/* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/
author: 张俊林
(想更系统地学习深度学习知识?请参考:深度学习枕边书)
聊天机器人(也可以称为语音助手、聊天助手、对话机器人等)是目前非常热的一个人工智能研发与产品方向。很多大的互联网公司重金投入研发相关技术,并陆续推出了相关产品,比如苹果Siri、微软Cortana与小冰、Google Now、百度的“度秘”、亚马逊的蓝牙音箱Amazon Echo内置的语音助手Alexa、Facebook推出的语音助手M、Siri创始人推出的新型语音助手Viv…….
为何老牌互联网公司和很多创业公司都密集地在聊天机器人领域进行投入?其实根本原因在于大家都将聊天机器人定位为未来各种服务的入口,尤其是移动端APP应用及可穿戴设备场景下提供各种服务的服务入口,这类似于Web端搜索引擎的入口作用。将来很可能通过语音助手绕过目前的很多APP直接提供各种服务,比如查询天气、定航班、订餐、智能家居的设备控制、车载设备的语音控制等等,目前大多采用独立APP形式来提供服务,而将来很多以APP形式存在的应用很可能会消失不见,直接隐身到语音助手背后。作为未来各种应用服务的入口,其市场影响力毫无疑问是巨大的,这是为何这个方向如此火热的根本原因,大家都在为争夺未来服务入口而提前布局与竞争,虽然很多公司并未直接声明这个原因,但其目的是显而易见的。
|聊天机器人的类型
目前市场上有各种类型的机器人,比如有京东JIMI这种客服机器人,儿童教育机器人,小冰这种娱乐聊天机器人,Aexa这种家居控制机器人、车载控制机器人、Viv这种全方位服务类型机器人等等。这是从应用方向角度来对聊天机器人的一种划分。
如果对其应用目的或者技术手段进行抽象,可以有以下两种划分方法。
-
目标驱动(Goal –Driven)VS 无目标驱动(Non-Goal Driven)聊天机器人
目标驱动的聊天机器人指的是聊天机器人有明确的服务目标或者服务对象,比如客服机器人,儿童教育机器人、类似Viv的提供天气订票订餐等各种服务的服务机器人等;这种目标驱动的聊天机器人也可以被称作特定领域的聊天机器人。
无目标驱动聊天机器人指的是聊天机器人并非为了特定领域服务目的而开发的,比如纯粹聊天或者出于娱乐聊天目的以及计算机游戏中的虚拟人物的聊天机器人都属于此类。这种无明确任务目标的聊天机器人也可以被称作为开放领域的聊天机器人。
-
检索式 VS 生成式聊天机器人
检索式聊天机器人指的事先存在一个对话库,聊天系统接收到用户输入句子后,通过在对话库中以搜索匹配的方式进行应答内容提取,很明显这种方式对对话库要求很高,需要对话库足够大,能够尽量多地匹配用户问句,否则会经常出现找不到合适回答内容的情形,因为在真实场景下用户说什么都是可能的,但是它的好处是回答质量高,因为对话库中的内容都是真实的对话数据,表达比较自然。
生成式聊天机器人则采取不同的技术思路,在接收到用户输入句子后,采用一定技术手段自动生成一句话作为应答,这个路线的机器人的好处是可能覆盖任意话题的用户问句,但是缺点是生成应答句子质量很可能会存在问题,比如可能存在语句不通顺存在句法错误等看上去比较低级的错误。
