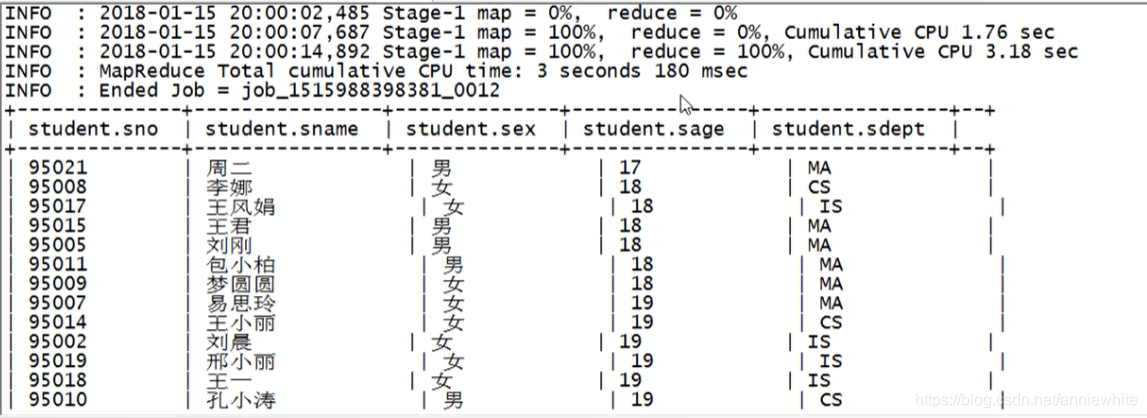
Select
基本的Select操作
语法结构:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
JOIN table_other ON expr
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY|ORDER BY col_list]]
[LIMIT number]
说明:
1、order by会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.task2>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定字段将数据分到不同的reducer,分发算法是hash散列。
4、cluster by(字段)除了具有Distribute by的功能外,还会对该字段进行排序。
