1.摘要
本文提出了一种新的端到端模型–双鉴别器条件生成对抗网络(DDcGAN),生成器的目标是基于专门设计的内容损失生成逼真的融合图像以欺骗两个鉴别器,而两个鉴别器的目标是区分融合图像与两个源图像之间的结构差异以及内容损失。DDcGAN约束下采样融合图像具有与红外图像相似的特性。这可以避免传统方法中通常发生的热辐射信息模糊或可见纹理细节丢失。
2.引言
基于深度学习的图像融合的不足之处:
- 缺乏groun truth
- 现有的融合方法一般采用神经网络进行特征提取和重构,而融合规则的设计仍然是手工的。因此,整个方法无法摆脱传统融合方法的局限性
- 即使源图像是多模态数据,以人工方式设计的融合规则也能强制提取相同的特征
- 基于传统的生成对抗网络(GAN)方法中,融合图像被训练为仅与源图像中的一个相似,从而导致包含在另一个源图像中的一些信息的丢失。
红外图像与可见光图像相比分辨率较低,细节模糊,难以通过升级硬件设备来提高红外图像的分辨率。用于融合多分辨率红外和可见光图像(例如,不同分辨率的图像),在融合之前对可见光图像进行下采样或对红外图像进行上采样的策略将不可避免地导致热辐射信息模糊或可见纹理细节丢失。因此,如何在不损失重要信息的前提下实现红外与可见光多分辨率图像的融合仍然是一个具有挑战性的课题。
为了解决上述问题,本文提出了一种基于双鉴别器条件生成对抗网络(DDcGAN)的融合方法.整个网络是一个端到端的模型,不需要设计融合规则。约束下采样融合图像具有与红外图像相似的特性,并且利用可训练的去卷积层来学习不同分辨率之间的映射
新贡献主要有:
- 优化了生成器网络结构,用