本文重点介绍开放领域、生成式的聊天机器人如何通过深度学习技术来构建,很明显这是最难处理的一种情况。
|好的聊天机器人应该具备的特点
一般而言,一个优秀的开放领域聊天机器人应该具备如下特点:
首先,针对用户的回答或者聊天内容,机器人产生的应答句应该和用户的问句语义一致并逻辑正确,如果聊天机器人答非所问或者不知所云,亦或老是回答说“对不起,我不理解您的意思”,对于聊天机器人来说无疑是毁灭性的用户体验。
其次,聊天机器人的回答应该是语法正确的。这个看似是基本要求,但是对于采用生成式对话技术的机器人来说其实要保证这一点是有一定困难的,因为机器人的回答是一个字一个字生成的,如何保证这种生成的若干个字是句法正确的其实并不容易做得那么完美。
再次,聊天机器人的应答应该是有趣的、多样性的而非沉闷无聊的。尽管有些应答看上去语义上没有什么问题,但是目前技术训练出的聊天机器人很容易产生“安全回答”的问题,就是说,不论用户输入什么句子,聊天机器人总是回答“好啊”、“是吗”等诸如此类看上去语义说得过去,但是这给人很无聊的感觉。
还有,聊天机器人应该给人“个性表达一致”的感觉。因为人们和聊天机器人交流,从内心习惯还是将沟通对象想象成一个人,而一个人应该有相对一致的个性特征,如果用户连续问两次“你多大了”,而聊天机器人分别给出不同的岁数,那么会给人交流对象精神分裂的印象,这即是典型的个性表达不一致。而好的聊天机器人应该对外体现出各种基本背景信息以及爱好、语言风格等方面一致的回答。
|几种主流技术思路
随着技术的发展,对于聊天机器人技术而言,常见的几种主流技术包括:基于人工模板的聊天机器人、基于检索的聊天机器人、基于机器翻译技术的聊天机器人、基于深度学习的聊天机器人。
基于人工模板的技术通过人工设定对话场景,并对每个场景写一些针对性的对话模板,模板描述了用户可能的问题以及对应的答案模板。这个技术路线的好处是精准,缺点是需要大量人工工作,而且可扩展性差,需要一个场景一个场景去扩展。应该说目前市场上各种类似于Siri的对话机器人中都大量使用了人工模板的技术,主要是其精准性是其他方法还无法比拟的。
基于检索技术的聊天机器人则走的是类似搜索引擎的路线,事先存储好对话库并建立索引,根据用户问句,在对话库中进行模糊匹配找到最合适的应答内容。
基于机器翻译技术的聊天机器人把聊天过程比拟成机器翻译过程,就是说将用户输入聊天信息Message,然后聊天机器人应答Response的过程看做是把Message翻译成Response的过程,类似于把英语翻译成汉语。基于这种假设,就完全可以将统计机器翻译领域里相对成熟的技术直接应用到聊天机器人开发领域来。
基于深度学习的聊天机器人技术是本文后续内容主要介绍的技术路线,总体而言,绝大多数技术都是在Encoder-Decoder(或者称作是Sequence to Sequence)深度学习技术框架下进行改进的。使用深度学习技术来开发聊天机器人相对传统方法来说整体思路是非常简单可扩展的。
|深度学习构建聊天机器人
如上所述,目前对于开放领域生成式聊天机器人技术而言,多数技术采用了Encoder-Decoder框架,所以本节首先描述Encoder-Decoder框架技术原理。然后分别针对聊天机器人研究领域需要特殊考虑的主要问题及其对应的解决方案进行讲解,这些主要问题分别是:多轮会话中的上下文机制问题、“安全回答”问题以及个性信息一致性问题。
