Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度。
也就是说,你是用scrapy后就不用自行在考虑多任务(多线程、多进程、协程)等问题了,这些问题scrapy这个框架会实现帮你处理好你所需要的。同时Scrapy中有很多方便的功能,比如说连接提取器,图片下载器,自动登录等。
下图为一个scrapy爬虫框架的流程。
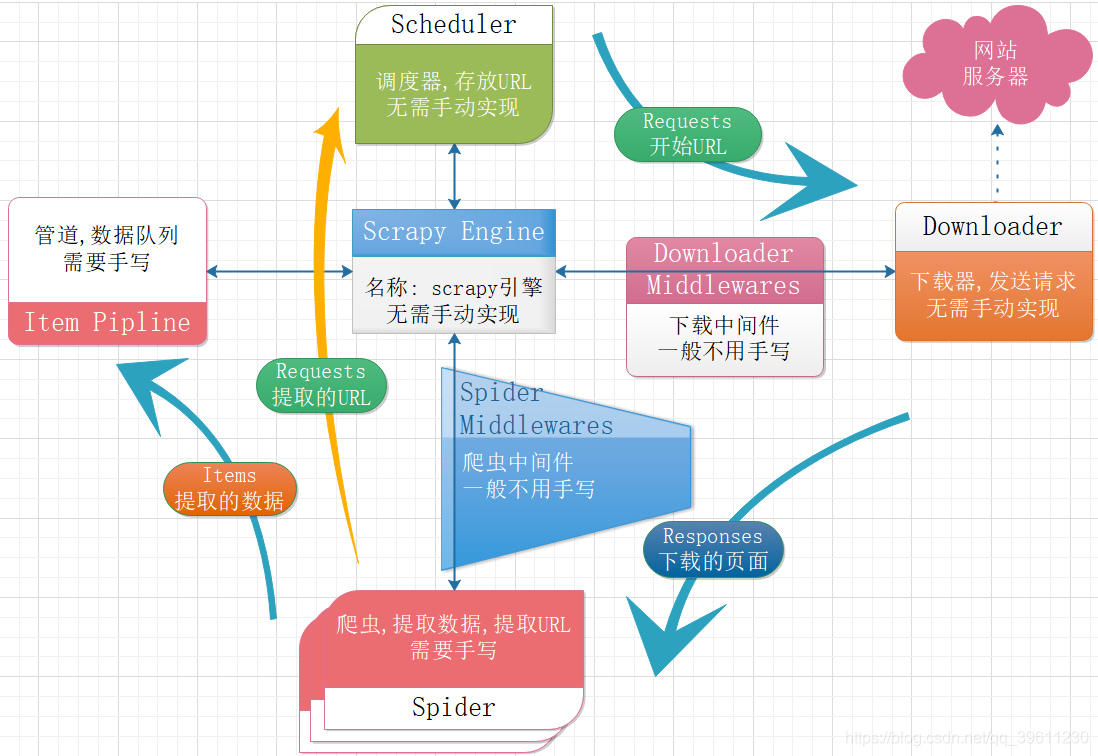
从上图可以看出,使用Scrapy的一个大致流程,
- 指定第一个URL放入调度器
- 下载器会从调取器中读取URL并自动访问下载,传入爬虫
- 爬虫将提取的URL在此传入调度器,提取的数据传入管道进行保存
- 重复上述操作,直到完成调度器中所有的URL
