我们知道,Java设计的顶级父类Object类中,有两个方法很特殊,它们分别是equals方法与hashCode方法。当我们在使用的时候我们总是被提醒,一旦重写了equals方法,就一定要重写hashCode方法。为什么?很多同学会想这个问题,聊明白这个也就是这篇文章的目的。
在正式探究原因之前,我们先进行前期的铺垫–弄明白这两个方法之间千丝万缕的联系,我们先来看看Object这个类的作者是怎么说的,打开Object类我们能看到如下注释。

Object类中equals方法
注释中的大致意思是:当我们将equals方法重写后有必要将hashCode方法也重写,这样做才能保证不违背hashCode方法中“相同对象必须有相同哈希值”的约定。
此处Object类的作者只是提醒了我们重写是必要的,重写是为了维护hashCode方法设计的定义,但是为什么要维护hashCode方法设计的定义呢?我们带着疑问继续去看hashCode方法的定义。

hashCode方法本质就是一个哈希函数,这个不是我根据字面意思瞎猜的,而是Object类的作者说明的。Object类的作者在注释的最后一段的括号中写道:将对象的地址值映射为integer类型的哈希值。(如果对哈希函数定义不大理解的同学可以看我另外一篇文章:通俗地理解哈希函数)。牢牢把握哈希函数的定义有利于帮助我们理解接下来的内容。
我们看到,hashCode方法注释中列了个列表,列表中有三条注释,当前需要理解的大致意思如下:
1.一个对象多次调用它的hashCode方法,应当返回相同的integer(哈希值)。
2.两个对象如果通过equals方法判定为相等,那么就应当返回相同integer。
3.两个地址值不相等的对象调用hashCode方法不要求返回不相等的integer,但是要求拥有两个不相等integer的对象必须是不同对象。
上面列的三条完完全全属于哈希函数的定义与属性范畴。所以我们将上方的三条注释内容代入到哈希函数的定义中帮忙理解。如果还不能理解也可以看下图:
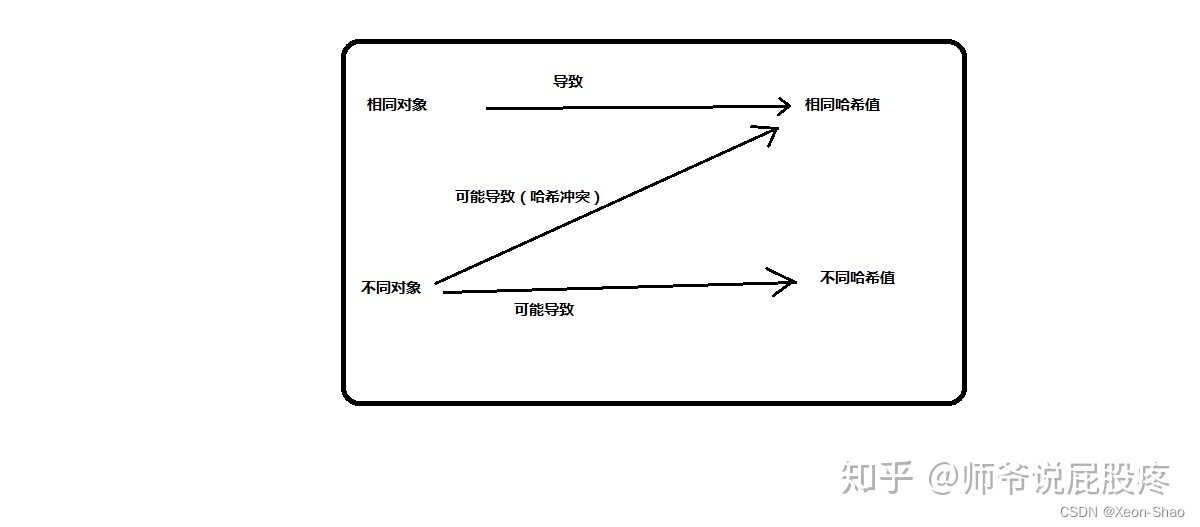
我们看到,图中存在两种独立的情况:
1.相同的对象必然导致相同的哈希值。
2.不同的哈希值必然是由不同对象导致的。
也就是作者在hashCode方法注释上写明了的定义,实际上作者也就是在实现一个哈希函数,并且把哈希函数的定义写到注释里。