-
Encoder-Decoder框架
Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,应用场景异常广泛,不仅仅可以用在对话机器人领域,还可以应用在机器翻译、文本摘要、句法分析等各种场合。下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:
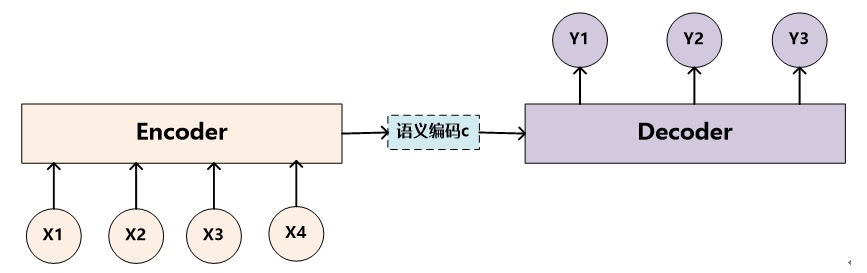
图1. 抽象的Encoder-Decoder框架
Encoder-Decoder框架可以如此直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<X,Y>,我们的目标是给定输入句子X,期待通过Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。而X和Y分别由各自的单词序列构成:
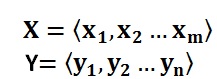
Encoder顾名思义就是对输入句子X进行编码,将输入句子通过非线性变换转化为中间语义表示C:
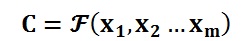
对于解码器Decoder来说,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息来生成i时刻要生成的单词yi:
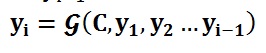
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
对于聊天机器人来说,完全可以使用上述的Encoder-Decoder框架来解决技术问题。具体而言,对应的<X,Y>中,X指的是用户输入语句,一般称作Message,而Y一般指的是聊天机器人的应答语句,一般称作Response。其含义是当用户输入Message后,经过Encoder-Decoder框架计算,首先由Encoder对Message进行语义编码,形成中间语义表示C,Decoder根据中间语义表示C生成了聊天机器人的应答Response。这样,用户反复输入不同的Message,聊天机器人每次都形成新的应答Response,形成了一个实际的对话系统。
在实际实现聊天系统的时候,一般Encoder和Decoder都采用RNN模型,RNN模型对于文本这种线性序列来说是最常用的深度学习模型,RNN的改进模型LSTM以及GRU模型也是经常使用的模型,对于句子比较长的情形,LSTM和GRU模型效果要明显优于RNN模型。尽管如此,当句子长度超过30以后,LSTM模型的效果会急剧下降,一般此时会引入Attention模型,这是一种体现输出Y和输入X句子单词之间对齐概率的神经网络模型,对于长句子来说能够明显提升系统效果。
