引言
最近几个月,CV界真是跟“一切”杠上了。先是Meta在4月5日发布了Segment Anything,可以为任何图像中的任何物体提供Mask。随后又涌现出大量的二创“一切”,例如SAM3D(在3D场景中分割一切)、SAMM(分割一切医学模型)、SegGPT(分割上下文中的一切)、Grounded Segment Anything(检测一切/生成一切)等等,真的是一个大模型统治一个领域了。而在6月8日,谷歌又提出了“跟踪一切”模型OmniMotion,直接对视频中每个像素进行准确、完整的运动估计。本以为这就完了,结果前两天Meta又新开源了CoTracker:跟踪任意长视频中的任意多个点,并且可以随时添加新的点进行跟踪!性能直接超越了谷歌的OmniMotion,不禁感叹大佬们的世界真是太卷了。今天笔者就带领小伙伴们欣赏一下这一神作!注意,这里说的跟踪一切,并不是目标跟踪,而是针对具体的点跟踪。对目标跟踪感兴趣的小伙伴可以关注Track Anything这篇文章。
效果展示
先来看一下具体效果!

真的很丝滑。几乎各种动态目标上的点都可以稳定跟踪!下面再来看看从标准网格上采样的点能否稳定跟踪:

相对于其他SOTA方案可以说很强了。而且也完全不惧遮挡:


总之,效果非常好。代码已经开源了,感兴趣的小伙伴赶快试试吧。下面我们来看看具体的文章信息。
摘要
用于视频运动预测的方法要么使用光流联合估计给定视频帧中所有点的瞬时运动,要么独立跟踪整个视频中单个点的运动。即使对于能够通过遮挡跟踪点的强大的深度学习方法,后者也是如此。单独的跟踪点忽略了点与点之间可能存在的强相关性,例如,由于它们属于同一个物理对象,可能会损害性能。在本文中,我们提出了CoTracker,一种在整个视频中联合跟踪多个点的架构。这种架构结合了来自光流和跟踪文献中的几种思想,形成一种新的、灵活的和强大的设计。它基于一个Transformer网络,通过专门的注意力层对不同时间点的相关性进行建模。Transformer迭代更新多个轨迹的估计值。它可以以滑动窗口的方式应用于非常长的视频,为此我们设计了一个unrolled learning环。它可以从一个点联合跟踪到几个点,并支持随时添加新的点进行跟踪。其结果是一个灵活而强大的跟踪算法,在几乎所有的基准测试中都优于最先进的方法。
算法解析