其实我们看到这里,就能明白一件事情了:equals方法与hashCode方法根本就是配套使用的。对于任何一个对象,不论是使用继承自Object的equals方法还是重写equals方法。hashCode方法实际上必须要完成的一件事情就是,为该equals方法认定为相同的对象返回相同的哈希值。
Object类中的equals方法区分两个对象的做法是比较地址值,即使用“==”。而我们如若根据业务需求改写了equals方法的实现,那么也应当同时改写hashCode方法的实现。否则hashCode方法依然返回的是依据Object类中的依据地址值得到的integer哈希值。
这么说起来可能不是很好理解,我们代入到具体的例子–String类中好了。
String类中,equals方法经过重写,具体实现源码如下:
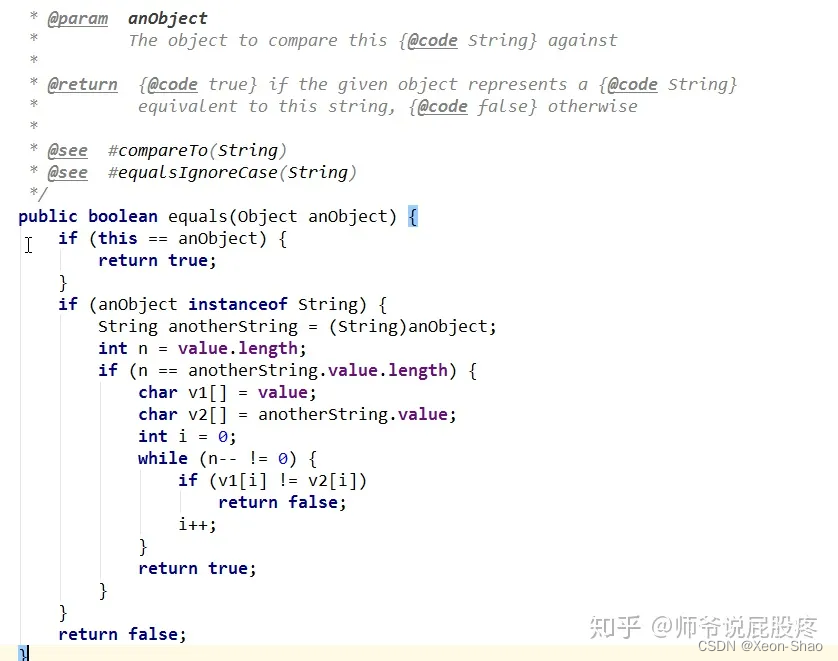
通过源码我们能看到,String对象在调用equals方法比较另一个对象时,除了认定相同地址值的两个对象相等以外,还认定对应着的每个字符都相等的两个String对象也相等,即使这两个String对象的地址值不同(即属于两个对象)。
此时我们能想到的是,String类中对equals方法进行重写扩充了,但是如果此时我们不将hashCode方法也进行重写,那么String类调用的就是来自顶级父类Obejct类中的hashCode方法。即,对于两个字符串对象,使用他们各自的地址值映射为哈希值。也就是会出现如下情形:
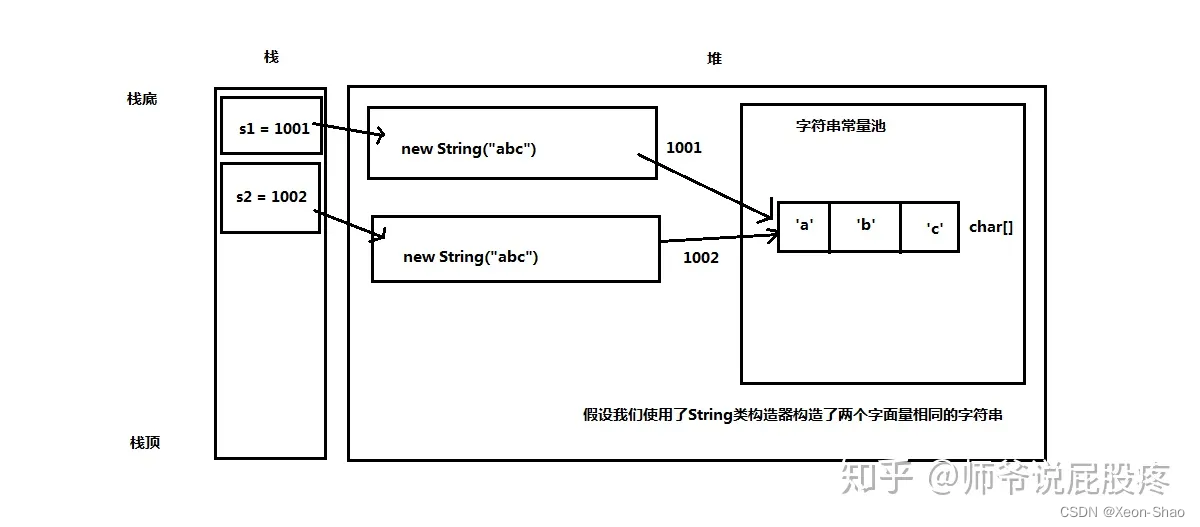
也就是说,被String类中的equals方法认定为相等的两个对象拥有两个不同的哈希值(因为他们的地址值不同)。问题分析到这一步,原来的问题“为什么重写equals方法就得重写hashCode方法”已经结束了,它的答案是“因为必须保证重写后的equals方法认定相同的两个对象拥有相同的哈希值”。同时我们顺便得出了一个结论:“hashCode方法的重写原则就是保证equals方法认定为相同的两个对象拥有相同的哈希值”。
看到这里,我的内心甚至没有一点波澜–两个字面量相同的String对象哈希值不同怎么啦!Object类作者给我的叮嘱我不遵守又怎么啦!说到现在为止,上方提到的任何东西都没有对我的实际代码没有造成任何影响。实际上是这样吗?两个被认定为相同的对象拥有不同的哈希值没有造成不便或者bug吗?这就是我们接下来要进一步挖掘的问题:为什么要保证它们的哈希值相等呢?“hashCode方法返回的哈希值在语言中扮演了一个什么角色?”。