初看scrapy可能你会觉得这比requests不是根据复杂了吗。的确相比于requests,scrapy的学习成本更高,但学会后,使用起来会比requests要更加高效,这里的高效不仅是爬取效率上,在代码编写上同样更加高效,写更少的代码就能实现更丰富的功能。scrapy是一个爬虫框架,而requests是一个库。
Scrapy安装
pip install scrapy,pycharm也可以使用可视化界面安装,上面的操作就不解释了,有Python基础的应该不会看不懂。如果你连基本的Python基础都没有,学习Scrapy对你来说会比较困难,建议先把Python基础学好。
常见安装报错
Scrapy是一个依赖众多库(zope.interface、Twisted、pyOpenSSL、pywin32…)的库,安装他时会出现各式各样的问题,大部分问题是因为缺少c++环境导致的,而需要用到c++环境的库是Twisted,也就是说大部分导致我们安装失败的原因是Twisted造成的
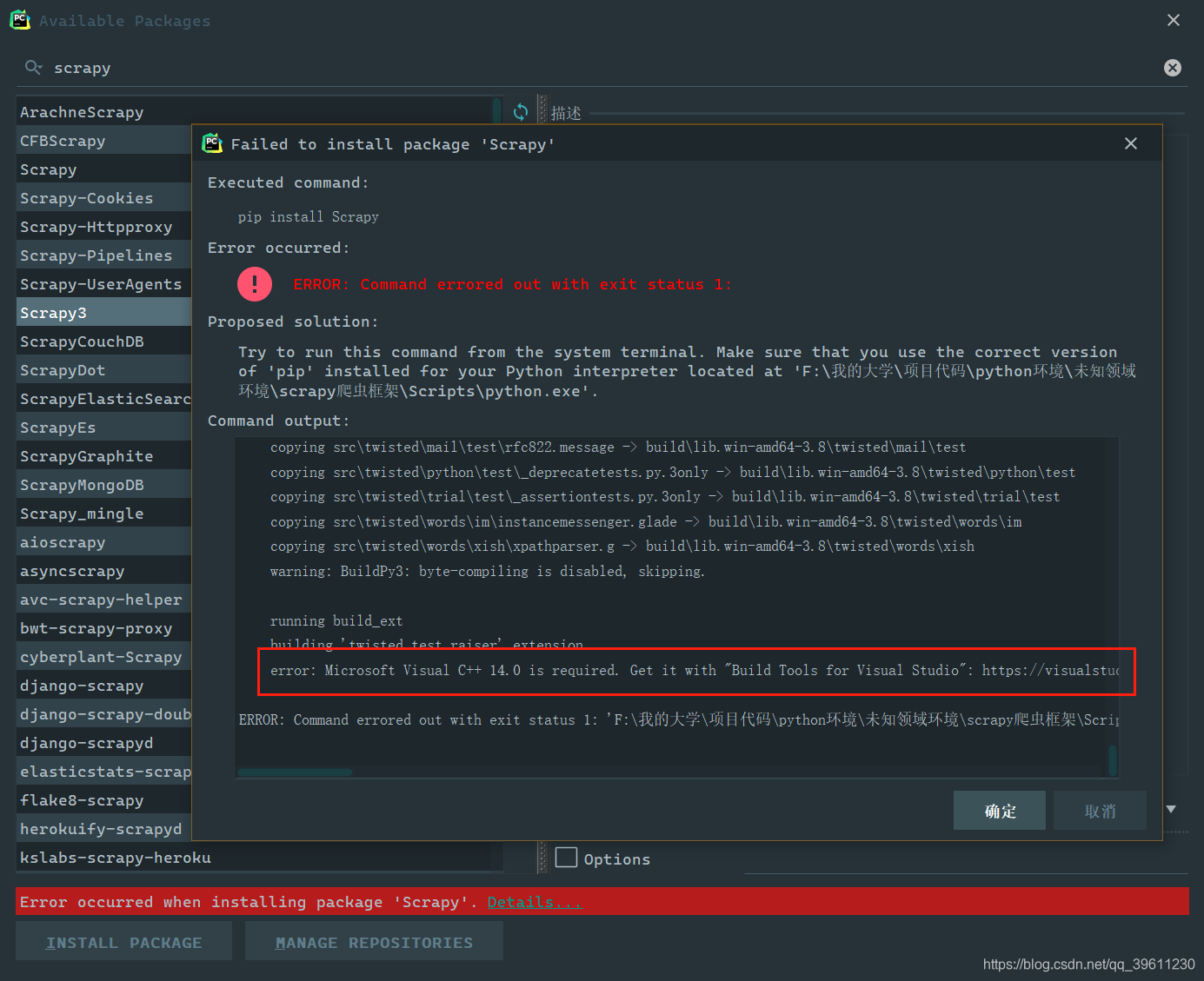
首先你要确保你真的拥有c++环境
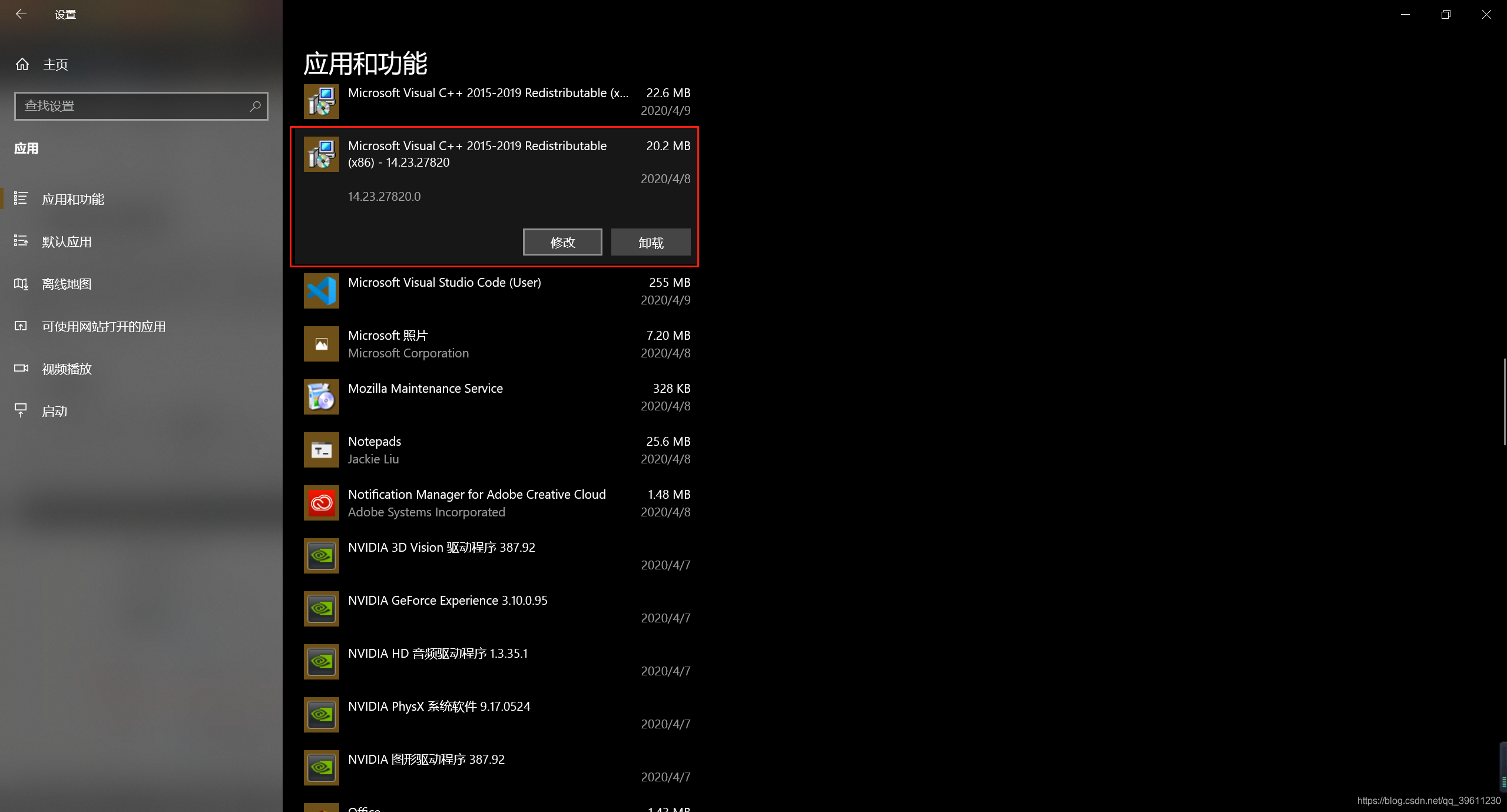
如果没有可以去微软官网下载
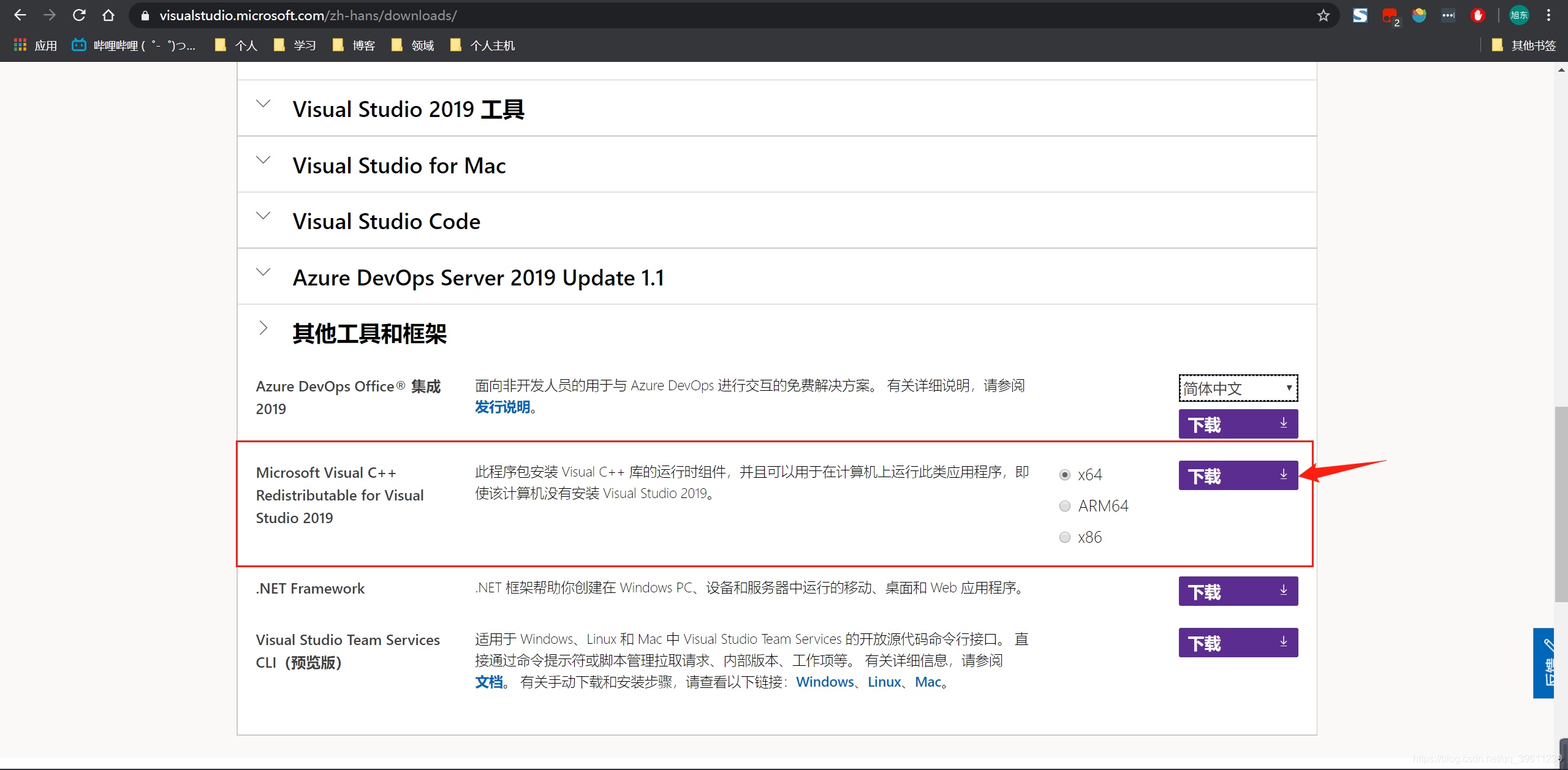
如果你已经有c++环境却还是报了当前的错误,你可以使用下列方法去尝试解决(碰到此问题大多数可能是因为使用了虚拟环境造成的,在虚拟环境中就算安装了C++环境也经常出现无法找到的情况。)
虚拟环境报错解决方法
