Apache Hive概述
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hivev查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行。
Hive由Facebook实现并开源。
使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力
避免直接写MapReduce,减少开发人员的学习成本
支持自定义函数,功能扩展很方便
背靠Hadoop,擅长存储分析海量数据集
用户专注于编写HQL,Hive将其转换成MapReduce程序完成对数据的分析
1.Apache Hive架构、组件
1.1 组件
用户接口
包括CLI、JDBC/ODBV、WrbGUI
元数据存储
通常是存储在关系数据库如mysql/derby中。
Driver驱动程序
包括语法解析器、计划编译器、优化器、执行器
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3三种执行引擎
1.2 Hive数据模型
Data Model概念
数据模型:用来秒数数据、组织数据和对数据进行操作,是对现实世界数据特征的描述
Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型
Hive中的数据可以在粒度级别上分为三类:表、分区、分桶
数据库
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse
Hive和MySQL对比
| Apache Hive | Mysql | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR。Tez、Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据、查询 | 增删改查 |
1.3 元数据
Hive Metadata
元数据就是描述数据的数据。
Hive元数据就是表和文件之间的各种对应关系
Hive元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过链接metastore服务,由metastore再去连接MySQL再去连接MySQL数据库来存取元数据。
metastore配置方式
metastore服务配置有3中模式:内嵌模式、本地模式、远程模式(推荐)
| 内嵌模式 | 地址模式 | 远程模式 | |
|---|---|---|---|
| Metastore单独配置、启动 | 否 | 否 | 是 |
| Metadata存储介质 | Derby | Mysql | Mysql |
1.4 Hive部署实战(未操作)
安装前准备
- 服务器基础环境:集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装
- Hadoop集权健康可用:启动Hive之前必须先启动Hadoop集群。特别要注意,徐等待HDFS安全模式关闭之后在运行Hive
Hadoop与Hive整合
因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据
因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行
修改Hadoop中core-site.xml,并且hadoop集群同步配置文件,重启生效
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
内嵌模式
内嵌模式特征:不需要安装数据库,不需要配置启动Metastore服务,解压安装包初始化即可测试Hive
本地模式
本地模式特征:需要安装数据库MySQL来存储元数据,但是不需要配置启动Metastore服务。
远程模式
特点:需要安装MySQL来存储Hive元数据,需要单独配置启动Metastore服务
1.5 Hive命令行客户端
bin/hive、bin/beeline
第一代: H I V E H O M E / b i n / h i v e ,不推荐使用第二代: HIVE_HOME/bin/hive,不推荐使用 第二代: HIVEHOME/bin/hive,不推荐使用第二代:HIVE_HOME/bin/beeline,官方推荐使用,更安全
Beeline在嵌入式和全程模式下均可工作
在嵌入式模式下,它运行嵌入式Hive;远程模式下beeline通过Thrift连接到单独的HiveServer2服务上。
HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI(命令行)的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python项hive提交请求,取回结果。
HiveServer已经废弃,HiveServer2支持多客户端的并发和身份认证,旨在未开放API客户端如JDBC/ODBC提供更好的支持。
关系梳理
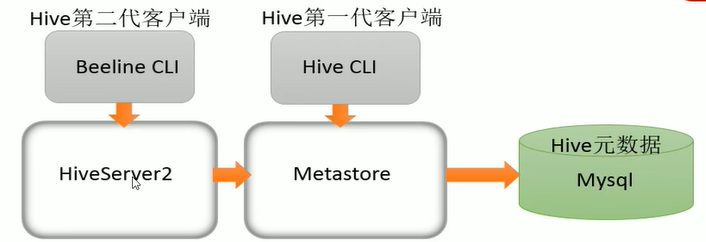
Bin/hive客户端使用只需启动Metastore,而使用bin/beeline启动HiveServer2之前必须先启动metastore
1.6 Hive初体验
Hive使用和MySQL的差别
- Hive SQL语法和标准SQL很类似,使得学习成本降低不少
- Hive底层是通过MapReduce执行的数据插入动作,所以速度很慢
- 如果大数据集一条一条插入的话非常不显示的,成本极高
- Hive应该具有自己特有的数据插入方式,结构化文件映射成表
Hive将结构话数据映射成为表
在Hive中创建表跟结构化文件映射成功,需要注意以下几个问题:
- 创建表时,字段顺序、字段类型要和文件中保持一致
- 如果类型不一致,hive会尝试转换,但时不保证转换成功。不成功显示null
- 文件好像要放置在Hive表对应的HDFS目录,值得探讨
- 建表时好像要根据文件内容指定分隔符,值得探讨
上述问题都是Hive的各个知识点,有待于我们接下来不断深入学习
使用Hive进行小数据分析
- Hive底层的确是通过MapReduce执行引擎来处理数据的
- 执行完一个MapReduce程序需要的时间不短
- 如果是小数据集,使用hive进行分析将得不偿失,延迟很高
- 如果是大数据集,使用hive进行分析,底层MapReduce分布式计算很爽