目录
一、简介
1.1、什么是scrapy
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。
1.2、结构性数据
类似的,具有相同结构的数据,称为结构性数据,如下图。

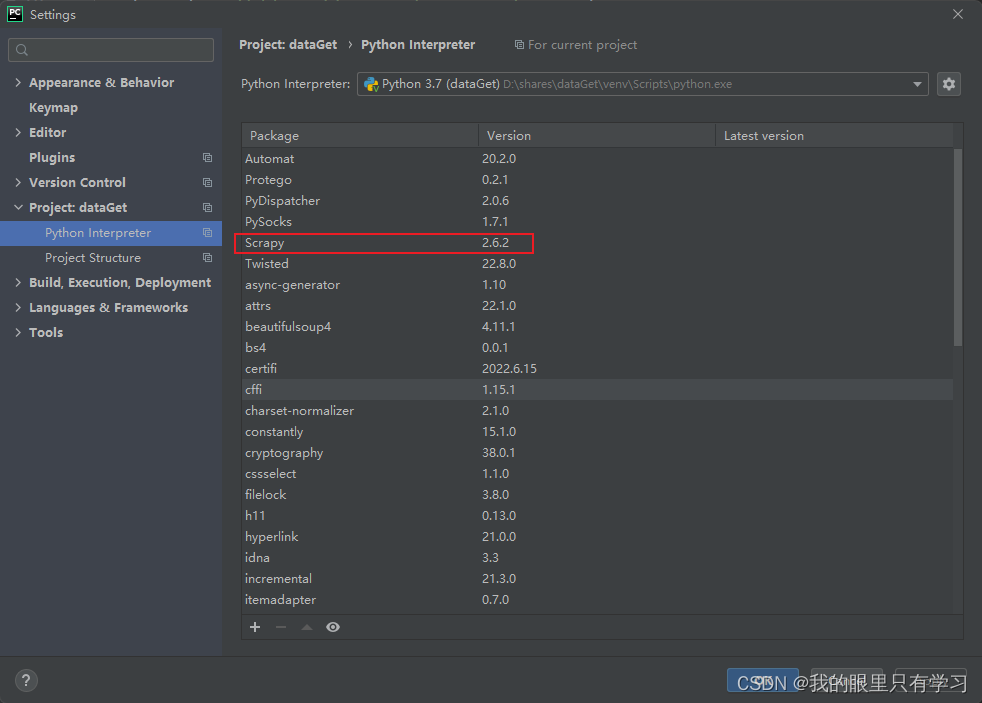
1.3、安装
二、scrapy的使用
2.1、创建scrapy项目
1)在终端输入:scrapy startproject 项目名称
注意:项目名称不能以数字开头,且不能包含中文
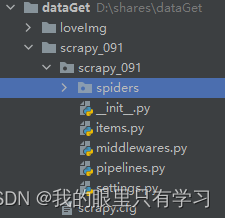
2)此时,在目录下会出现新建的scrapy项目
2.2、创建爬虫文件
1)进入spiders文件夹下,创建爬虫文件:scrapy genspider 爬虫文件名称
scrapy genspider baidu http://www.baidu.com
注意:1)需要在spiders文件夹中创建爬虫文件
2)域名不需要加http协议,scrapy会自动添加
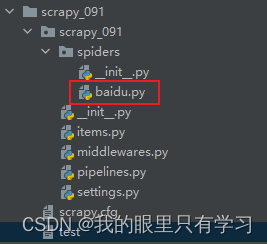
2)创建成功:
3)baidu.py文件内容
注意:如果请求的页面以 html 结尾,最后的 “/” 需要删除
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫名字:运行爬虫时使用
name = 'baidu'
# 允许访问的域名
allowed_domains = ['www.baidu.com']
# 起始的url地址,表示第一次访问的域名:
# start_urls = 'http://' + allowed_domains + '/'
start_urls = ['http://www.baidu.com/']
# 方法中response为爬取网页后的返回对象
# 类似于:response = urllib.request.urlopen(request)
def parse(self, response):
pass
2.3、运行爬虫代码
1)注释掉settings.py文件中的 ROBOTSTXT_OBEY


2)运行:scrapy crawl 爬虫的名字
2.4、实战
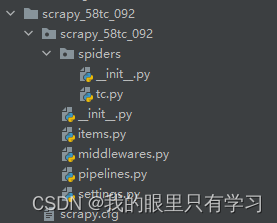
2.4.1、scrapy项目结构
scrapy项目的结构:
--项目名称
--项目名称
--spiders文件夹(存储的是爬虫文件)
--__init__.py
--tc.py (自定义的爬虫文件 核心功能文件)
--__init__.py
--items.py (定义数据结构的地方 爬取的数据都包含哪些)
--middlewares.py (中间件 代理)
--pipelines.py (管道 用来处理下载的数据)
--settings.py (配置文件 robots协议 ua定义等)
2.4.2、response的属性和方法
| 方法 | 作用 |
| response.text | 获取的是响应的字符串 |
| response.body | 获取的是二进制数据 |
| response.xpath | 可以直接是xpath方法来解析response中的内容 |
| response.extract() | 提取selector对象的data属性 |
| response.extract_first() | 提取selector列表的第一个数据 |
2.4.3、scrapy架构组成

2.4.4、scrapy工作原理

三、scrapy shell
3.1、什么是scrapy shell

3.2、安装
3.3、应用
3.3.1、进入scrapy终端
(1)scrapy shell www.baidu.com
(2)scrapy shell http://www.baidu.com
(3)scrapy shell “http://www.baidu.com”
(4)scrapy shell “www.baidu.com”

