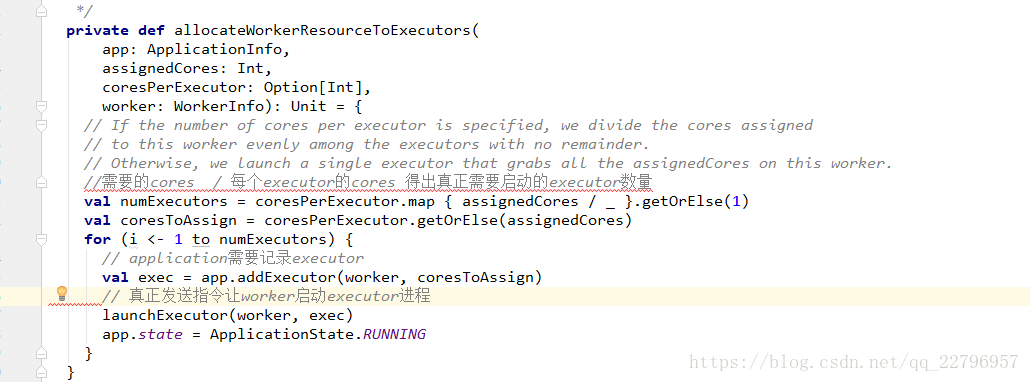
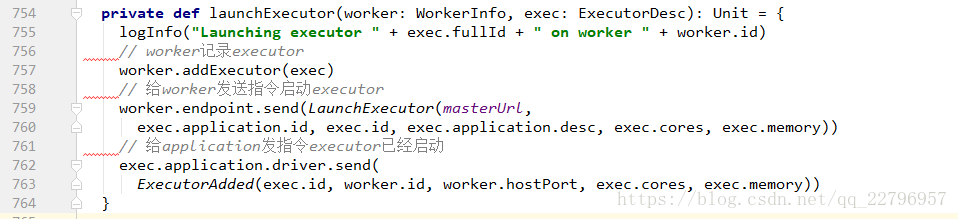
Spark只有在cluster模式下启动时,才会有Driver的资源调度,如果在client模式下启动,Driver就在提交Job的机器上启动。
资源调度指的是应用程序获得的计算资源,任务调度是在资源调度的基础上进行的。
Master是负责资源调度和管理的,每次有新的应用程序或者集群资源发生变化的时候都会重新资源调度(也就是schedule()方法的执行);
发生资源变化的动作有:RegisterWorker,RegisterApplication,ExecutorStateChanged