文献1和文献2都较早采用Encoder-Decoder模型来建立对话机器人,一般的做法是采用收集Twitter或者微博中评论里的聊天信息来作为训练数据,用大量的此类聊天信息来训练Encoder-Decoder模型中RNN对应的神经网络连接参数。图2展示了利用微博评论对话数据训练好的聊天机器人的聊天效果,其中Post列指的是用户输入Message,其后三列是不同Encoder-Decoder方法产生的应答Response,而最后一列是基于传统检索方法的输出应答。
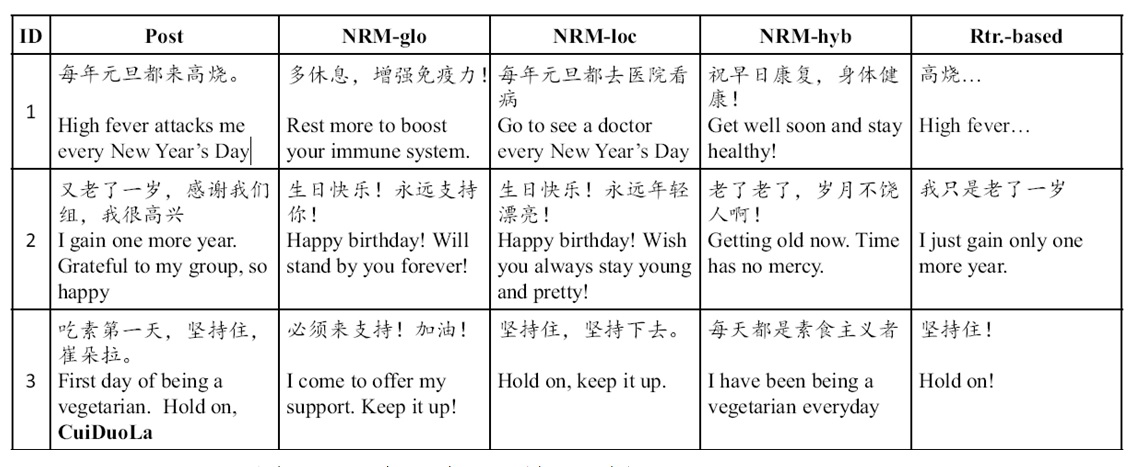
图2. 聊天机器人聊天效果示例
-
多轮会话中的上下文问题
上述Encoder-Decoder框架可以根据用户当前输入Message,聊天机器人自动生成应答Response,形成了一个有效的对话系统。但是一般人们聊天并不是单纯的一问一答,在回答的时候到底说什么内容常常要参考上下文Context信息,所谓对话上下文Context,也就是在用户当前输入问句Message之前两者的对话信息,因为存在多轮的一问一答,这种情形一般称为多轮会话。在多轮会话中,一般将上下文称作Context,当前输入称为Message,应答称作Response。
深度学习来解决多轮会话的关键是如何将上下文聊天信息Context引入到Encoder-Decoder模型中去的问题。很明显,上下文聊天信息Context应该引入到Encoder中,因为这是除了当前输入Message外的额外信息,有助于Decoder生成更好的会话应答Response内容。目前不同的研究主体思路都是这样的,无非在如何将Context信息在Encoder端建立模型或者说具体的融入模型有些不同而已。
在上文所述的Encoder-Decoder框架中,很容易想到一种直观地将Context信息融入Encoder的思路:无上下文信息的Encoder-Decoder模型的输入仅仅包含Message,只需要把上下文信息Context和信息Message拼接起来形成一个长的输入提供给Encoder,这样就把上下文信息融入模型中了。这个直觉本身其实是没有什么问题的,但是对于采用RNN模型的Encoder来说会存在如下问题:因为输入是历史上下文Context加上当前输入Message构成的,有时候输入会非常长,而众所周知,对于RNN模型来说,如果输入的线型序列长度越长,模型效果越差。所以这样简单地拼接Context和Message的策略明显不会产生太好的聊天效果。
考虑到RNN对长度敏感的问题,文献3提出了针对聊天机器人场景优化的Encoder-Decoder模型,核心思想是将Encoder用多层前向神经网络来代替RNN模型,神经网络的输出代表上下文信息Context和当前输入Message的中间语义表示,而Decoder依据这个中间表示来生成对话Response。这样做既能够将上下文信息Context和当前输入语句Message通过多层前向神经网络编码成Encoder-Decoder模型的中间语义表达,又避免了RNN对于过长输入敏感的问题。图3和图4是论文中提出的两种不同的融合方法,方法1对Context和Message不做明显区分,直接拼接成一个输入;而方法2则明确区分了Context和Message,在前向神经网络的第一层分别对其进行编码,拼接结果作为深层网络后续隐层的输入,核心思想是强调Message的作用,这个道理上是很好理解的,因为毕竟Response是针对Message的应答,Context只是提供了背景信息,所以应该突出Message的作用。
