
之前我已经完成了使用langchain与你自己的数据对话的前四篇博客,还没有阅读这四篇博客的朋友可以先阅读一下:
- 使用langchain与你自己的数据对话(一):文档加载与切割
- 使用langchain与你自己的数据对话(二):向量存储与嵌入
- 使用langchain与你自己的数据对话(三):检索(Retrieval)
- 使用langchain与你自己的数据对话(四):问答(question answering)
今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第六门课:chat。
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
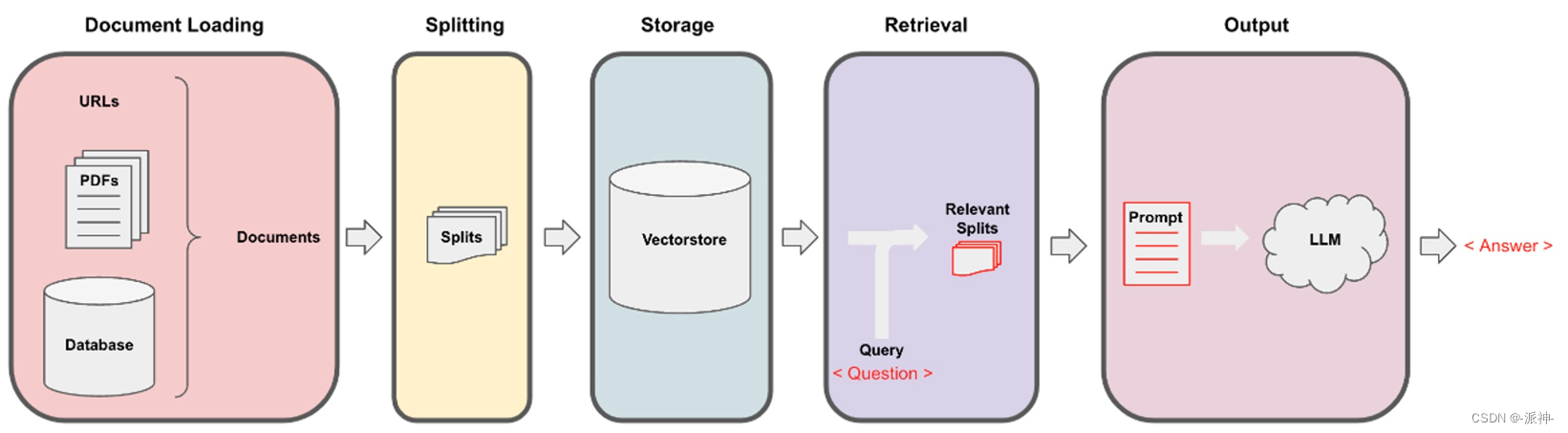
在前面的四篇博客中我们以及完成了这5给阶段所有的内容介绍,并在第四篇博客中我们还创建了RetrievalQA实现了对数据的问答功能,但是这里有一个小小的缺陷,那就是通过RetrievalQA实现的问答功能只能针对当前问题进行回答,它无法参考上下文来来回答问题,也就是说它没有记忆能力,无法实现连贯性聊。今天我们就来解决这个问题,我们会创建一个真正的个性化聊天机器人,它会学习用户提供的数据,并解答任何关于数据内容的问题,并且它具有记忆能力,能够实现真正的连贯性聊天。
在讨论聊天机器人之前之前,先让我们完成一些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')
import panel as pn # GUI
pn.extension()
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']先前内容回顾
之前我们介绍了Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output。下面我们通过代码来简单实现一下这5个阶段的功能:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
#加载本地向量数据库
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)
#搜索与问题相关的文档
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
#查看搜索结果中的文档数量
len(docs)
这里我们在向量数据库中搜索到3篇与问题相关的文档,下面我们查看一下这3篇文档:
docs 下面我们来创建RetrievalQA,同时我们加入一个prompt的模板,在该prompt我们要求llm尽量用简洁的语言来回答问题,并且不能编造答案,最后我们还要求llm在答案的结语上加上“thanks for asking!”,通过这个prompt模板llm能给出简洁的格式化的答案:
下面我们来创建RetrievalQA,同时我们加入一个prompt的模板,在该prompt我们要求llm尽量用简洁的语言来回答问题,并且不能编造答案,最后我们还要求llm在答案的结语上加上“thanks for asking!”,通过这个prompt模板llm能给出简洁的格式化的答案:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. \
If you don't know the answer, just say that you don't know, don't try to make up an answer. \
Use three sentences maximum. Keep the answer as concise as possible. \
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)
# Run chain
from langchain.chains import RetrievalQA
question = "Is probability a class topic?"