,completeRecovery,relaunchDriver,removeApplication,handleRequestExecutors,handleKillExecutors,removeDriver
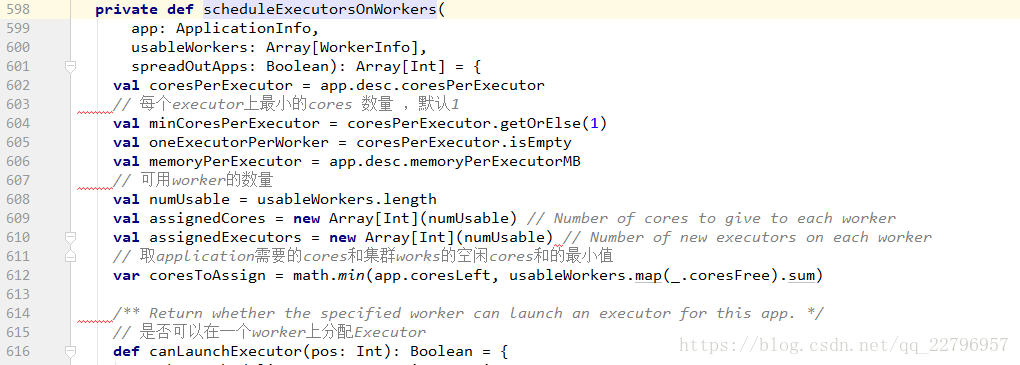
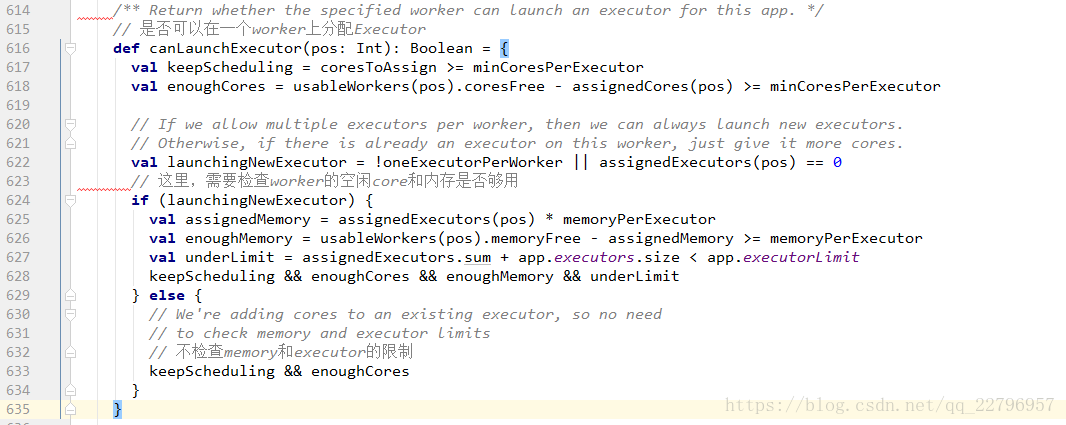
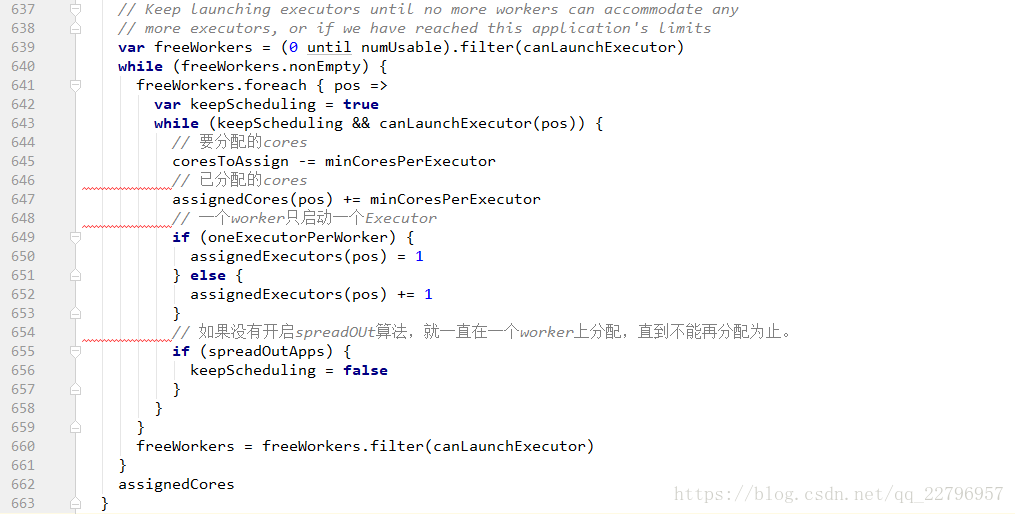
spark提供了两种资源调度算法:spreadOut和非spreadOut。spreadOut算法会尽可能的将一个application 