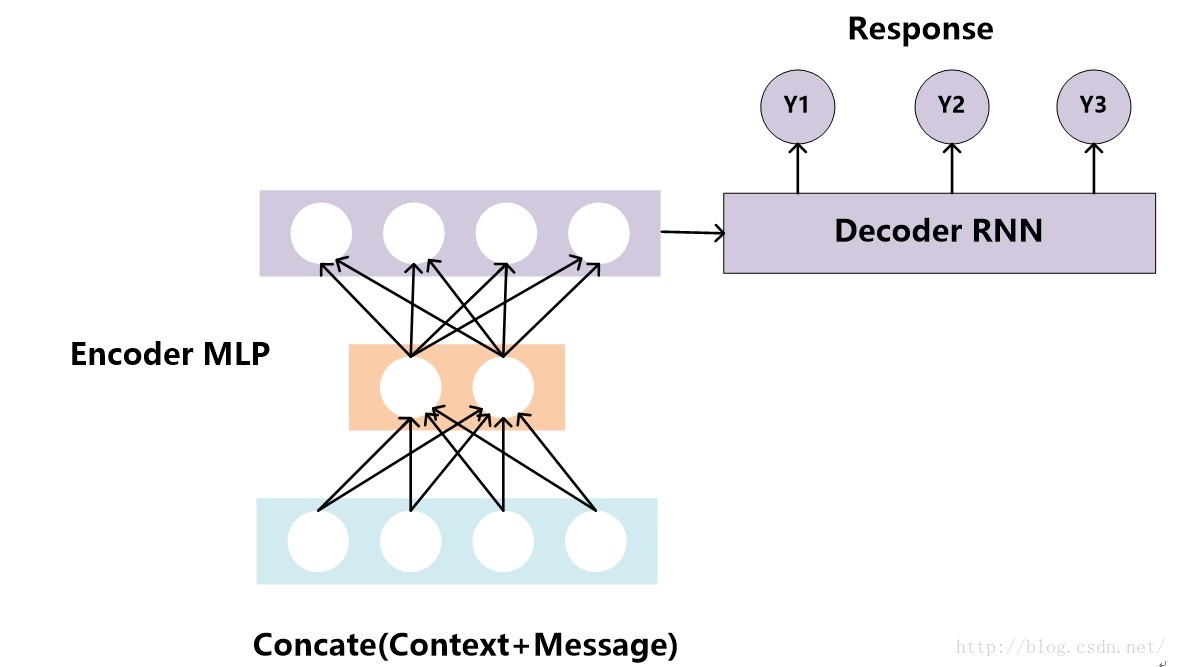
图3. 融合方法1
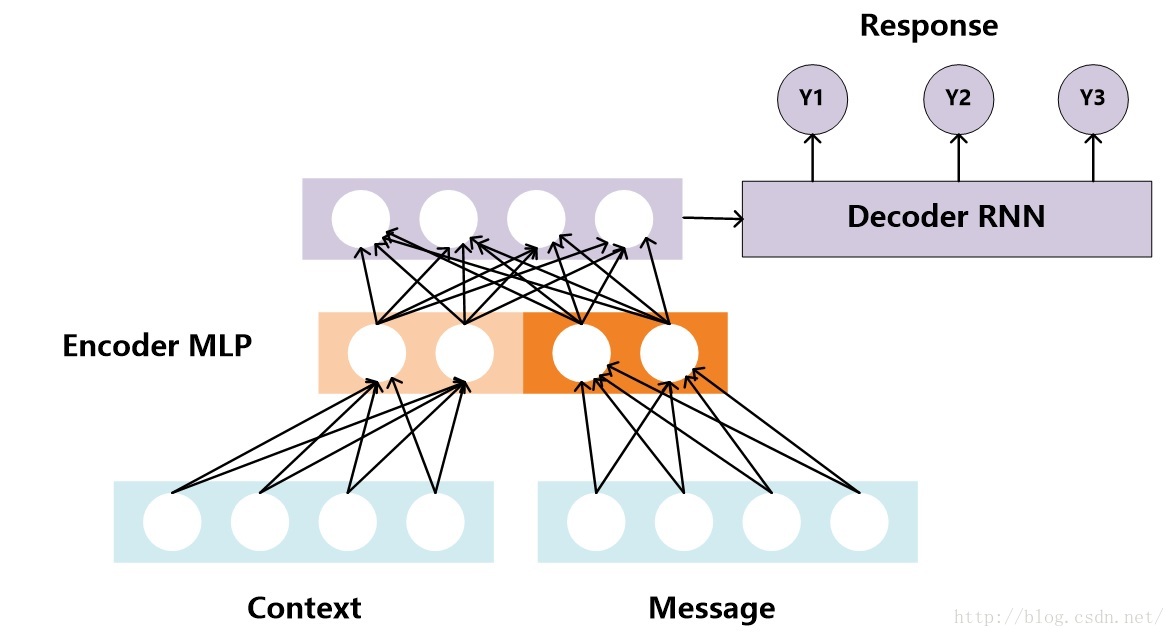
当然,除了Encoder从RNN替换为深层前向神经网络外,文献3与传统Encoder-Decoder还有一个显著区别,就是Decoder的RNN模型每个时刻t在输出当前字符的时候,不仅仅依赖t-1时刻的隐层状态和当前输入,还显示地将Encoder的中间语义编码直接作为t时刻RNN节点的输入,而不是像经典Encoder-Decoder模型那样把中间语义编码当做Decoder中RNN的最初输入。其出发点其实也是很直观的,就是在生成每个输出字符的时候反复强化中间语义编码的作用,这对于输出应答Response较长的时候无疑是有帮助作用的。
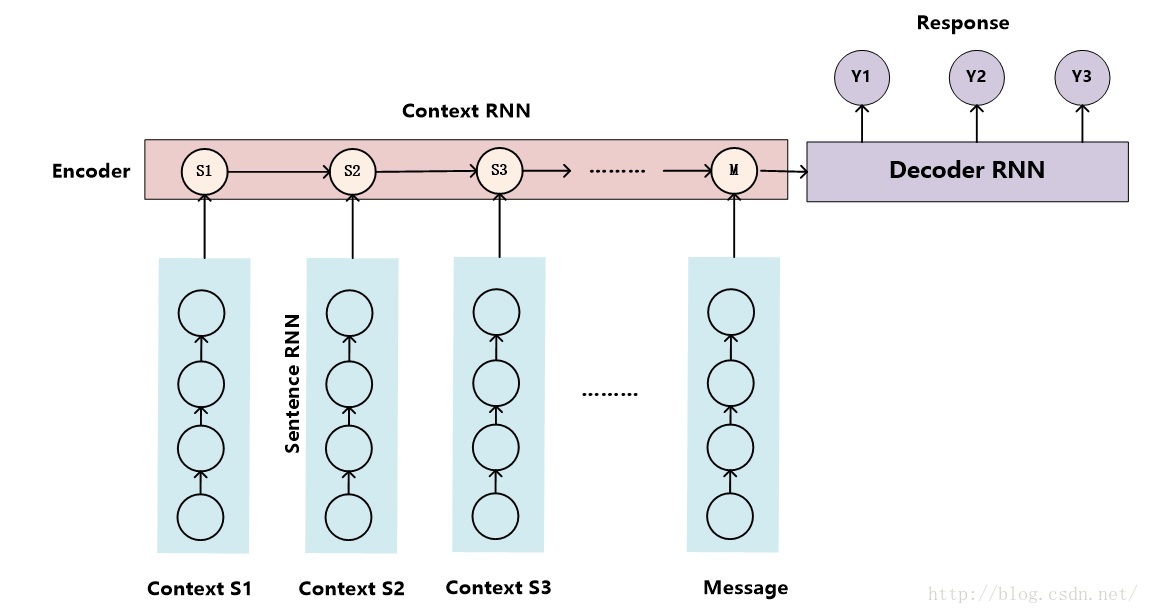
图5. 层级神经网络
文献4给出了解决多轮会话上下文问题的另外一种思路(如图5所示),被称作层级神经网络(Hierarchical Neural Network,简称HNN)。HNN本质上也是Encoder-Decoder框架,主要区别在于Encoder采用了二级结构,上下文Context中每个句子首先用“句子RNN(Sentence RNN)”对每个单词进行编码形成每个句子的中间表示,而第二级的RNN则将第一级句子RNN的中间表示结果按照上下文中句子出现先后顺序序列进行编码,这级RNN模型可被称作“上下文RNN(Context RNN)”,其尾节点处隐层节点状态信息就是所有上下文Context以及当前输入Message的语义编码,以这个信息作为Decoder产生每个单词的输入之一,这样就可以在生成应答Response的单词时把上下文信息考虑进来。
综上所述可以看出,深度学习解决多轮会话的上下文信息问题时大致思路相同,都是在Encoder阶段把上下文信息Context及当前输入Message同时编码,以促进Decoder阶段可以参考上下文信息生成应答Response。
-
如何解决“安全回答”(Safe Response)问题
如果采用经典的Encoder-Decoder模型构建开放领域生成式聊天机器人系统,一个比较容易产生的严重问题就是“安全回答”问题。什么是安全回答问题呢?就是说不论用户说什么内容,聊天机器人都用少数非常常见的句子进行应答,比如英文的“I don’t know”、“Come on”、“I’m OK”,中文的“是吗”、“呵呵”等。虽然说在很多种情况下这么回答也不能说是错误的,但是可以想象,如果用户遇到这样一位聊天对象会有多抓狂。这个现象产生的主要原因是聊天训练数据中确实很多回答都是这种宽泛但是无意义的应答,所以通过Encoder-Decoder模型机器人学会这种常见应答模式。如何解决聊天机器人“安全回答”问题,让机器产生多样化的应答是个很重要的课题。