稠密连接的卷积网络代替了U型网络。该网络体系结构利用密集的连接,增强了特征图的传输能力,提高了特征图的利用率。该算法避免了大步长带来的损失和上采样操作带来的模糊,更大程度地保留了源图像中的信息,融合效果更加清晰 - 鉴别器 D v D_v Dv的输入不再是要鉴别的图像的梯度,而是图像本身。通过将概率空间从源图像的子空间扩展到整幅图像,融合后的图像与源图像具有更相似的特性。当网络试图最小化子空间中不同概率分布的散度时,会在源图像中引入一些额外的噪声。通过扩展概率空间,可以减轻这种影响。
- 对于生成器的输入,即,不同分辨率的源图像,而不是用两个上采样层对低分辨率源图像进行上采样,我们采用反卷积层来学习从低到高分辨率的映射。
- 我们增加了更详细的分析实验,涉及到生成器和两个鉴别器,以验证其子部分的效果
3.方法详解
DDcGAN的整个过程如图1所示,由于红外与可见光图像的分辨率不同,所以不失一般性的前提下,假设可见光图像的分辨率是红外图像的4 × 4倍。
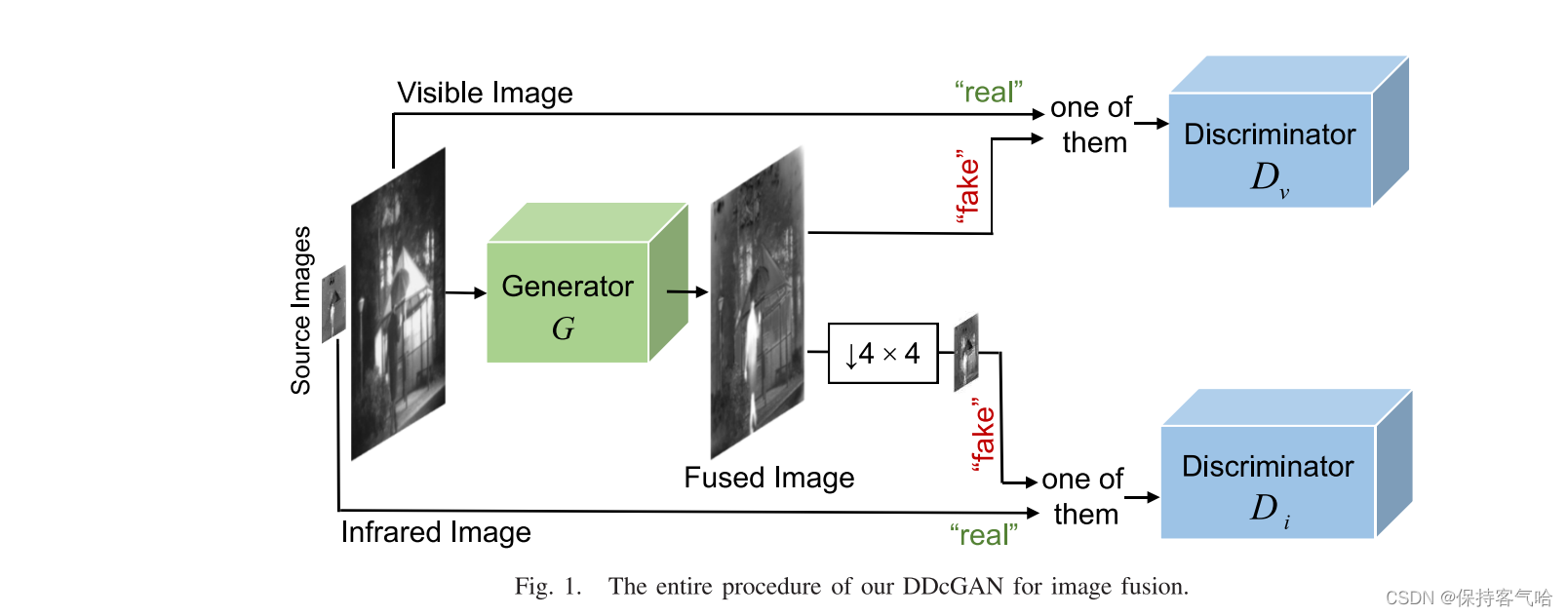
- 给定可见光图像 v v v和红外图像 i i i,我们的最终目标是学习以它们为条件的生成器 G G G,生成的图像为 G ( v , i ) G(v,i) G(v,i)
- 两个对抗式鉴别器 D v Dv Dv和 D i Di Di,它们分别产生一个标量,该标量估计输入是来自真实的数据而不是G的概率
- D v Dv Dv旨在区分
所生成的图像与可见光图像,而 D i Di Di被训练为区分原始低分辨率红外图像和下采样的所生成/融合的图像 - 由于平均池与最大池相比保留了低频信息,因此这里采用平均池进行下采样,并且热辐射信息主要以这种形式呈现
3.1 损失函数
由于GAN的训练不稳定,可能导致伪像和噪声或不可理解的结果,解决伪像和不可理解的结果的问题的一种可能的解决方案是引入内容损失以将一组约束包括到网络中。因此,生成器不仅被训练成欺骗鉴别器,而且被赋予约束生成的图像和源图像在内容上的相似性的任务。