所需要的Executor进程分布在多个worker几点上,从而提高并行度,非spreadOut与之相反,他会把一个worker节点的freeCores都耗尽了才会去下一个worker节点分配,默认是spreadOut算法,具体配置如下:

Master必须是Alive的方式才能进行资源的调度,如果不是alive的状态会直接返回,也就是standby Master不会进行Application的资源调用;
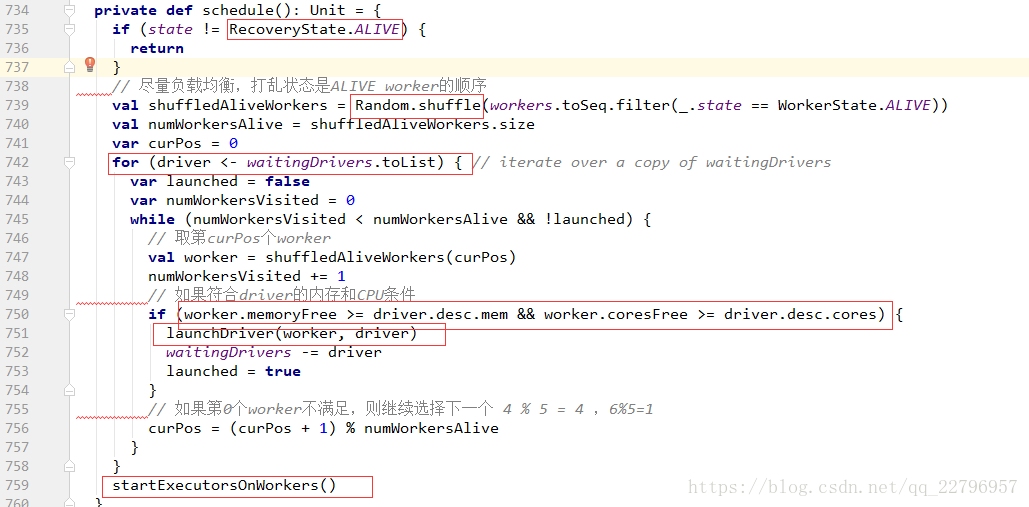
worker与driver相互记录
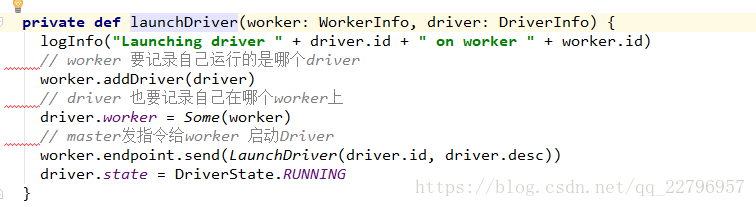
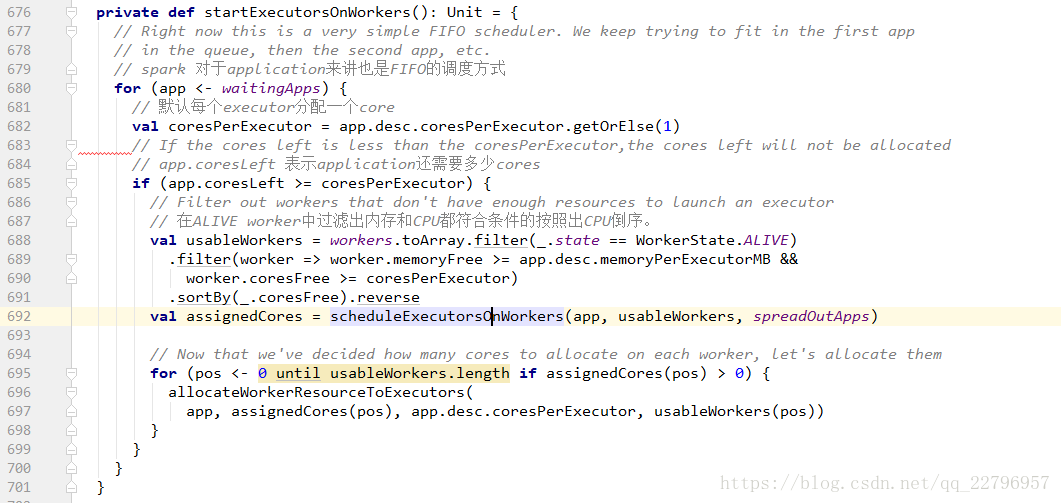
然后开始executor调度: