概述
HDFS被设计用于存储大量的数据,被存储在HDFS中的各样的文件面临数据分析以挖掘其价值的挑战,HDFS上层现支持多种进行数据分析和处理的架构总结如下:
1. 基于传统的MR来进行数据的处理,由研发人员编程实现.Hadoop MapReduce为代表
2. 基于DAG[有向无环图]的作业调度模式,以Apache Tez、Oozie技术为代表
3. 基于DAG[有向无环图]偏向于内存调度且高度封装的调度模式,以Spark为代表
4. 其它间接使用HDFS存储结构化数据的上层架构,如HBASE
[这里不讨论流数据处理]
Hive被设计为基于MR、或DAG[新版支持Tgz]等定义在HDFS上的计算框架来完成大量数据的分析、存储操作。
环境
ZK:host101,host102,host103
Hadoop:host102[主],host103[备],host104,host105,host106
Hive:host106
[需要先安装Hadoop环境且配置HADOOP_HOME环境变量]
安装
1. 下载,建议下载官方推荐的稳定版本,这里以支持Hadoop2.x的版本为例
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/stable-2/apache-hive-2.1.1-src.tar.gz
2. 解压到 /app下

3. 进入/app/apache-hive-2.1.1-bin/conf目录执行
cp hive-default.xml.template hive-site.xml
4. 执行vi hive-site.xml 确认以下修改项
<!--元数据仓库目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/data/hive/warehouse</value>
<description>location of defaultdatabase for the warehouse</description>
</property>
<property>
<name>system:user.name</name>
<value>/hive</value>
</property>
<!-- 缓存目录 -->
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp</value>
</property>
<!-- mysql 连接地址 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.100:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate theconnection, provide database-specific SSL flag in the connection URL.
For example,jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<!-- 驱动类 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for aJDBC metastore</description>
</property>
<!-- mysql 用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use againstmetastore database</description>
</property>
<!-- mysql 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use againstmetastore database</description>
</property>
5. 确认/tmp /data/hive/warehouse存在且hive执行用户拥有写权限 [这里指的是HDFS中的路径]
6. 拷贝mysql驱动类到hive类路径下/app/apache-hive-2.1.1-bin/lib
7. 在MySql中初始化Hive 元数据表,bin 目录下执行,这里需要确认当前主机可以访问到MySql数据库!!
./schematool -dbTypemysql -initSchema
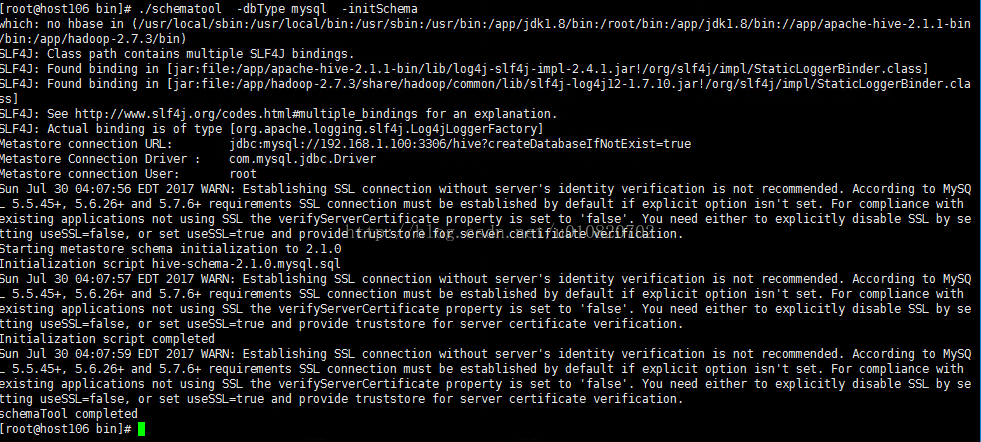
8. 至此Hive安装完毕。
Hive Shell
截至目前Hive有””Hive CLI”、” Beeline” 两种Shell,前者已经被废弃,推荐使用后者
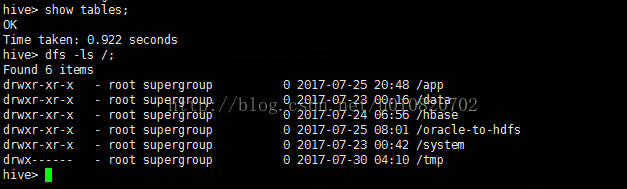
1. Hive CLI示例 执行./hive 查看表,查看HDFS文件。
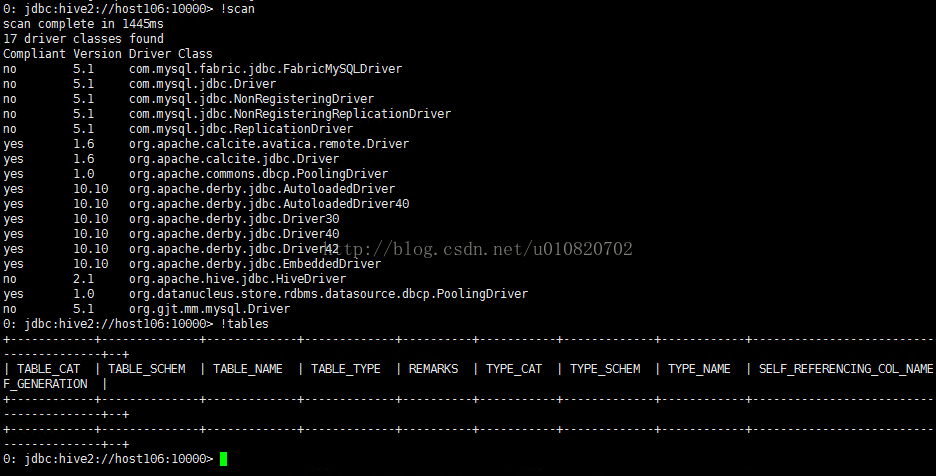
2. Beeline示例,执行 ./hiveserver2 启动hive server ,执行 ./beeline -u jdbc:hive2:// 连接到本地HiveServer,默认主机为localhost端口看为10000 相当于执行
./beeline -ujdbc:hive2://host106:10000 扫描以安装驱动,查看以创建表
示例
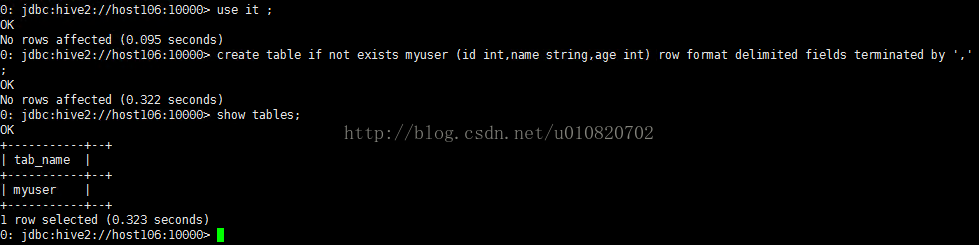
1. 创建数据库执行, create database if not exists it;