因此,生成器的损失函数由对抗损失 L G a d v L^{adv}_G LGadv和内容损失 L c o n L_{con} Lcon组成,权重 λ λ λ控制权衡:
L G = L G a d v + λ L c o n L_G = L^{adv}_G + \lambda L_{con} LG=LGadv+λLcon
其中来自鉴别器的 L G a d v L^{adv}_G LGadv被定义为:
L G a d v = E [ l o g ( 1 − D v ( G ( v , i ) ) ) ] + E [ l o g ( 1 − D i ( ψ G ( v , i ) ) ) ] L^{adv}_G = E[log(1-D_v(G(v,i)))]+E[log(1-D_i(\psi G(v,i)))] LGadv=E[log(1−Dv(G(v,i)))]+E[log(1−Di(ψG(v,i)))]
由于红外图像中的热辐射信息是以像素强度为特征的,我们使用Frobenius范数来约束下采样融合图像具有与红外图像相似的像素强度。下采样操作可以显著地防止由压缩引起的纹理信息的丢失或由强制上采样引起的模糊。另一方面,可见光图像中的纹理细节主要以梯度变化为特征。因此,TV范数被应用于约束融合图像以展示与可见图像类似的梯度变化。利用权重 η η η来控制权衡,我们可以获得内容损失:
L c o n = E [ ∣ ∣ ψ G ( v , i ) − i ∣ ∣ F 2 + η ∣ ∣ G ( v , i ) − v ∣ ∣ T V ] L_{con} = E[||\psi G(v,i) - i||^2_F +\eta||G(v,i)-v||_{TV}] Lcon=E[∣∣ψG(v,i)−i∣∣F2+η∣∣G(v,i)−v∣∣TV]