其实,文章前半部在分析Java作者注释的时候我省去了一些东西没有说明,就是作者几次三番地提到了HashMap、HashTable。所以接下来我们带着疑问接着看HashMap类中存放数据的put方法,它实际调用putVal方法,以下是它的片段截取:

put一个键值对的时候1、2号框处流程大致进行了如下操作:
仅仅是通过哈希值相等来证明两个对象是相同对象是行不通的,需要再做进一步的证明,即上图2号红框中,为了证明两个对象是同一对象,我们要求(二者哈希值相等)且(二者地址值相等或调用equals认定相等)。
注意!这一整套流程出现问题了。结合上文,假设此处我们此处我们使用了String类型的值来作为Key值,且此String类重写了equals方法而未重写hashCode方法。
那么还是那个地址值不同而字面量相同的两个String对象s1与s2,由于未进行针对性地重写hashCode方法,那么hashCode还是通过地址值分别得到s1与s2的哈希值,他们显然是不同的。
0号红色框中的hash是传入Key的哈希值,它与HashMap底层数组tab的长度进行同位与运算得到的数组位置为最终目标节点在数组中的位置。也就是说即使我们输入了两个字面量完全相同的s1与s2,由于他们的地址值不同,得到的哈希值也不同,结果导致的是这个查出来的p节点始终为null(0号红色框处),也就是会执行操作–创建一个新的节点。
对应到我们put操作就相当于执行了hashMap.put(“k”,“v1”),hashMap.put(“k”:“v2”),而不是使用v2替换v1的值,这样我们的HashMap就乱套了。
虽然此处我们仅仅是进行了十分简陋且十分片面的证明,但是问题挖到了这里依然说明了相同对象拥有不同哈希值会造成不便。几乎可以肯定地说,hashCode方法不仅仅是与equals配套使用的,它甚至是与Java集合配套使用的。同样地,类似的代码我们也能在HashTable中找到,就更不用提HashSet一类的集合了。
集合本身在我们日常的编码中就必不可少,所以我们以后为了代码不出问题还是乖乖地重写hashCode方法吧。不过好在一般我们为了集合的效率以及安全性,都会使用不可变的String,它已经将hashCode方法重写了,并且重写的是一个散列极为优秀的hashCode方法,此处限于篇幅不展开聊。(END)