- 微软
- Kai Shen∗, Zeqian Ju∗, Xu Tan∗,
- demo page
abstract
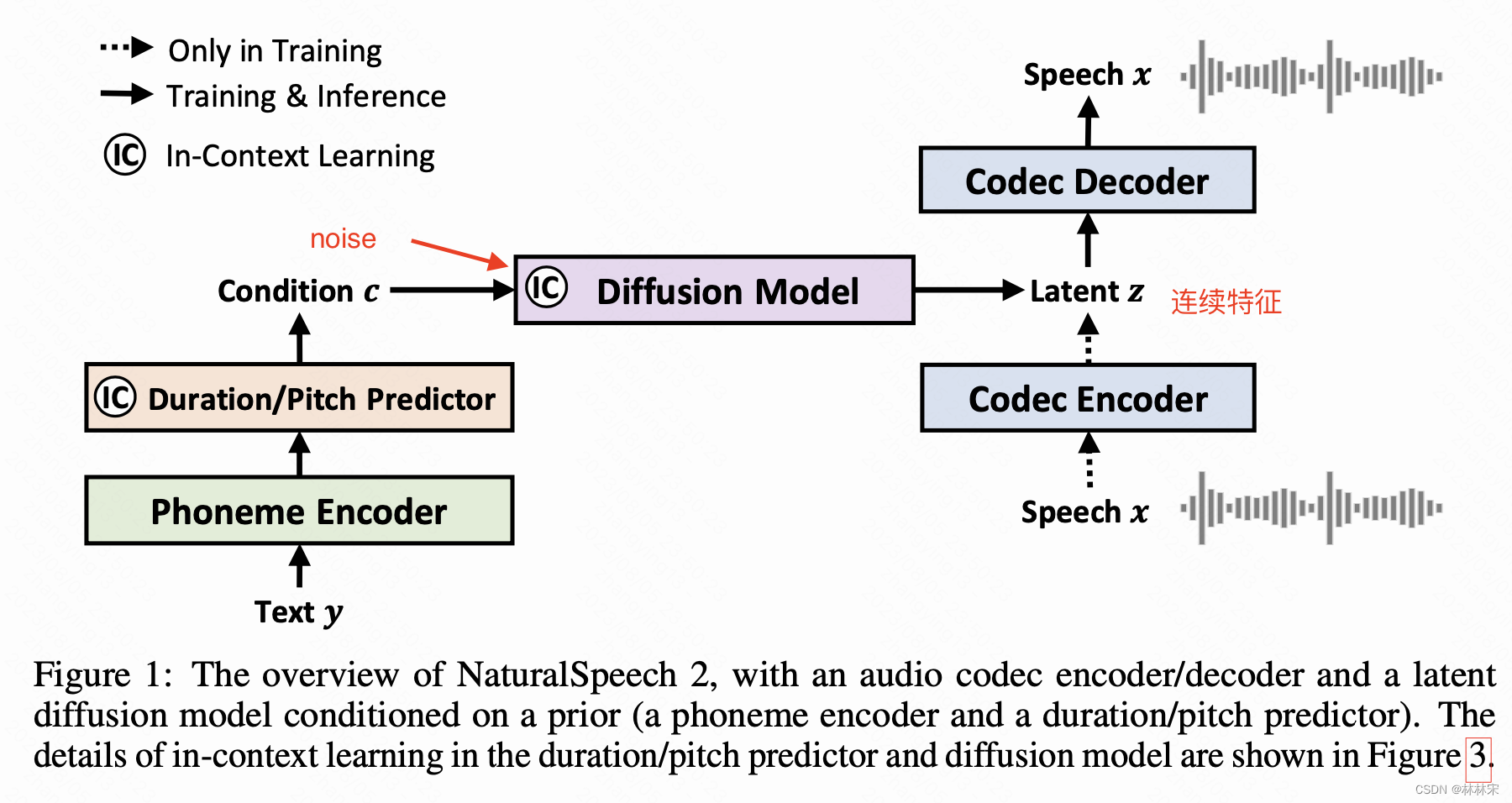
- 想要zero-shot的实现TTS音色复刻,包括对韵律,多样性风格的复刻。
- 方法:neural codec/decodec的方法,和vall-e/audio_LM等不同的是,本文使用的是量化后的index编码回查码本的连续域向量(这个选择后文说理由),代替传统TTS系统中使用的声学特征(mel之类)。声学模型部分和fastspeech类似,输入音素,预测phn/pitch/duration相关的信息,送给diffusion结构作为condition,预测编码的连续域向量,最后通过镜像结构的解码器生成音频。
- 训练细节:
- 44k h的音频数据,
- 8V10016G训练codec/decodec,参考SoundStream结果和设计;