其中ψ表示下采样算子,由于其保留了低频信息,因此通过两个平均池化层来实现。
训练鉴别器以在真实的数据和生成数据之间进行鉴别。鉴别器的对抗损失可以计算分布之间的JS散度,从而识别像素强度或纹理信息是否真实。
L D v = E [ − l o g D v ( v ) + E [ − l o g ( 1 − D v ( G ( v , i ) ) ) ] ] L_{D_v} = E[-logD_v(v)+E[-log(1-D_v(G(v,i)))] ] LDv=E[−logDv(v)+E[−log(1−Dv(G(v,i)))]]
3.2 生成器结构
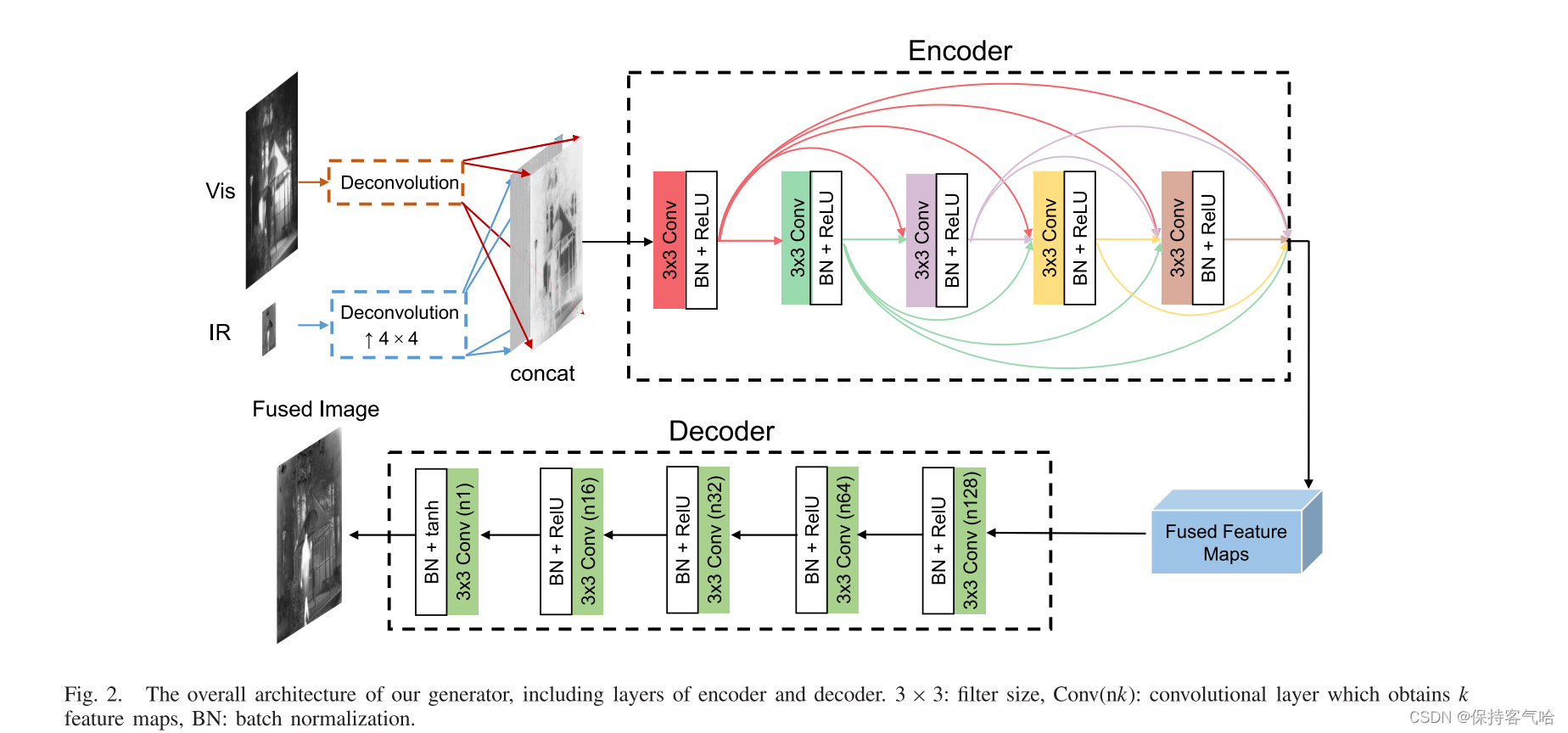
- 该生成器由2个反卷积层、一个编码器网络和一个相应的解码器网络组成
- 由于红外图像的分辨率较低,因此在编码前先进行映射,引入了一个反卷积层来学习从低到高分辨率的映射,反卷积层的输出是高分辨率特征图而不是上采样的红外图像
- 可见光图像通过一个独立的反卷积层,生成具有
相同分辨率的特征图 - 将两者经过反卷积生成的特征图进行concat作为Encoder的输入,特征提取和融合的过程都在Encoder中执行,并且产生融合的特征图作为输出,然后将这些图馈送到Decoder用于重构
3.2.1 Encoder
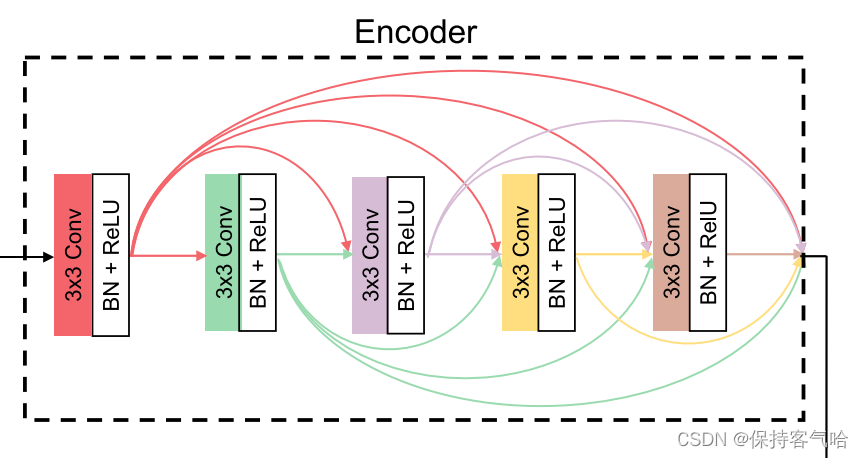
该编码器由5层卷积层组成,每层通过3 × 3滤波器可以得到48个特征图。为了缓解梯度消失、弥补特征损失和重用先前计算的特征,应用了DenseNet并以前馈方式在每层和所有层之间建立了short direct connections