3.3.2、语法
response对象:
response.body
response.text
response.url
response.status

response解析:
response.xpath
response.extract_first()
response.css()

四、CrawlSpider
4.1、介绍

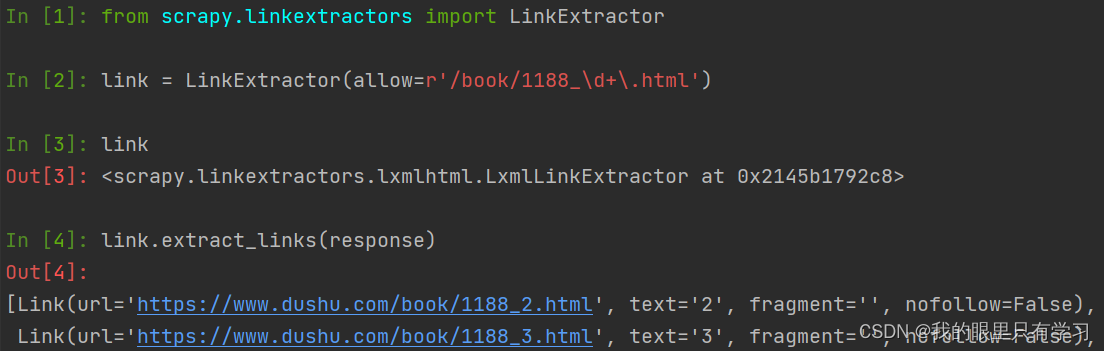
4.2、实操
五、数据入库


六、日志信息及日志等级


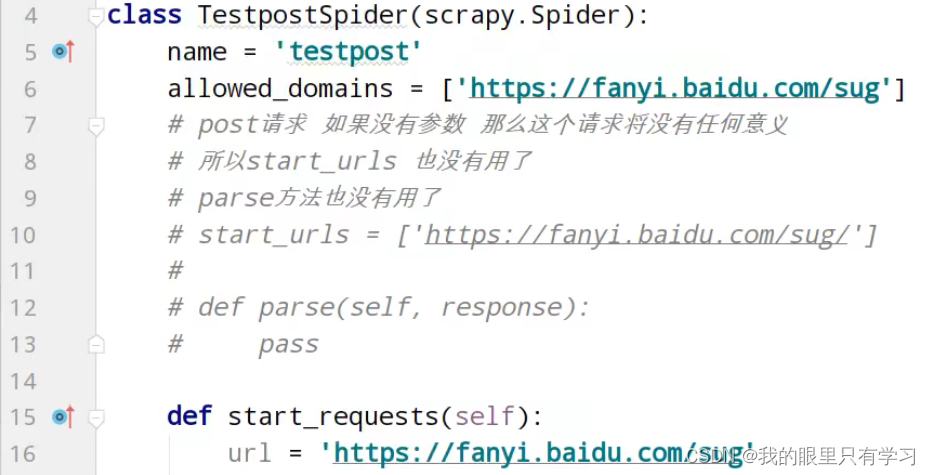
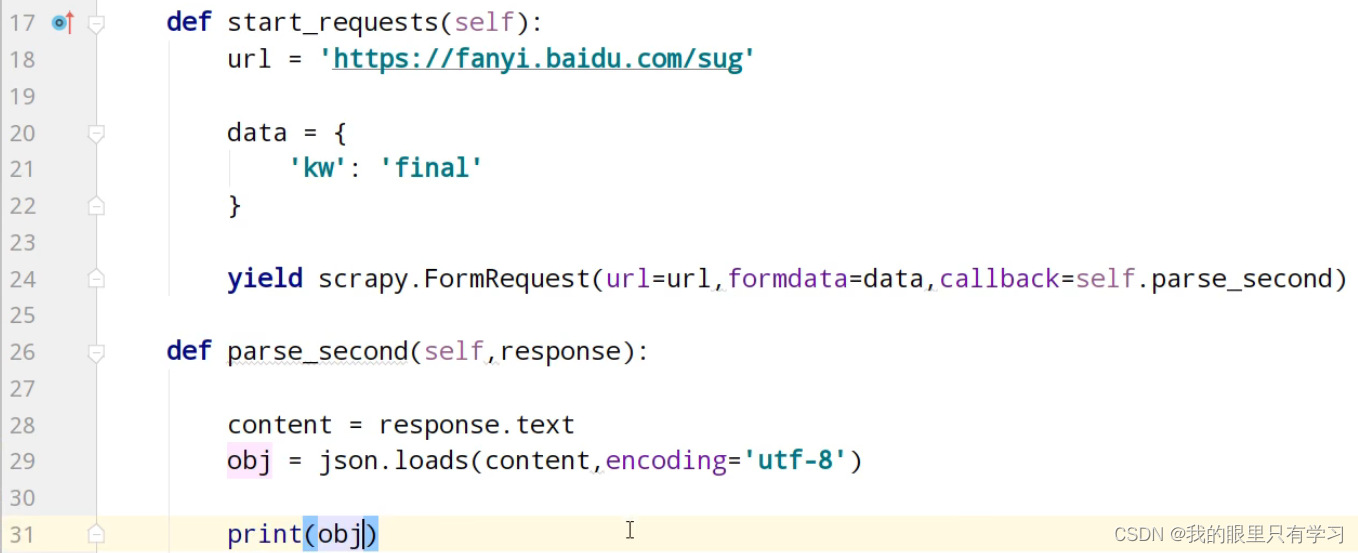
七、scrapy的post请求

八、代理
