LN论文:https://arxiv.org/pdf/1607.06450.pdf
在cnn和transformer架构中分别采用了两种不同的归一化方法,明白二者的区别有助于我们加深对深度学习模型的理解。
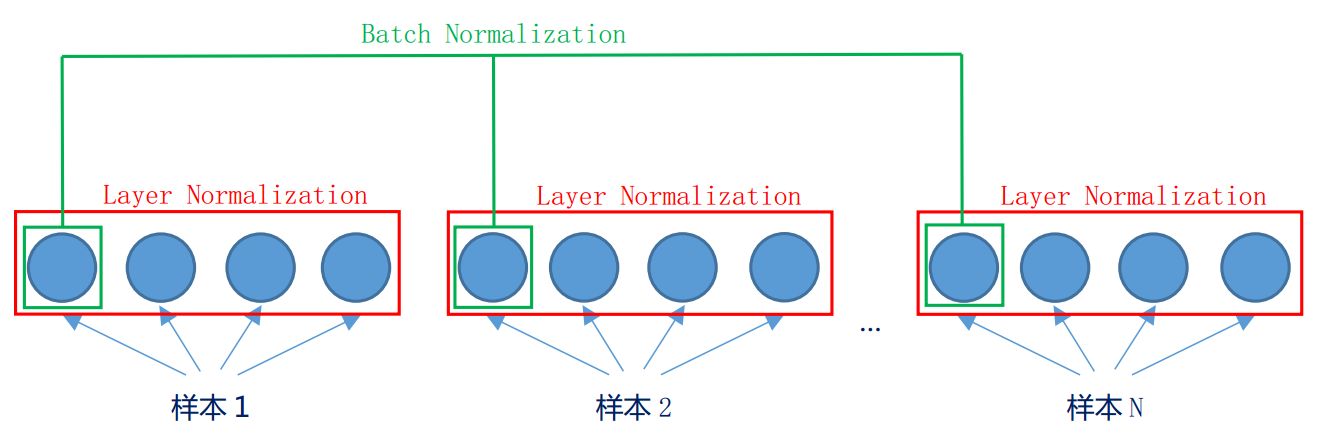
一、图示两种方式的不同
LN:Layer Normalization,LN是“横”着来的,对一个样本,不同的神经元neuron间做归一化。
BN:Batch Normalization,BN是“竖”着来的,各个维度做归一化,所以与batch size有关系。
二者提出的目的都是为了加快模型收敛,减少训练时间。
二、BN解决网络中的Convariate Shift问题
批标准化(Bactch Normalization,BN)是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanishing Gradient Problem)。
统计机器学习中有一个经典的假设:Source Domain 和 Target Domain的数据分布是一致的。也就是说,训练数据和测试数据是满足相同分布的。这是通过训练数据获得的模型能够在测试集上获得好的效果的一个基本保障。
Convariate Shift是指训练集的样本数据和目标样本集分布不一致时,训练得到的模型无法很好的Generalization。它是分布不一致假设之下的一个分支问题,也就是指Sorce Domain和Target Domain的条件概率一致的,但是其边缘概率不同。的确,对于神经网络的各层输出,在经过了层内操作后,各层输出分布就会与对应的输入信号分布不同,而且差异会随着网络深度增大而加大了,但每一层所指向的Label仍然是不变的。
解决办法:一般是根据训练样本和目标样本的比例对训练样本做一个矫正。所以,通过引入Bactch Normalization来标准化某些层或者所有层的输入,从而固定每层输入信息的均值和方差。
方法:Bactch Normalization一般用在非线性映射(激活函数)之前,对x=Wu+b做标准化,是结果(输出信号各个维度)的均值为0,方差为1。让每一层的输入有一个稳定的分布会有利于网络的训练。
优点:Bactch Normalization通过标准化让激活函数分布在线性区间,结果就是加大了梯度,让模型更大胆的进行梯度下降,具有如下优点:
- 加大搜索的步长,加快收敛的速度;
- 更容易跳出局部最小值;
- 破坏原来的数据分布,一定程度上缓解了过拟合
因此,在遇到神经网络收敛速度很慢或梯度爆炸(Gradient Explore)等无法训练的情况系啊,都可以尝试用Bactch Normalization来解决。
三、BN的缺陷
1、BN是在batch size样本上各个维度做标准化的,所以size越大肯定越能得出合理的μ和σ来做标准化,因此BN比较依赖size的大小。
2、在训练的时候,是分批量进行填入模型的,但是在预测的时候,如果只有一个样本或者很少量的样本来做inference,这个时候用BN显然偏差很大,例如在线学习场景。
3、RNN是一个动态的网络,也就是size是变化的,可大可小,造成多样本维度都没法对齐,所以不适合用BN。
四、LN带来的优势:
1、Layer Normalization是每个样本内部做标准化,跟size没关系,不受其影响。
2、RNN中LN也不受影响,内部自己做标准化,所以LN的应用面更广。