一、问题背景
最近研究了seq2seq模型的相关优化算法,包括有其中的Attention、dropout、Scheduled Sampling和Teacher Forcing等优化、训练模型的方法。以下是传统seq2seq模型结构,没有进行任何优化,该模型分为两部分:编码器和解码器。 编码器读取输入文本,并返回代表该输入的向量。 然后,解码器获取该向量并依次生成相应的文本。
这样依次按概率生成词的模式,就会使得系统为了达到生成结果的概率最大,就会产生很多通用一致的回复,这必然是我们不想看到的,所以目前产生了很多算法来优化Decoder的生成部分。大致有以下这些方法:
- Greedy Search
- Beam Search
- Random Sampling
- Temperature
- Top-K Sampling
- Nucleus Sampling
下面我来依次介绍各种方法的原理。
1. Greedy Search
这种方法是最简单的,原理就是在decoder生成每个词语的时间步上,选择每次生成概率最大的词语。但选择每次概率最大的词语,但不一定是总体上最优的结果,可能是一个次优选项,因此我们直接改进这种算法,变成Beam Search。
2. Beam Search
对于上述greedy search算法的缺点,我们首先想到的是可以根据每次词表中的概率来穷尽所有的结果,并计算出各自的总概率,但当我们的词表的维度足够大的时候,会产生极大的计算量,不适合实际应用场景。
自然我们想到,可以在第一个时间步上,选择n个的最优结果,然后进入到下一个时间步,再重复上述操作,选择n个最优的结果,这个时候就会存在n×n个结果,我们选择其中最优的n个结果,再进入到下一个时间步,重复上述步骤,上述的流程效果图如下:
当到了最后的时间步后,我们可以得到n个最优的结果供我们选择,这个就是集束搜索(Beam Search)的实现方法。
有时候,它会选择一个较好的回复响应,在这种情况下,这是很有意义的。 但是,请想象该模型喜欢安全运行,并且在大多数情况下都会不断产生“我不知道”或“谢谢”,这将是一个十分糟糕的模型。
3. Random Sampling
每个时间步上我们会根据softmax产生一个词典上各个词语的输出概率,假设下边是第一个词语产生的一个概率分布。
从上图中可以看出,i 的产生概率为0.2左右,是所有词语概率最高的,如果我们使用greedy search策略,则大概率会选择出i,其他单词的发生的概率极低。
因此,随机抽样本身可能会偶然产生一个非常随机的词,我们需要加入一定的策略进行改进。
4. Temperature
温度用于增加可能的词语的概率,同时减少概率较低的词语的概率。 通常,范围是0 <temp≤1。请注意,当temp = 1时,没有任何作用。
带有温度的随机采样,原理就是将softmax的原理进行改进,其公式如下(t即temp):
因此单词的输出概率分布会变成,
从上图中可以看出,当temp = 0.5时,最可能出现的单词(如i,yeah,me)更有可能被生成。 同时,这也降低了可能性较小的可能性,尽管这并不能阻止它们的发生。5. Top-K Sampling
Top-K采样用于确保不太可能的单词根本没有机会产生,我们只需考虑前K个可能的单词,下边就是三种采样方式分布图。
从上图中可以看出,如果我们使用温度= 0.5或1.0的随机采样,则介于50到80之间的令牌索引具有较小的概率,使用top-k采样(K = 10)时,这些标记就没有机会被生成,我们也可以将Top-K采样与温度结合起来。
在许多近代任务中已经采用了这种采样技术。 它的表现是相当不错的。 这种方法的局限性在于,一开始需要定义前K个词的数量,假设我们选择K = 300; 然而,在解码时,模型可以确定应该有10个高度可能的单词, 如果我们使用Top-K,这意味着我们还将考虑其他290个不太可能的单词。
6. Nucleus Sampling
核采样类似于Top-K采样。 核采样不是集中在Top-K单词上,而是集中在Top-V单词的最小可能词的集合上,以使它们的概率之和≥p。 然后,将不在V ^(p)中的标记设置为0;否则将标记设置为0。 其余的将重新缩放以确保它们的总和为1。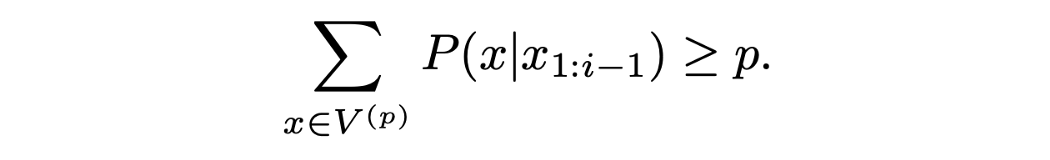
以下是Top-k采用与核采样的分布效果对比。
将核采样(p = 0.5)与top-K采样(K = 10)进行比较,我们可以看到核不认为标记“ you”是候选对象。 这表明,与Top-K采样不同,它可以适应不同的情况并选择不同数量的令牌。
综上所述:各采样方法的特点是:
- Greedy: Select the best probable token at a time
- Beam Search: Select the best probable response
- Random Sampling: Random based on probability
- Temperature: Shrink or enlarge probabilities
- Top-K Sampling: Select top probable K tokens
- Nucleus Sampling: Dynamically choose the number of K (sort of)
经过了大家尝试探索,通常首选是集束搜索,top-K采样(带温度)和核采样。
这些技术可以应用于不同的生成任务,即图像字幕,翻译和故事生成, 仅使用具有不良解码策略的良好模型或具有良好解码策略的不良模型是不够的, 两者之间的良好平衡可以使这个生成效果变得更加有趣。