3.2.2 Decoder
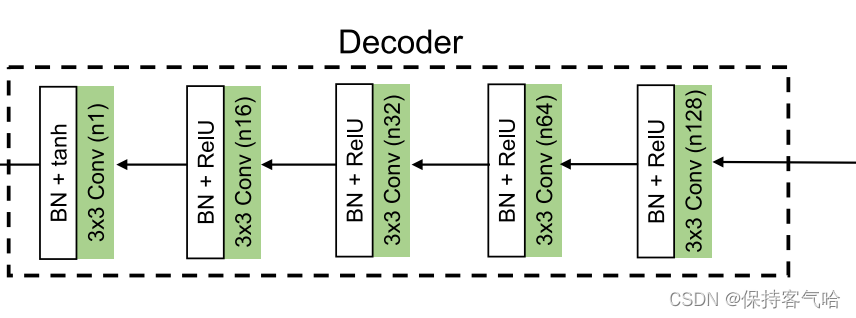
解码器是5层CNN,并且每层的设置如图2所示。所有卷积层的跨距被设置为1。为了避免梯度爆炸/消失并加快训练速度,应用了批量规格化。ReLU激活函数用于加速收敛
3.2 鉴别器架构
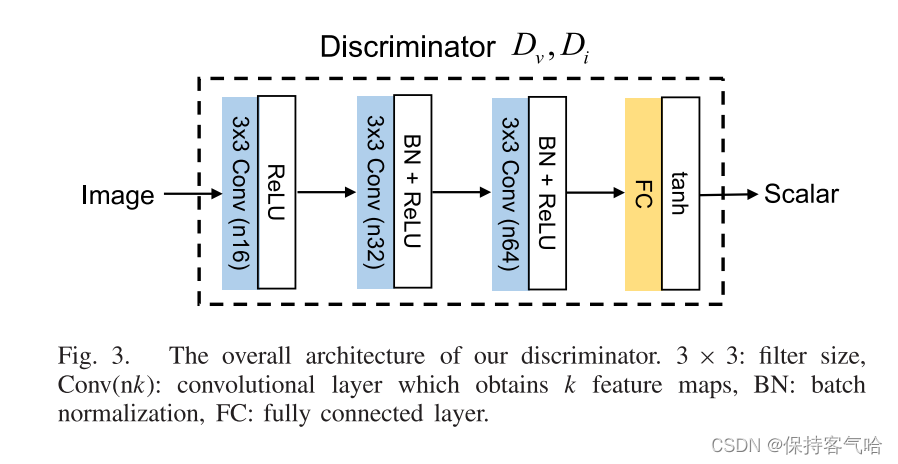
D v D_v Dv和 D i D_i Di旨在分别将所生成的图像与可见光图像和红外图像区分开,两者共享相同的架构
4.训练
数据集:TNO
选择36幅红外和可见光图像并裁剪成27000+个面片对作为训练数据集。假设可见光图像的分辨率为红外图像的4 × 4,可见光区域的大小为84×84,红外区域的大小为21 × 21。λ设为0.8,η设为3。学习速率被设置为0.002,具有指数衰减。batch size为24,epoch设置为1。
原则上不是每批轮流训练G、Dv和Di一次,而是如果不能区分从G生成的数据,则训练Dv或Di更多次,反之亦然。
在测试阶段,仅使用发生器生成融合图像。由于在我们的生成器中没有完全连接的层,所以输入可以是整个图像而不是图像块。
5.结论
在本文中,我们提出了一种新的基于深度学习的红外和可见光图像融合方法,通过构建一个双鉴别器条件GAN,命名为DDcGAN。该方法不需要ground truth融合图像进行训练,可以融合不同分辨率的图像,且不会引入热辐射信息模糊或可见纹理细节丢失。与其他7个国家的最先进的融合算法的六个指标的广泛比较表明,我们的DDcGAN不仅可以识别最有价值的信息,但也可以保持最大或接近最大量的信息源图像。此外,我们提出的DDcGAN应用于PET和MRI图像的融合,它也可以实现先进的性能相比,五个国家的最先进的算法。