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0),
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})
result = qa_chain({"query": question})
result["result"] 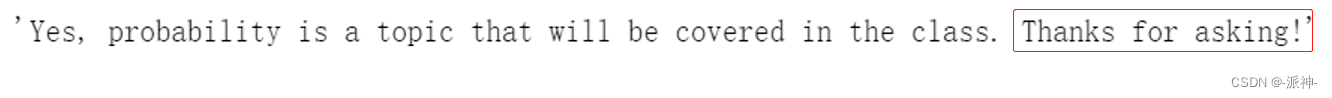
这里我们看到RetrievalQA返回了一个很简洁的答案,并在最后附加了“thanks for asking!”,这符合我们对它的要求。
ConversationalRetrievalChain
到目前为止我们已经创建好了RetrievalQA,可以实现对数据内容的问答,不过这里会有一个问题,就是通过RetrievalQA创建的检索问答链,它没有记忆功能,它无法记住之前用户已经提出过问题,所以RetrievalQA不能实现连贯性的聊天问答。为了解决这个功能,我们可以通过创建ConversationalRetrievalChain,它会存储每次聊天的历史记录,当LLM在回答当前问题的时候都会参考历史聊天记录,这样就可以实现连贯性的聊天:
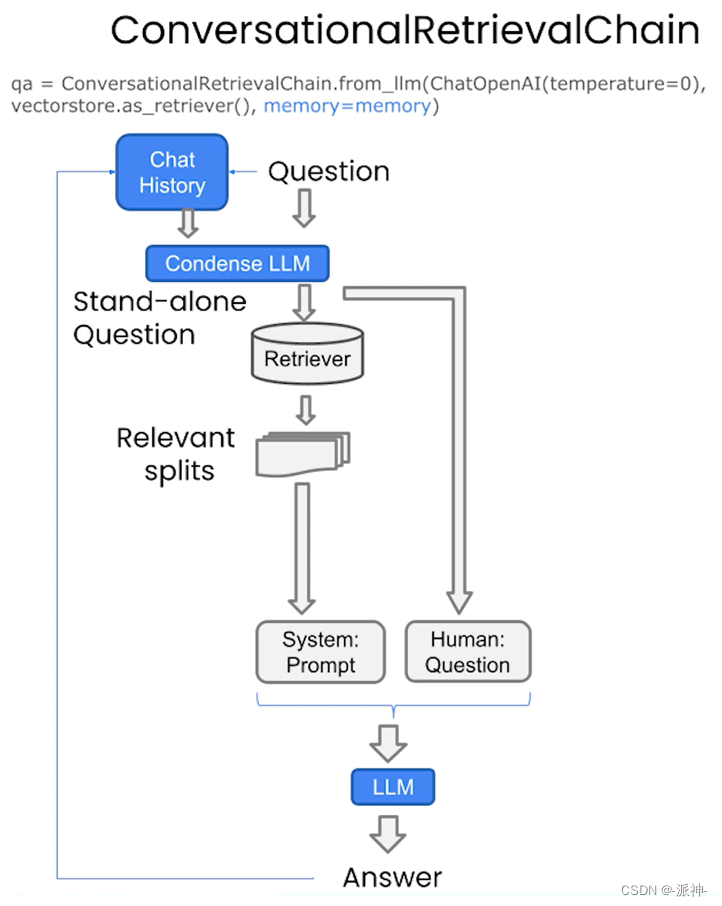
为了保存么此用户和LLM之间的聊天记录,我们需要创建一个ConversationBufferMemory组件,该组件会自动保存每一次用户和LLM之间对话记录。ConversationalRetrievalChain包含3给主要的参数:
- llm: 语言模型,这里我们使用openai的“gpt-3.5-turbo”模型
- retriever:检索器,这里我们由向量数据库来创建检索器
- memory:记忆力组件,这里我们使用ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
#创建memory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
#创建ConversationalRetrievalChain
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0),
retriever=vectordb.as_retriever(),
memory=memory
)这里我们创建了ConversationalRetrievalChain的实例qa,接下来我们来实现连贯性的聊天,我们首先向LLM提出一个问题:概率是这门课的主题吗?
question1="概率是这门课的主题吗?"
result = qa({"question": question1})
print(result['answer'])
接下来我们第二给问题:为什么需要先修课程呢?,这里需要说明的是该问题其实是衔接第一个问题的答案,如果我们的ConversationalRetrievalChain有记忆功能,那么它一定会知道这里的先修课程是指哪些课程,并且给出正确的回答:
question2 = "为什么需要先修课程呢?"
result = qa({"question": question2})
print(result['answer'])
这里我们向LLM提出了2个问题,第一个问题是:概率是这门课的主题吗?我们知道,我们的向量数据库中存储的是吴恩达老师著名的机器学习课程cs229的课程讲义,因此课程中涉及到了一些概率的基础知识,那么接下来提出的第二给问题:为什么需要先修课程呢?该问题其实是衔接第一个问题的答案,要回答该问题必须要知道这里的先修课程是指哪些课程,因为LLM在回答第一个问题的时候已经明确告知用户概率是这门课的一个主题,那么概率也就是这门课的先修课程,这里我们看到ConversationalRetrievalChain在回答第二给问题的时候已经参考了之前的历史聊天记录,因此它给出了合理的答案。
创建聊天机器人
下面我们把Langchain在实现与外部数据对话的功能的5个阶段所有的内容整合起来,然后建一个真正意义上的聊天机器人,这里我们在jupyter notebook中使用panel组件来创建一个GUI的聊天对话界面:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
import panel as pn
import param
def load_db(file, chain_type, k):
# load documents
loader = PyPDFLoader(file)
documents = loader.load()
# split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# define embedding
embeddings = OpenAIEmbeddings()
# create vector database from data
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# define retriever
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True)
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
cb = cbfs()
file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=300),
pn.layout.Divider(),
)
tab2= pn.Column(
pn.panel(cb.get_lquest),
pn.layout.Divider(),
pn.panel(cb.get_sources ),
)
tab3= pn.Column(
pn.panel(cb.get_chats),
pn.layout.Divider(),
)
tab4=pn.Column(
pn.Row( file_input, button_load, bound_button_load),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),
pn.layout.Divider(),
pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),
pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
#启动聊天应用程序
dashboard


总结
今天我们学习了如何开发一个具有记忆能力的个性化问答机器人,所谓个性化是指该机器人可以针对用户数据的内容进行问答,我们在实现该机器人时使用了ConversationalRetrievalChain组件,它是一个具有记忆能力的检索链,也是机器人的核心组件。希望今天的内容对大家有所帮助!