现在全局环境中安装scrapy,然后在将其移动到虚拟环境中,python会讲包放在Python安装目录\Lib\site-packages下,全局环境中默认只有pip和setuptools两个包,我们可以现在全局环境中安装好scrapy再将其移动到虚拟环境中,虚拟环境的位置也同样在Python虚拟环境目录\Lib\site-packages中
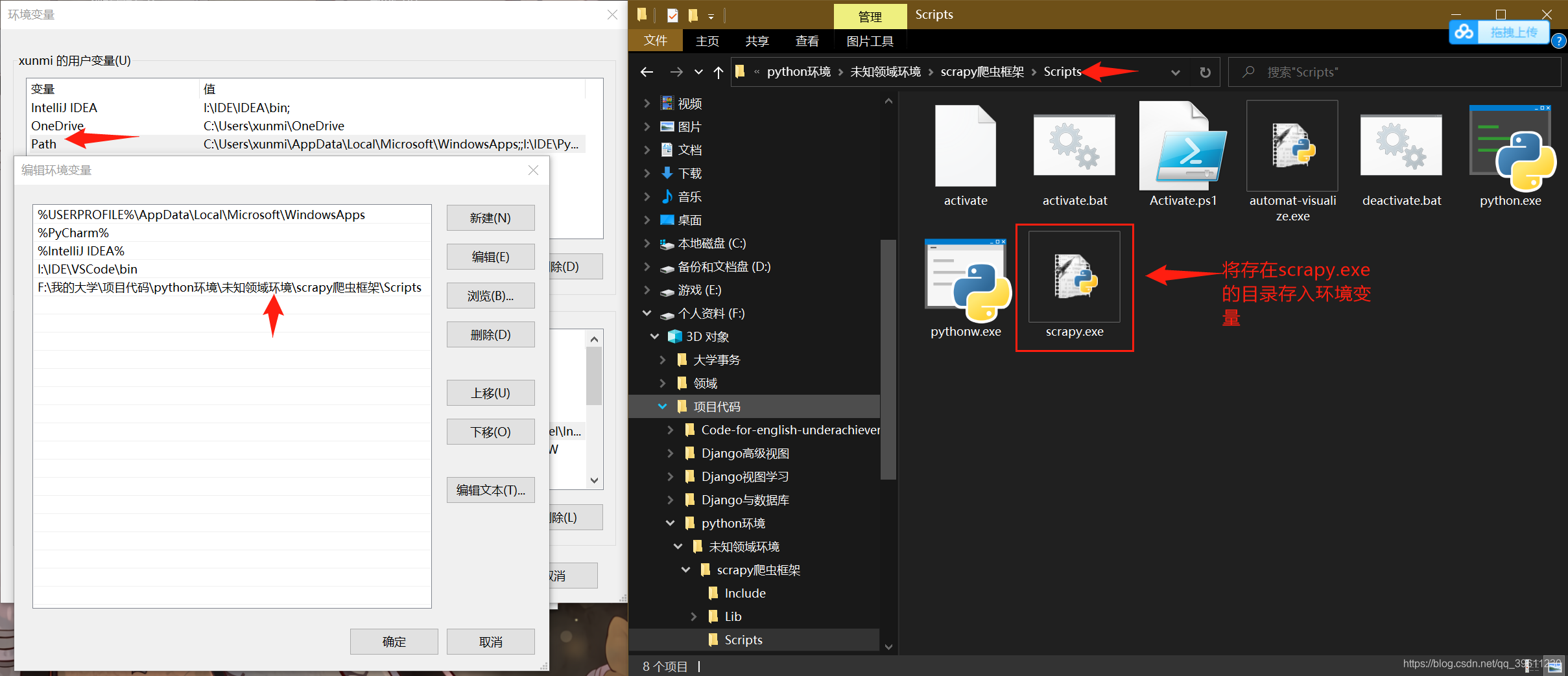
如果全局环境中安装scrapy还是报错,我们可以尝试下载离线的Twisted(http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)进行安装,
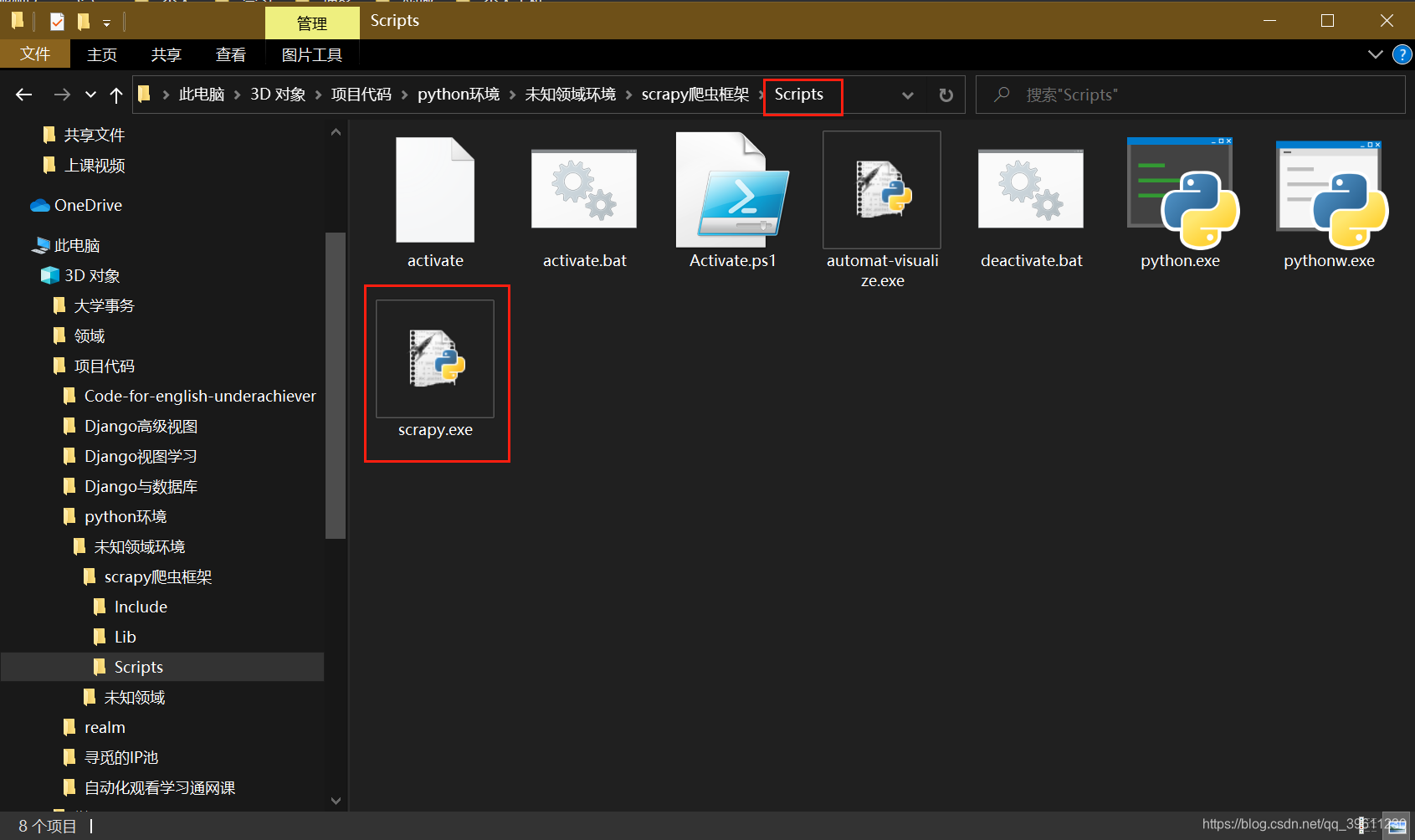