- 16V10032G训练diffusion,300K underfitting;inference阶段,diffusion step=150;
background

- 音频编解码+LLM的训练方式在TTS有成功的尝试,缺点在于,音频编码到离散点有助于简化LLM的训练,但是有很多高频细节的损失,导致重建的音频质量比较低;如果使用多个RVQ量化结果,编码的长度是成倍增加的,使得自回归decoder的难度增加,而且会有自回归结构本身的问题出现(漏字,跳字,重复等)。
- diffusion结构在图片生成领域的成功实践/
method
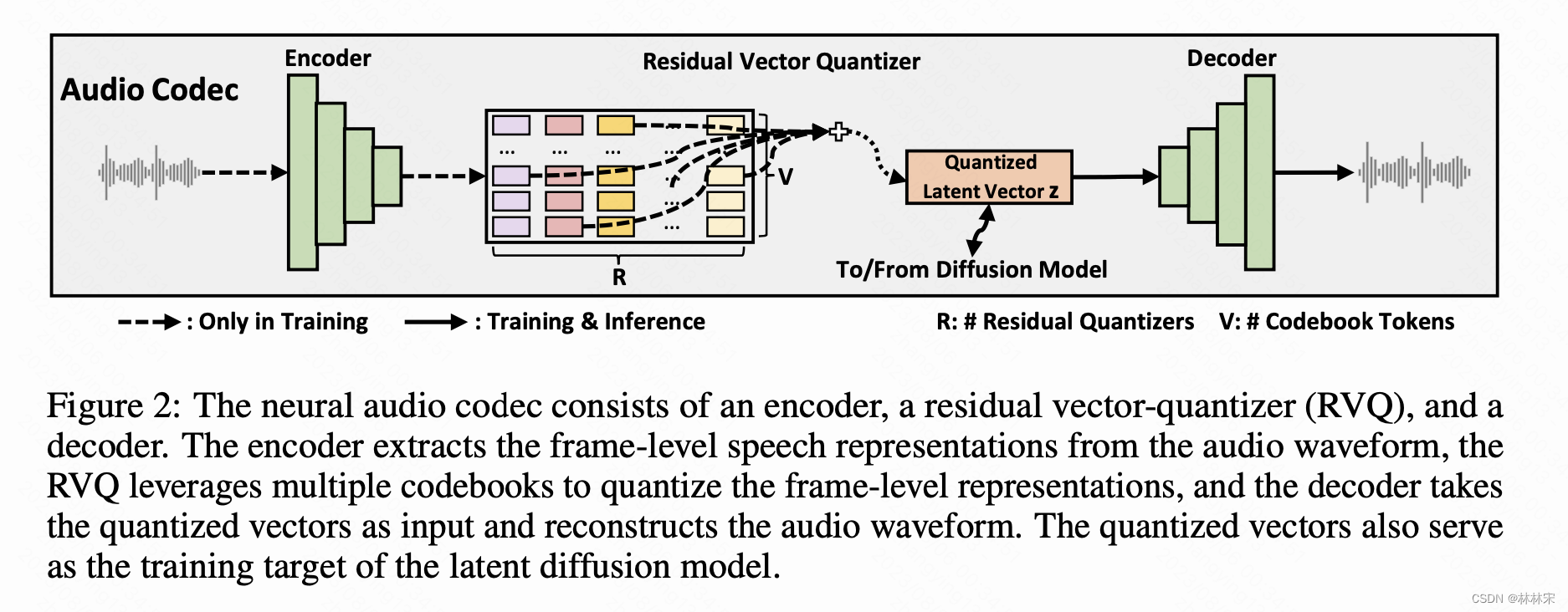
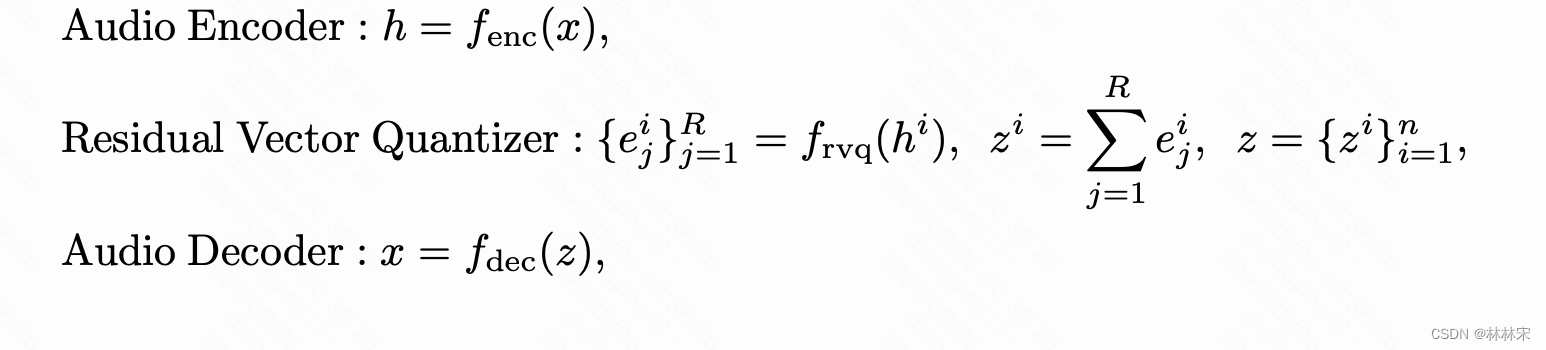
- codec的输出结果经过RVQ多级量化,存储码本 & index,便于节省存储空间;多级RVQ的结果求和,作为decodec的输入或者diffusion结构的预测目标。训练的时候还有加CE loss,预测index,辅助更好的预测有助于音频质量的提升。