目前主流的运动跟踪方法主要有两类:一个是光流法,即直接估计视频帧中所有点的瞬时速度,但是很难估计长期运动(尤其是遇到遮挡和相机帧率低的时候)。另一个是跟踪法,即选择有限点直接在连续时间上进行跟踪,但是没有利用同一物体上不同点的相互作用关系。而CoTracker就同时利用了两种方法的思想:使用Transformer来建模同一物体上点的相关性,并且使用滑动窗口来跟踪超长视频序列!CoTracker的输入是视频和可变数量的轨迹起始位置,输出是整条轨迹。注意,网络的输入可以是视频序列中的任意位置和任意时间!整篇论文其实没有特别多的数学推导,但是文章是思想很巧妙。CoTracker的具体原理如下。首先假设点是静止的来初始化点坐标P,然后使用CNN来提取图像特征Q,为了节省显存,图像特征为原图的1/32大小,同时还会加上一个标记v表示目标是否被遮挡。之后,输入token(P,v,Q)就被馈送到Transformer中进行相关性建模,得到输出token(P’,Q’)表示更新后的位置和图像特征。
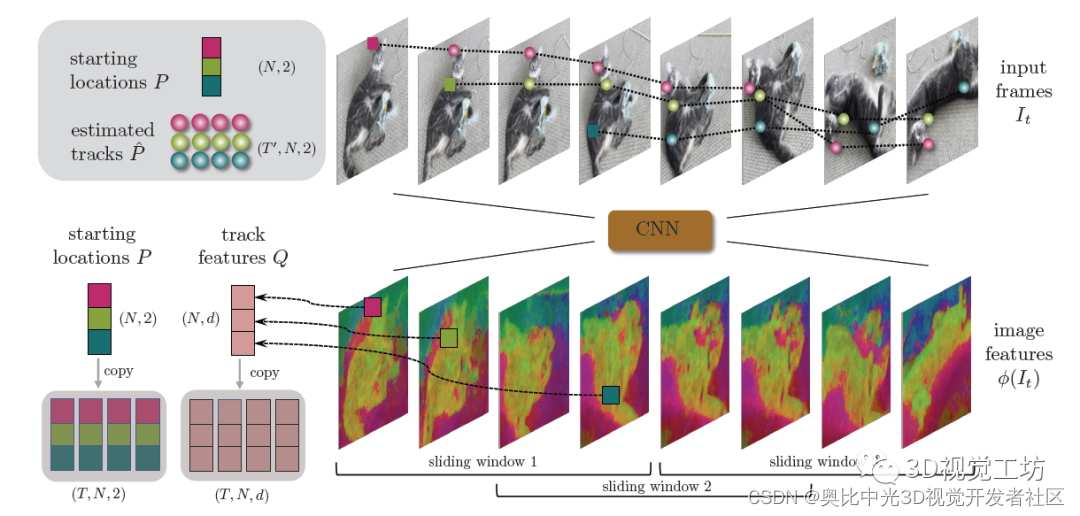
CoTracker的亮点在于,它设计了滑动窗口和循环迭代来进行长视频的跟踪。对于长度超过Transformer所支持的最大长度T的视频序列,会使用滑动窗口进行建模。滑动窗口的长度为J=⌈2T′/T-1⌉,并且对于每个滑动窗口,会进行M次迭代。也就是说总共有JM次迭代运算。对于每一次迭代,都会对点的位置P和图像特征Q进行更新。需要注意的是,这里的标记v并不是通过Transformer来更新的,而是在M次迭代结束以后根据计算结果更新的。还有一个unrolled learning是啥意思呢?这里主要说的是针对半重叠窗口的学习方式。由于这种学习方式不会导致计算成本的大幅增加,因此理论上CoTracker可以处理任意长度的视频序列。此外,unrolled learning可以跟踪后出现在视频中的点!
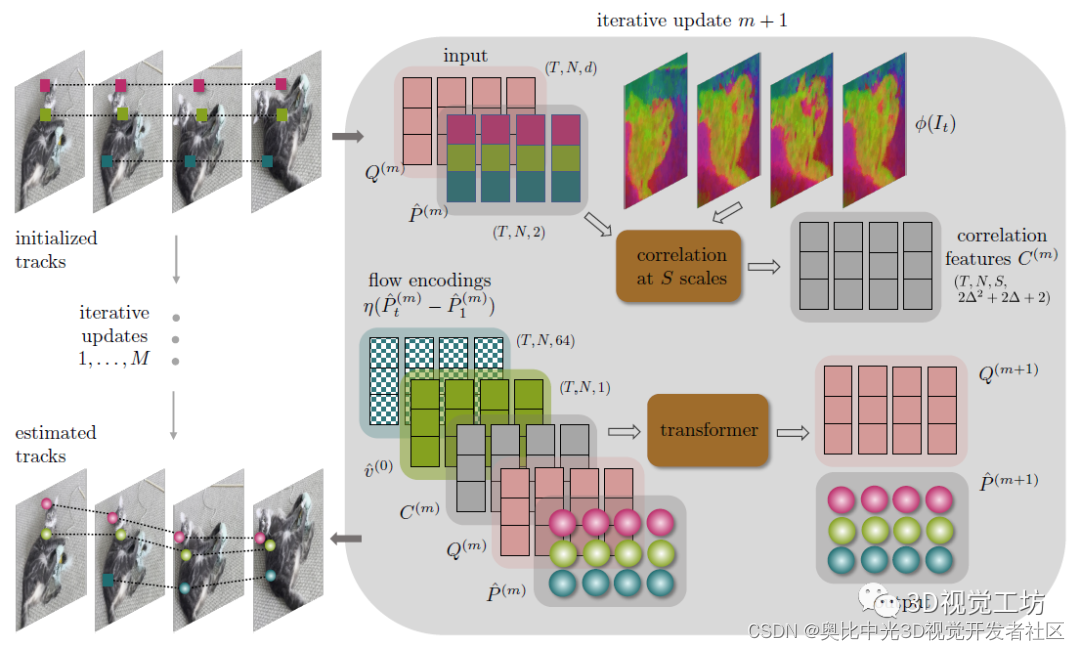
CoTracker还使用了大量的trick,比如对于网络的输入和输出使用两个线性层,这样计算复杂度就从O(N2T2)降低到了O(N2+T2)。这里的N代表跟踪的总点数,T代表视频序列的长度。
实验结果
CoTracker的训练在TAP-Vid-Kubric综合数据集上进行,测试在TAP-Vid-DAVIS、TAP-Vid-Kinetics、BADJA、FastCapture四个包含轨迹真值的数据集上进行。训练使用了11000个预生成的24帧视频序列,每个序列包含2000个跟踪点。而在具体的训练过程中,主要是从前景对象上采样了256个点。训练使用了32块V100(果然普通人还是玩不起)。CoTracker的实验很有意思,因为数据集上含有轨迹真值。因此为了验证轨迹是由CoTracker真实产生的,作者还在视频中选择了很多额外的点进行验证。CoTracker的结果也很棒!性能直接超越了谷歌6月发布的OmniMotion!
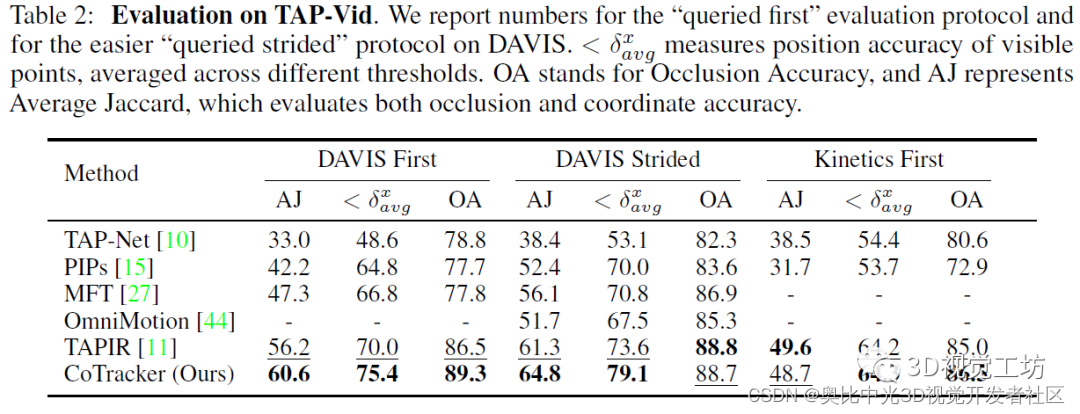
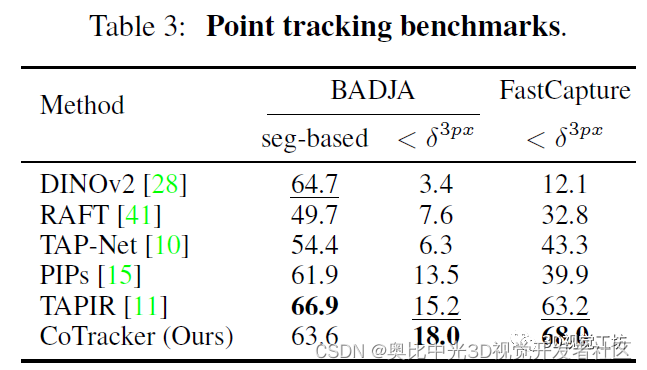
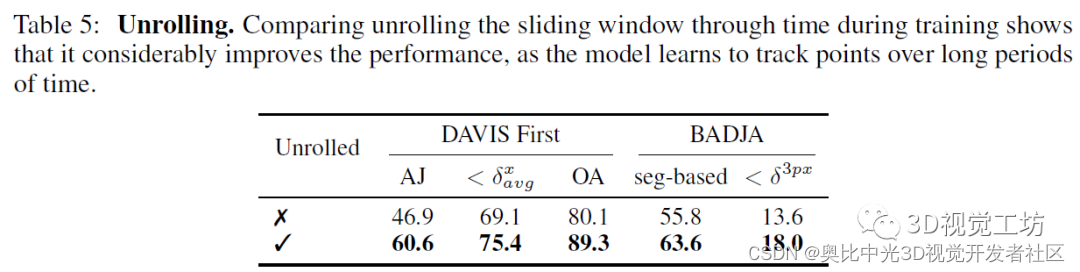
作者也做实验证明了unroll滑动窗口的重要性。由于评估过程中的benchmark都超级长,因此结果也证明了CoTracker确实可以很好得应用到长视频序列中!
总结
近期,全世界各大实验室都在疯狂发布大模型。Cotracker是一个很新颖的跟踪一切的AI模型,它主要的创新在于可以对同一物体上的不同点进行相关性建模,并且可以用于超长的视频序列。这一点是常规的光流方法和跟踪方法所替代不了的,所以对于有长时间跟踪需求的项目来说,Cotracker是一个很不错的选择。未来还会出现什么新奇的模型呢,匹配一切?对话一切?计算一切位姿?让我们拭目以待。