安装好后的在Python环境\Scripts目录下能看见一个scrapy.exe才算成功
Scrapy官方建议
尽管可以使用pip在Windows上安装Scrapy,但我们建议您安装Anaconda或Miniconda并使用conda - forge频道中的软件包 ,这样可以避免大多数安装问题。
PS:看来官方是知道pip存在的一堆问题,希望能尽快解决。
Scrapy创建
安装完上述环境后你可以先尝试在cmd中输入scrapy
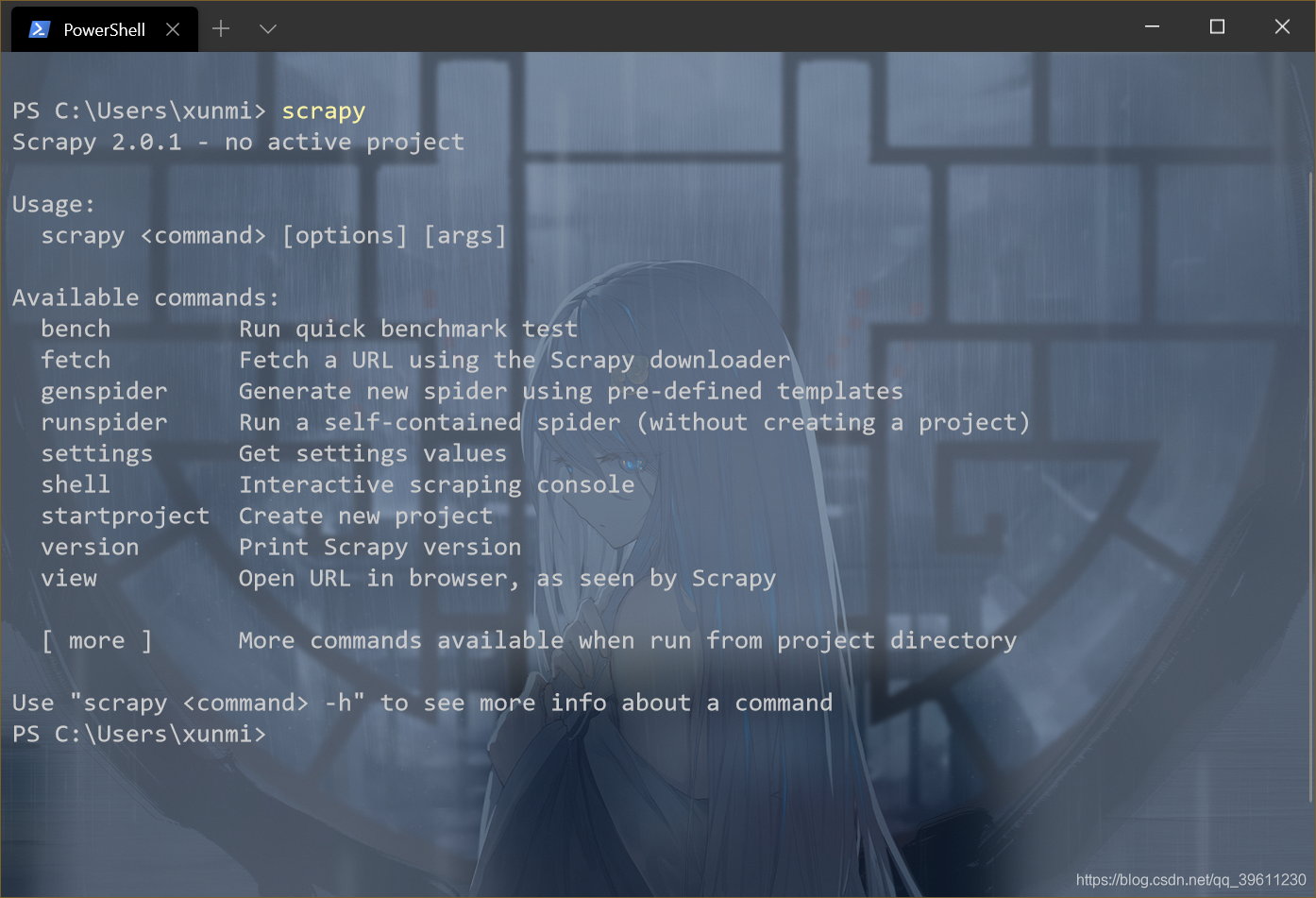
如果没有报错,这证明安装成功已经可以使用了,如果没有出现此提示,请将Scrapy所在的环境(一半不出现的问题就是你安装到了虚拟环境,只需要将虚拟环境放入全局变量中即可)