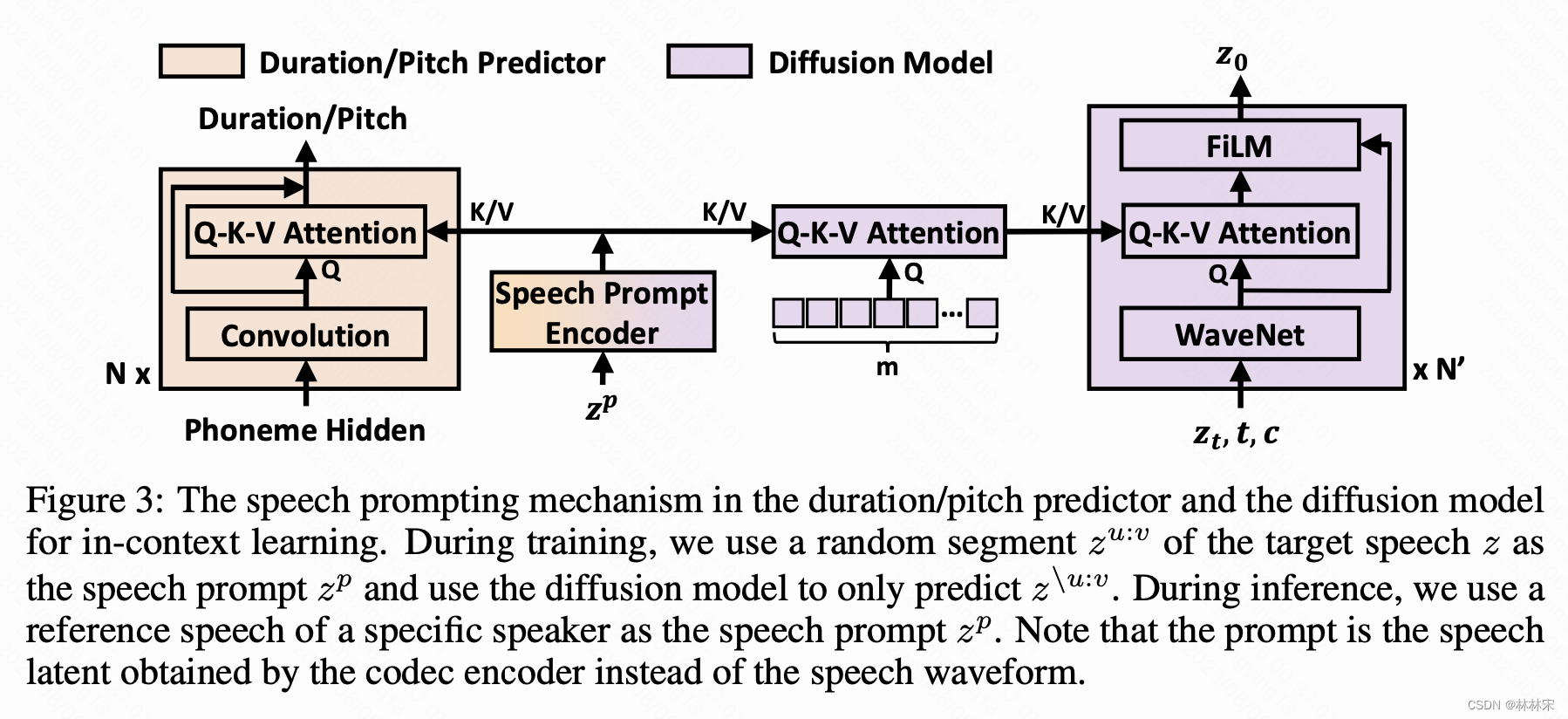
- speech in-context learning:
- 一个音频,中间截取一段作为prompt,作为attention k/v的方式送给duration/pitch,预测未截取的拼接后的前后段;
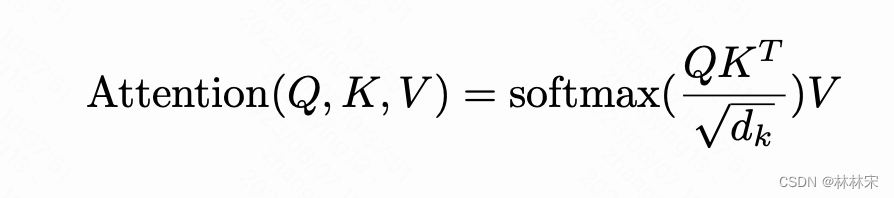
- speech是Q,【T, D】,和prompt的K/V作用,最终得到的特征维度还是【T,D】(【T,D】【DV】*【V,D】)
- 但是不能这样直接送给diffusion,因为会有信息泄漏影响diffusion的生成质量。(1)在第一个diffusion中,使用m个随机初始化的Q向量和prompt计算,(2)第二个attention中,只用wavenet输出的结果作为Q,前一个attention计算的结果作为K/V。