如果distribute和sort的字段是同一个时,此时,cluster by=distribute by+sort by
分桶、排序等查询
cluster by、sort by、distribute by
select * from student cluster by(Sno);
insert overwrite table student_buck
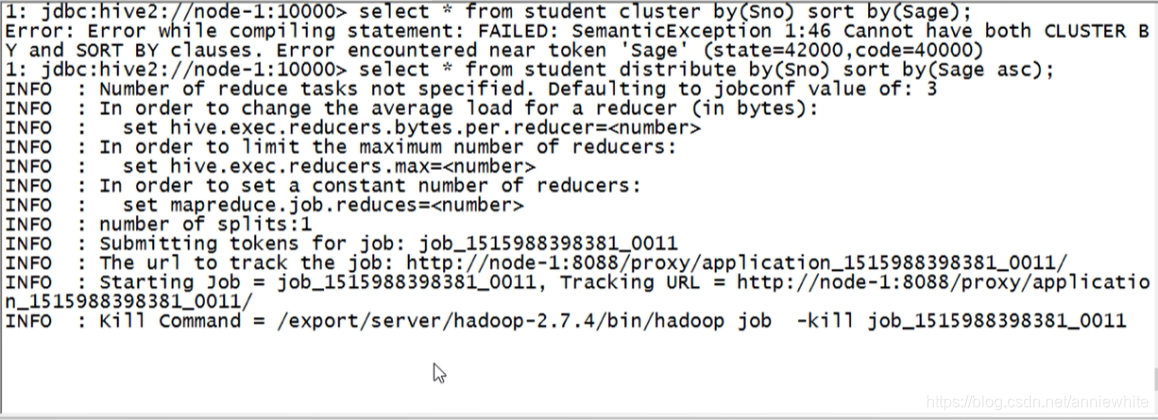
select * from student cluster by(Sno) sort by(Sage); 报错cluster和sort不能共存
对某列进行分桶的同时,根据玲一行进行排序
insert overwrite table stu_buck
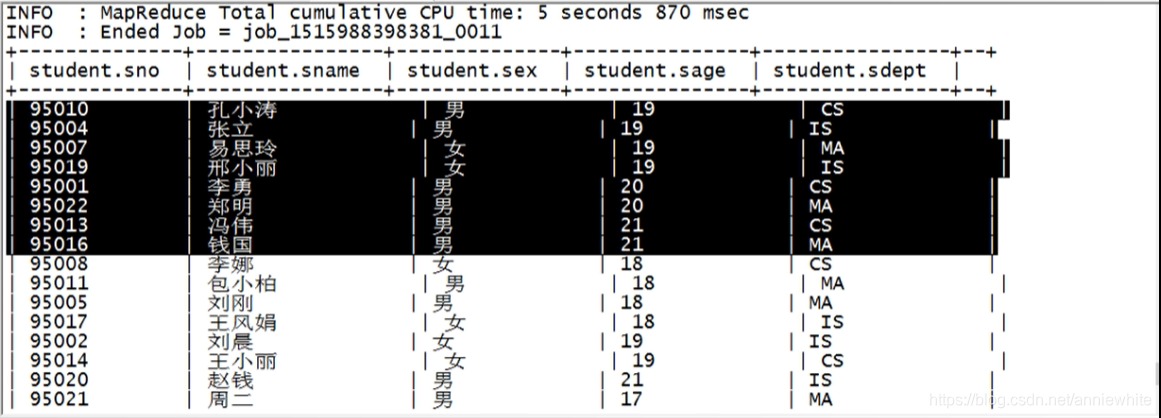
select * from student distribute by(Sno) sort by(Sage asc);
总结:
cluster(分且排序,必须一样)==distribute(分)+sort(排序)(可以不一样)