文献5即在Sequence-to-Sequence框架下来解决“安全回答”问题。在聊天场景下,传统的使用Sequence-to-Sequence框架来进行模型训练时,其优化目标基本上是最大似然法(MLE),就是说给定用户输入Message,通过训练来最大化生成应答Response的概率:
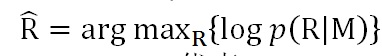
其中M代表message,R代表Response;
文献5提出了改进的优化目标函数:最大化互信息(MMI),其目标函数如下:
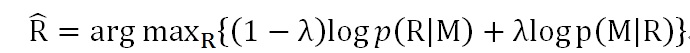
可以从公式差异中看出,MMI的优化目标除了最大化从Message生成应答Response的概率,同时加入了反向优化目标,即最大化应答Response产生Message的概率,其中lamda是控制两者哪个更重要的调节超参数。通过其名字“互信息”以及具体公式可以看出,这个优化目标函数要求应答Response和Message内容密切相关而不仅仅是考虑哪个Response更高概率出现,所以降低了那些非常常见的回答的生成概率,使得应答Response更多样化且跟Message语义更相关。
采用MMI作为目标函数明显解决了很多“安全回答”问题,表一是两个不同优化目标函数产生的应答Response的示例,其中Message列代表用户输入语句Message,S2S Response代表MLE优化目标产生的应答,MMI Response代表MMI优化目标产生的应答。
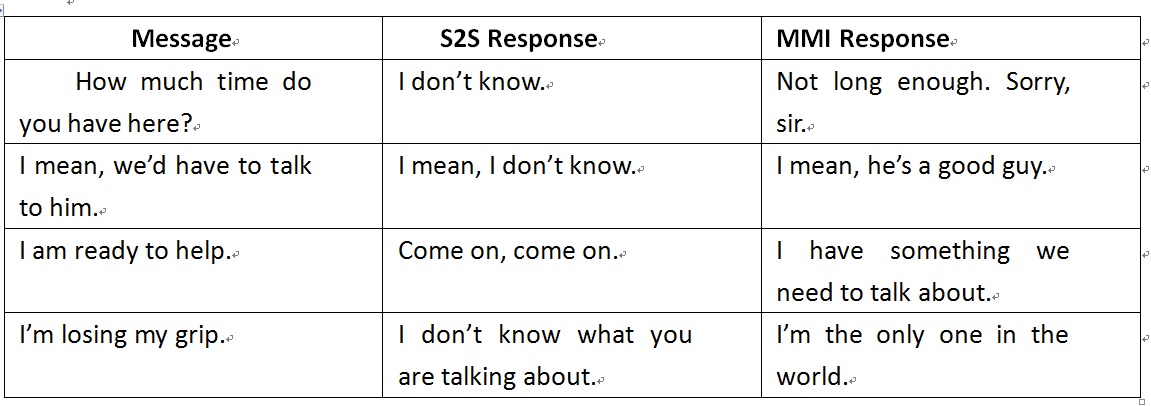
表1 S2S与MMI产生的应答
-
个性信息一致性问题
对于聊天助手等应用来说,聊天机器人往往会被用户当做一个具有个性化特性的虚拟人,比如经常会问:“你多大了”、“你的爱好是什么”、“你是哪里人啊”等。如果将聊天助手当做一个虚拟人,那么这位虚拟人相关的个性化信息比如年龄、性别、爱好、语言风格等个性特征信息应该维护回答的一致性。利用经典的Sequence-to-Sequence模型训练出的聊天助手往往很难保持这种个性信息的一致性(不一致的例子请参考图6),这是因为Sequence-to-Sequence模型训练的都是单句Message对单句Response的映射关系,内在并没有统一维护聊天助手个性信息的场所,所以并不能保证每次相同的问题能够产生完全相同的应答。另外,对于海量用户来说,可能不同的用户会喜欢不同聊天风格或者不同身份的聊天助手,所以聊天机器人应该能够提供不同身份和个性信息的聊天助手,不同类型用户可以采用相应类型的聊天助理来聊天,当然,在聊天过程中要尽量保持身份和个性信息的一致性。
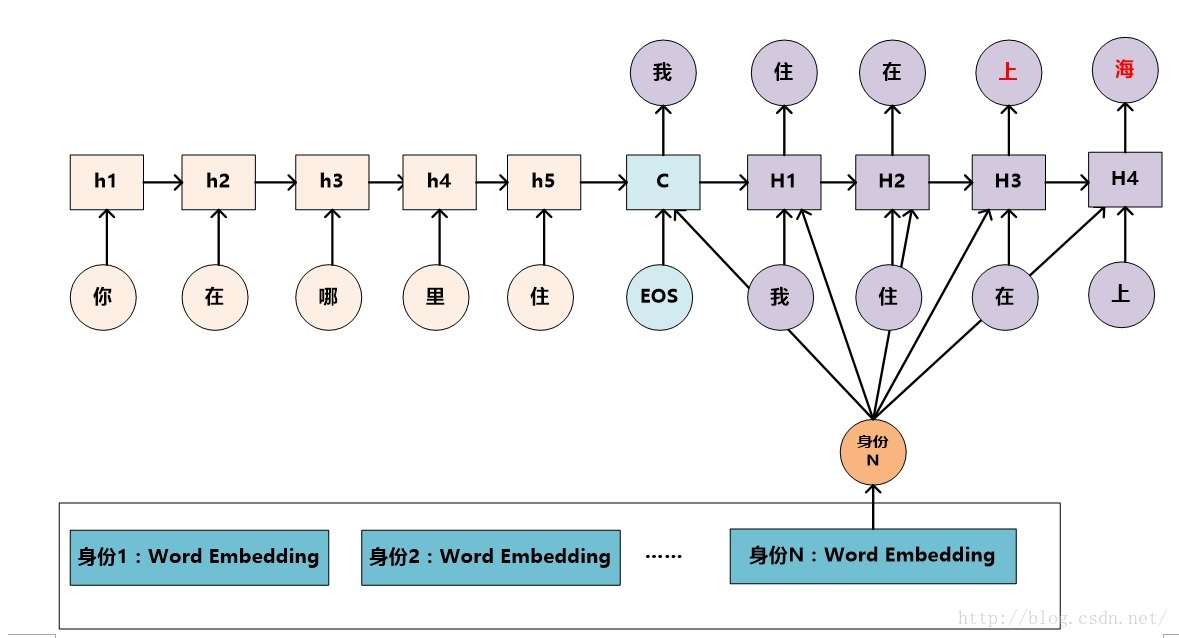
图7. 一种Sequence-to-Sequence框架下维护聊天助手个性一致化的方案
那么如何在Sequence-to-Sequence框架下采用技术手段维护聊天助手的个性一致性呢?文献6给出了一种比较典型的解决方案。参照文献6,我们可以改造出一个能够实现不同身份个性特征的聊天助手的思路。图7是其示意图。(注意:本文叙述的并非文献6中的原始场景,而是本文作者参照文献稍作修正的技术方案)