我们先cd到一个存放爬虫的目录,因为执行下面的语句会自动生成一个文件夹其中携带一些配置文件
scrapy startproject 爬虫名(只支持英文和下划线)
创建好爬虫项目文件夹后我们先cd进入创建的爬虫项目,然后执行下列语句,即可生成一个爬虫目标
scrapy genspider 爬虫名 "爬取网址"
scrapy genspider demo "demo.cn"
生成的爬虫会保存在spiders中
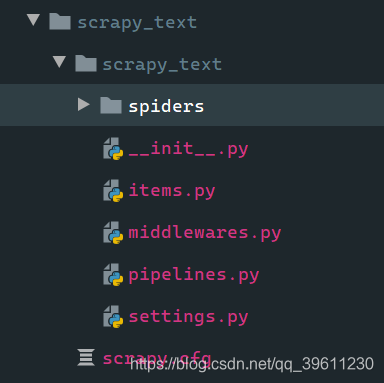
项目目录解析
我们使用scrapy startproject会自动帮我们创建一些目录和文件
| 目录 | 作用 |
|---|---|
| spiders | 存放爬虫文件,其中包含爬虫的业务逻辑(爬取那些网站) |
| items | 封装数据 |
| middlewares | 中间件(爬虫中间件和下载中间件) |
| pipelines | 管道,数据保存 |
| settings | 设置文件 |
启动爬虫
我们创建的爬虫(scrapy genspider 爬虫名 "爬取网址")会自动进入spiders文件夹中
如何启动爬虫,有两种方法,一直是从命令行启动
启动爬虫我们有两种方式
- 命令行启动
命令行输入
scrapy crawl 爬虫名 - .py文件启动
在项目文件夹中创建一个.py文件,名称随意(和scrapy.cfg同级)
其中写入下列代码
from scrapy import cmdline
cmdline.execute("scrapy crawl 爬虫名".split())
启动此项目即可启动指定的爬虫