set mapredece.job.reduces;
查看当前分桶情况
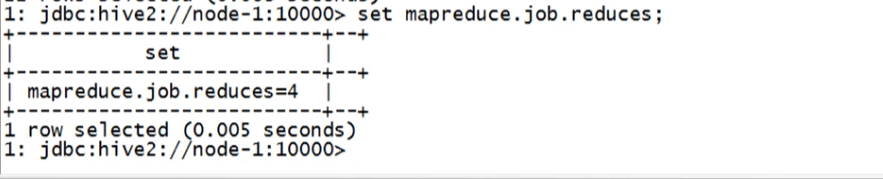
set mapredece.job.reduces=3;
改变分桶为3,修改后查询当前分桶情况,查询结果为3
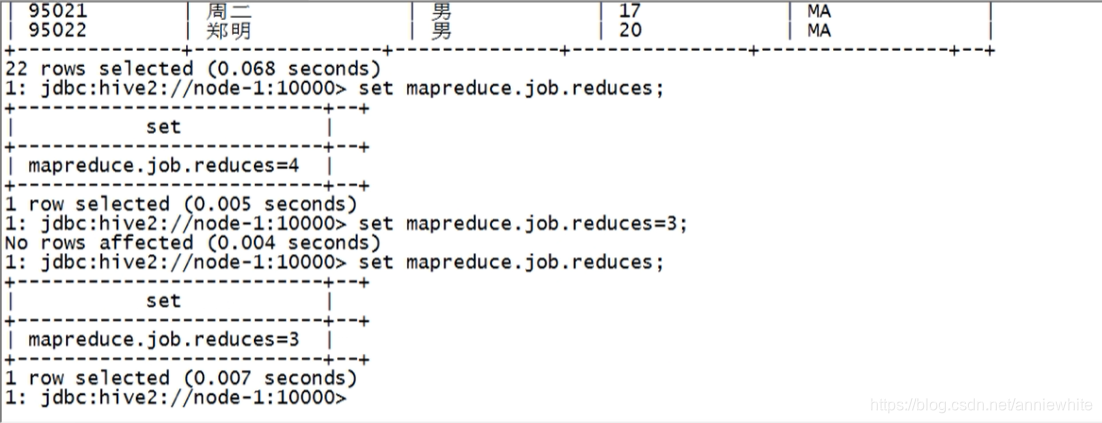
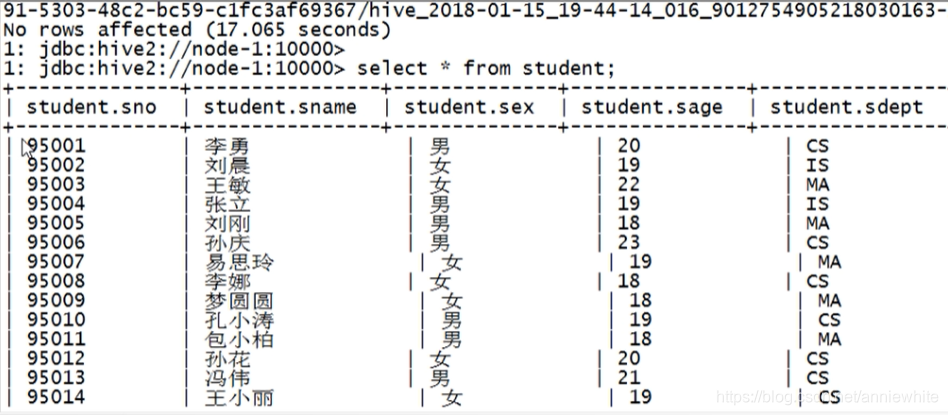
select * from student cluster by(Sno);
没有立即返回结果,执行mr程序中
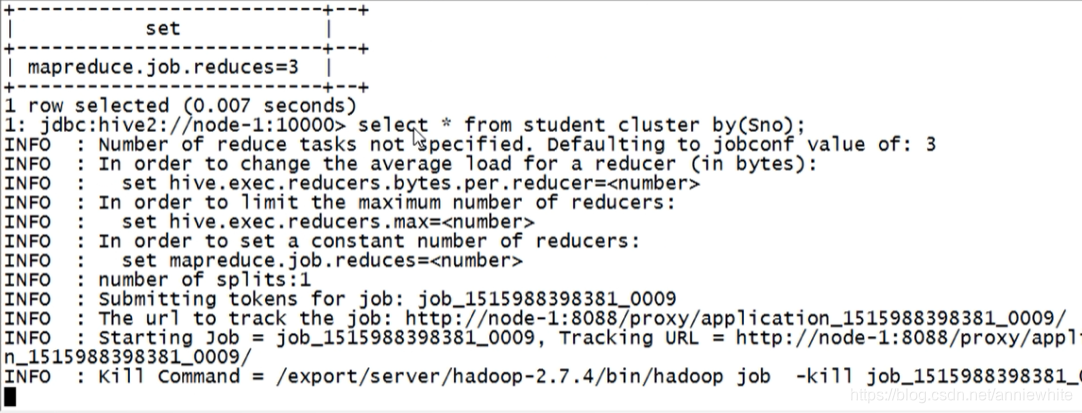
查看执行结果,分桶情况,分为了3桶,会根据Sno字段进行正序的排序:
- 一桶:95001、95004、95007、95010、95013、95016、95019、95022
- 一桶:95002、95005、95008、95011、95014、95017、95020