其基本思路如下:聊天机器人系统可以定义不同身份和个性及语言风格的聊天助理身份,个性化信息通过Word Embedding的表达方式来体现,在维护聊天助手个性或身份一致性的时候,可以根据聊天对象的风格选择某种风格身份的聊天助手。整体技术框架仍然采用Sequence-to-Sequence架构,其基本思路是把聊天助手的个性信息导入到Decoder的输出过程中,就是说在采用RNN的Decoder生成应答Response的时候,每个t时刻,神经网络节点除了RNN标准的输入外,也将选定身份的个性化Word Embedding信息一并作为输入。这样就可以引导系统在输出时倾向于输出符合身份特征的个性化信息。
上述是一种深度学习框架下维护聊天助手个性一致性的技术框架,很明显还可以衍生出很多种其它方案,但是其技术思路应该是类似的,核心思想是把聊天助手的个性信息在Decoder阶段能够体现出来,以此达到维护个性一致性的目的。
上述内容介绍了使用深度学习构建聊天机器人采用的主体技术框架以及面临的一些独特问题及相应的解决方案,除此外,还有一些问题值得探讨,比如如何使得聊天机器人有主动引导话题的能力,因为一般聊天机器人都比较被动,话题往往都是由用户发起和引导,聊天机器人只是作为应答方,很少主动引导新话题,而这很容易导致聊天冷场,所以如何主动引导话题也是聊天机器人应该具备的能力之一,文献7提出了一种技术方案,此处不赘述,感兴趣的读者可自行参考。
|深度学习聊天机器人的优点与需要改进的方向
相对基于检索类或者机器翻译类传统技术而言,基于Encoder-Decoder深度学习框架的聊天机器人具有如下明显优点:
-
构建过程是端到端(End-to-End)数据驱动的,只要给定训练数据即可训练出效果还不错的聊天系统,省去了很多特征抽取以及各种复杂中间步骤的处理,比如省去句法分析与语义分析等传统NLP绕不开的工作,使得系统开发效率大幅提高;
-
语言无关,可扩展性强。对于开发不同语言的聊天机器人来说,如果采用Encoder-Decoder技术框架,只需要使用不同语言的聊天数据进行训练即可,不需要专门针对某种语言做语言相关的特定优化措施,这使得系统可扩展性大大加强;
-
训练数据扩大有助于持续提升系统效果。对于Encoder-Decoder深度学习模型来说,一般来说,通过不断增加训练数据能够带来持续的效果提升。
当然,开发出具备像人一样能够自然交流的聊天机器人目前还面临着各种技术难题需要克服,具体到使用深度学习技术来构建聊天机器人来说,目前在以下几个方面还需大力加强:
-
聊天机器人的评价标准。如何评价聊天机器人效果质量的评价标准对于持续提升系统是至关重要的,因为只有这样才能目标明确地去有针对性地设计技术方案进行改进。聊天机器人在评价标准方面还有待深入研究,目前常用的标准包括机器翻译的评价指标BLEU、语言模型评价标准困惑度等,还有很多工作是通过人工来进行效果评价,还没有特别合适地专用于聊天机器人的评价标准,这是阻碍聊天机器人技术持续发展的一个障碍。
-