2. 创建表在上一部创建的it数据库中创建表myuser,申明使用,作为列分割符
create table if not exists myuser (id int,name string,ageint) row format delimited fields terminated by ',';
3. 从HDFS中装载数据
数据格式如下:
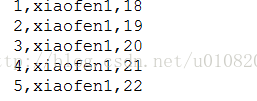
执行一下命令加载数据, 报错 .原因在连接HiveServer时没有指定用户和密码,Hive默认使用匿名用户操作HDFS引起权限异常.
load data inpath '/data/myuser.txt' overwrite into table myuser;

重新登录,指定HDFS用户名和密码
./beeline -u jdbc:hive2://host106:10000 -n root -p root
重新加载数据

4. 查询所有数据,查询年龄大于20的数据
select * from myuser;
select * from myuser where age >20;

5. 按id倒序输出
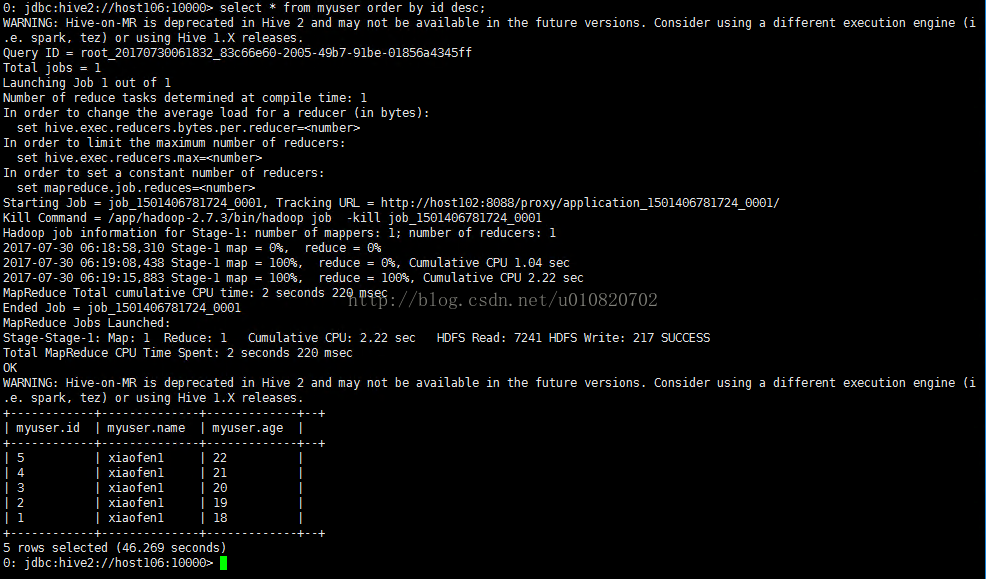
select * from myuser order by id desc; 排序操作出发了MR操作.

总结
基于HDFS构建数据仓库,将文件数据以SQL的形式提供给终端用户使用,任务最终以MR或者性能更好的DAG计算模型来实现。