- 一桶:95003、95006、95009、95012、95015、95018、95021

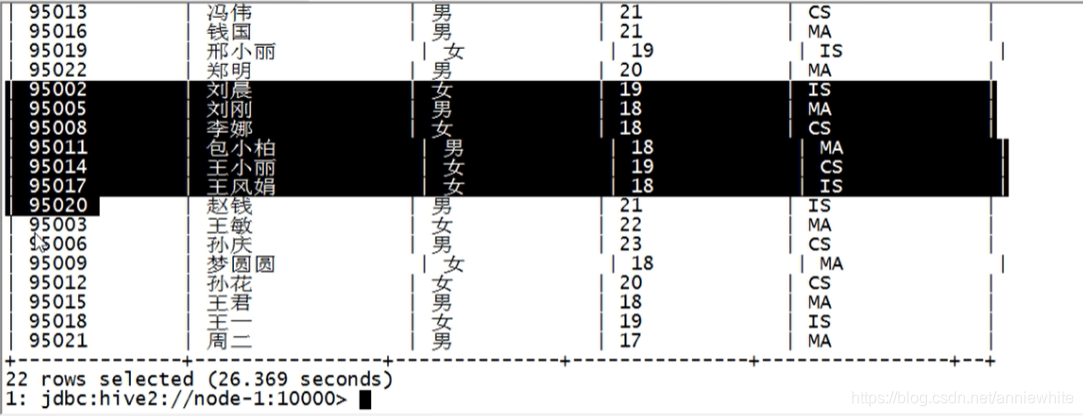
insert overwrite **local** directory '/root/aaa777'
select * from student cluster by(Sno);
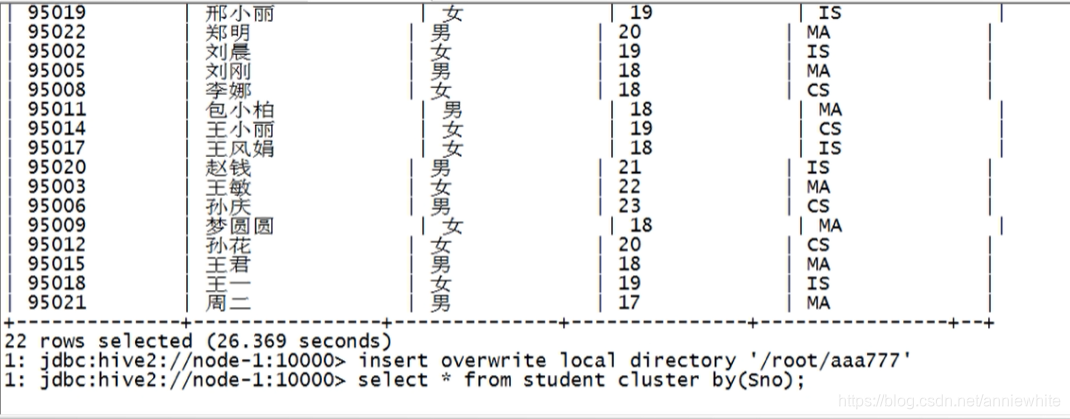
执行完毕。
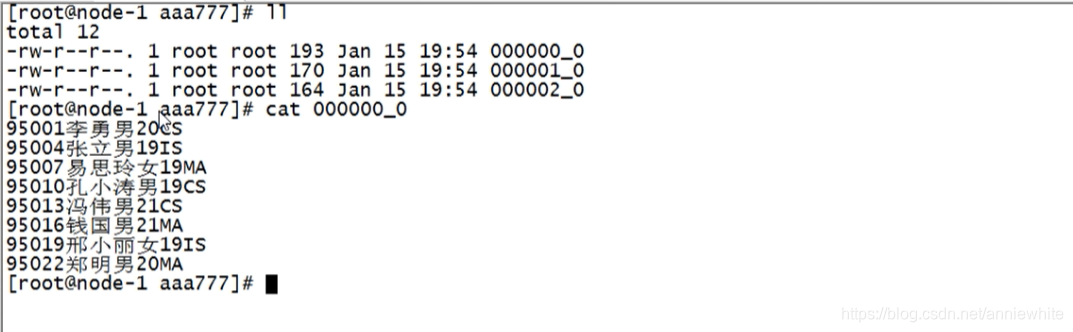
通过命令cd /aaa777,进入aaa777文件夹下,用ll命令看下查询结果,分为三桶,导出了3个文件。

查看第一个文件,都是第一桶的数据。
根据Sno学号进行分桶,根据Sage年龄进行排序,会报错。cluster和sort不能共存。

可以用distribute by+sort by
可以看到执行结果,第一桶根据年龄做了排序了
order by,根据年龄进行全局排序。