一半G过来。
Channel的同步与异步。查看以前的Channel文章
Goroutine的使用
启动协程的两种常见方式:
func Add(a, b int) int {
fmt.Println("Add")
return a + b
}
go Add(2, 4)
go func(a, b int) int {
fmt.Println("add")
return a + b
}(2, 4)
优雅地等子协程结束:
wg := sync.WaitGroup{
}
wg.Add(10) //加10
for i := 0; i < 10; i++ {
go func(a, b int) {
//开N个子协程
defer wg.Done() //减1
//do something
}(i, i+1)
}
wg.Wait() //等待减为0
父协程结束后,子协程并不会结束。main协程结束后,所有协程都会结束。
向协程内传递变量
package main
import (
"fmt"
"time"
)
func main() {
arr := []int{
1, 2, 3, 4}
for _, v := range arr {
go func() {
fmt.Printf("%d\t", v) //用的是协程外面的全局变量v。输出4 4 4 4
}()
}
time.Sleep(time.Duration(1) * time.Second)
fmt.Println()
for _, v := range arr {
go func(value int) {
fmt.Printf("%d\t", value) //输出1 4 2 3
}(v) //把v的副本传到协程内部
}
time.Sleep(time.Duration(1) * time.Second)
fmt.Println()
}
有时候需要确保在高并发的场景下有些事情只执行一次,比如加载配置文件、关闭管道等。
var resource map[string]string
var loadResourceOnce sync.Once func LoadResource() {
loadResourceOnce.Do(func() {
resource["1"] = "A"
})
}
单例模式
type Singleton struct {
}
var singleton *Singleton
var singletonOnce sync.Once
func GetSingletonInstance() *Singleton {
singletonOnce.Do(func() {
singleton = &Singleton{
}
})
return singleton
}
var oc sync.Once
var a int = 5
func main() {
go func() {
oc.Do(func() {
a++
})
}()
go func() {
oc.Do(func() {
a++
})
}()
time.Sleep(1 * time.Second)
fmt.Println(a) //6
}
何时会发生panic:
- 运行时错误会导致panic,比如数组越界、除0。
- 程序主动调用panic(error)。
panic会执行什么:
- 逆序执行当前goroutine的defer链(recover从这里介入)。
- 打印错误信息和调用堆栈。
- 调用exit(2)结束整个进程。
关于defer
- defer在函数退出前被调用,注意不是在代码的return语句之前执行,因为return语句不是原子操作。
- 如果发生panic,则之后注册的defer不会执行。
- defer服从先进后出原则,即一个函数里如果注册了多个defer,则按注册的逆序执行。
- defer后面可以跟一个匿名函数。
func goo(x int) int {
fmt.Printf("x=%d\n", x)
return x
}
func foo(a, b int, p bool) int {
c := a*3 + 9
//defer是先进后出,即逆序执行
defer fmt.Println("first defer")
d := c + 5
defer fmt.Println("second defer")
e := d / b //如果发生panic,则后面的defer不会执行
if p {
panic(errors.New("my error")) //主动panic
}
defer fmt.Println("third defer")
return goo(e) //defer是在函数临退出前执行,不是在代码的return语句之前执行,因为return语句不是原子操作
}
// foo(1,5,false)-->
x=3
third defer
second defer
first defer
// foo(1,5,true)-->
second defer
first defer
panic: my error
recover会阻断panic的执行。
func soo(a, b int) {
defer func() {
//recover必须在defer中才能生效
if err := recover(); err != nil {
fmt.Printf("soo函数中发生了panic:%s\n", err)
}
}()
panic(errors.New("my error"))
}
//soo函数中发生了panic:my error