- 原始数据中的构成元素其实由一系列的<Key,Value>数据对构成,对应NS2中K,V,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对原始数据中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。而NS2中的query是随机初始化的,因此这些加权系数也是随机生成的,对value进行随机组合。有一定的扰乱信息的作用,从而减少信息。这样增加了diffusion模型学习的难度,从而泛化能力更强。
- 一个音频,中间截取一段作为prompt,作为attention k/v的方式送给duration/pitch,预测未截取的拼接后的前后段;
experiment
Q&A
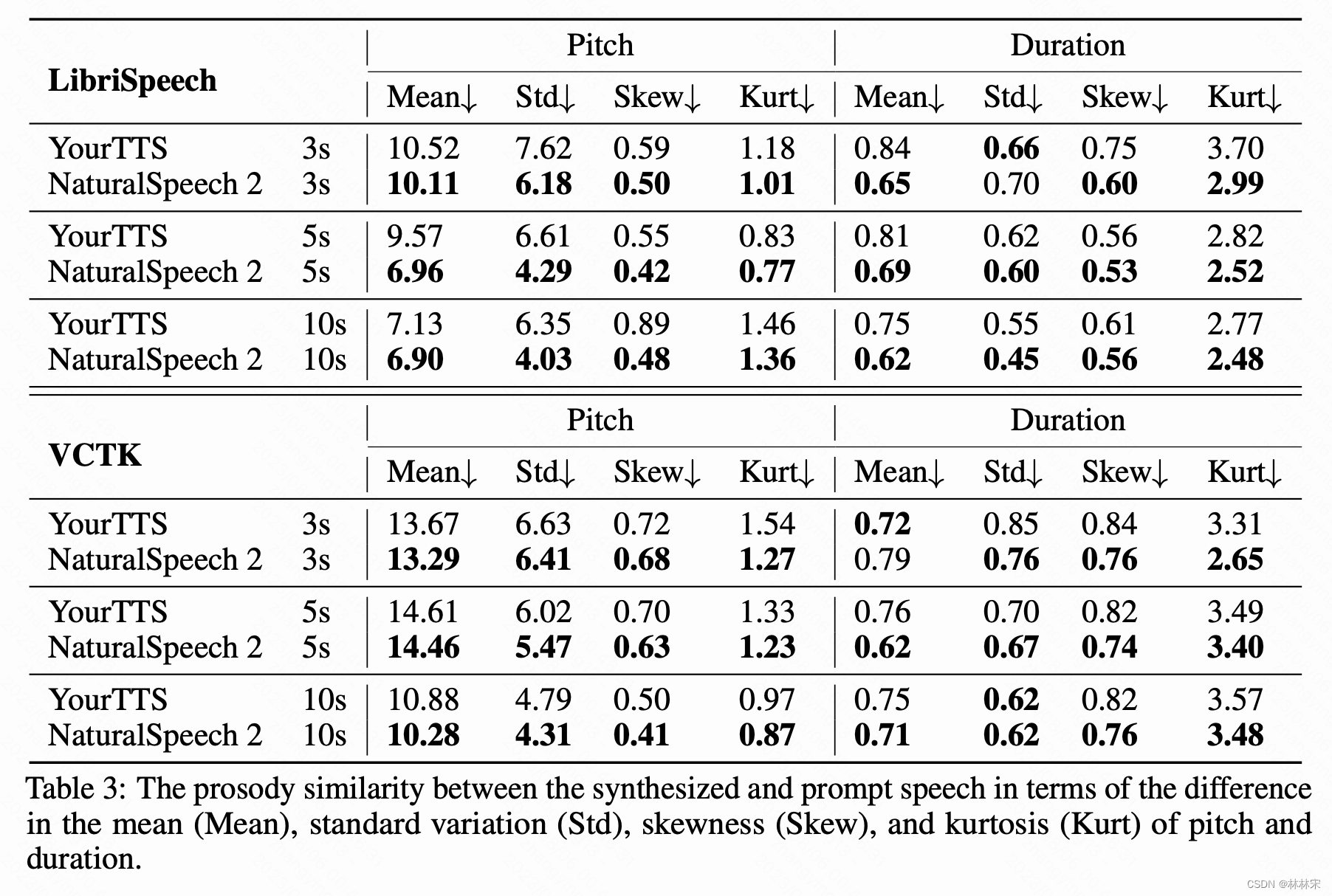
- 为什么都是用连续embedding了,和使用mel的区别:
i. Mel有相位的损失,本身是一个有损的特征;更期望用end2end编码的无损特征;
ii. 离散emb有助于LLM收敛,但是低码率的高频损失比较多;高码率的序列长度非常大;
iii. 连续emb实际保存的是码本和index,对于大数据的存储资源是非常有好的。 - Scaling效应
i. 1wh以下的数据量比较难有zero-shot的效应;1wh开始有,但是由于没有对训练数据集的数据进行筛选,音质比较差;2wh以后音质和zero-shot的效果都比较好;论文用的4.4wh
ii. 模型size:100M以下不行;200M以上开始可以;论文使用的400M模型;both deep and wide - demo中的VC效果
i. 需要准备source speech,target speech,source text特征
ii. diffusion输入的是source speech编码后的codec特征,prompt是target speech codec,实际上依赖diffusion的降噪能力做有条件的降噪,而不是真正的VC