缺乏标准化的大规模训练数据。就像上述深度学习模型优点所述,训练数据的不断增加一般能够带来性能的持续提升。但是目前来说,标准化的特大规模的人与人对话数据相对缺乏,很多研究都是通过Twitter或者微博评论等高成本的采集方式来收集对话训练数据,或者使用电影字幕等比较间接的方式来积累训练数据。如果能够有大规模的标准聊天数据,很明显将能够极大提升技术进步。
-
技术仍处于发展初期。很明显采用深度学习来进行聊天机器人的技术研发还处于非常初期的阶段,从技术手段也好,亦或是实际系统效果也好,都有非常大的进步空间。
参考文献:
[1]Lifeng Shang, Zhengdong Lu, and Hang Li.2015. Neural responding machine for short-text conversation. In ACL-IJCNLP,pages 1577–1586.
[2] Oriol Vinyals and Quoc Le. 2015. Aneural conversational model. In Proc. of ICML Deep Learning Workshop.
[3] Alessandro Sordoni, Michel Galley,Michael Auli, ChrisBrockett, Yangfeng Ji, Meg Mitchell, Jian-Yun Nie,JianfengGao, and Bill Dolan. 2015. A neural network approach to context-sensitivegeneration of conversational responses. In Proc. of NAACL-HLT.
[4] Iulian V Serban, Alessandro Sordoni,Yoshua Bengio,Aaron Courville, and Joelle Pineau. 2015. Building end-to-enddialogue systems using generative hierarchical neural network models. In Proc.of AAAI.
[5]Jiwei Li, Michel Galley, Chris Brockett,Jianfeng Gao,and Bill Dolan. 2015. A diversity-promoting objective function forneural conversation models. arXiv preprint arXiv:15
[6] Jiwei Li, Michel Galley, ChrisBrockett, Jianfeng Gao and Bill Dolan. A Persona-Based Neural ConversationModel. arXiv preprint arXiv:16
[7] Xiang Li,Lili Mou,Rui Yan and MingZhang. StalemateBreaker: A Proactive Content-Introducing Approach to AutomaticHuman-Computer Conversation.IJCAI 2016.
